 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysWorld: From Real Videos to World Models of Deformable Objects via Physics-Aware Demonstration Synthesis
Oct 24, 2025Interactive world models that simulate object dynamics are crucial for robotics, VR, and AR. However, it remains a significant challenge to learn physics-consistent dynamics models from limited real-world video data, especially for deformable objects with spatially-varying physical properties. To overcome the challenge of data scarcity, we propose PhysWorld, a novel framework that utilizes a simulator to synthesize physically plausible and diverse demonstrations to learn efficient world models. Specifically, we first construct a physics-consistent digital twin within MPM simulator via constitutive model selection and global-to-local optimization of physical properties. Subsequently, we apply part-aware perturbations to the physical properties and generate various motion patterns for the digital twin, synthesizing extensive and diverse demonstrations. Finally, using these demonstrations, we train a lightweight GNN-based world model that is embedded with physical properties. The real video can be used to further refine the physical properties. PhysWorld achieves accurate and fast future predictions for various deformable objects, and also generalizes well to novel interactions. Experiments show that PhysWorld has competitive performance while enabling inference speeds 47 times faster than the recent state-of-the-art method, i.e., PhysTwin.
Deep Context-Conditioned Anomaly Detection for Tabular Data
Sep 10, 2025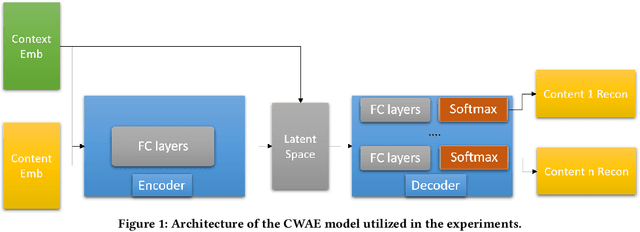
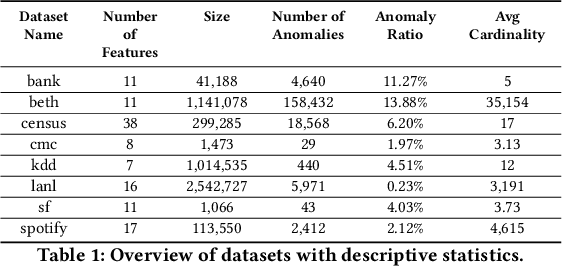
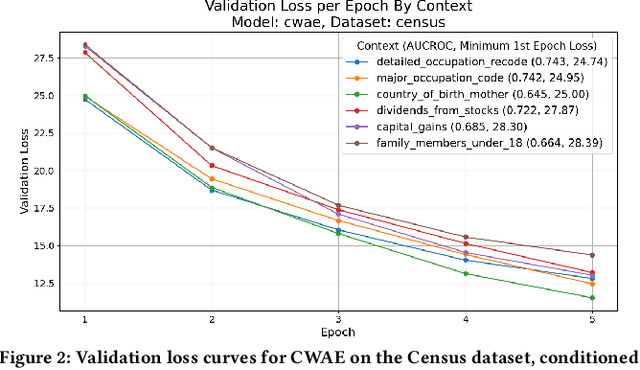
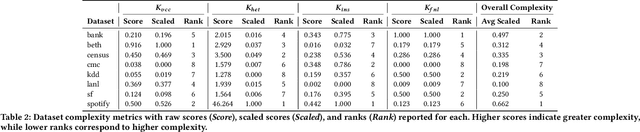
Anomaly detection is critical in domains such as cybersecurity and finance, especially when working with large-scale tabular data. Yet, unsupervised anomaly detection -- where no labeled anomalies are available -- remains a significant challenge. Although various deep learning methods have been proposed to model a dataset's joint distribution, real-world tabular data often contain heterogeneous contexts (e.g., different users), making globally rare events normal under certain contexts. Consequently, relying on a single global distribution can overlook these contextual nuances, degrading detection performance. In this paper, we present a context-conditional anomaly detection framework tailored for tabular datasets. Our approach automatically identifies context features and models the conditional data distribution using a simple deep autoencoder. Extensive experiments on multiple tabular benchmark datasets demonstrate that our method outperforms state-of-the-art approaches, underscoring the importance of context in accurately distinguishing anomalous from normal instances.
MoCo: Motion-Consistent Human Video Generation via Structure-Appearance Decoupling
Aug 24, 2025Generating human videos with consistent motion from text prompts remains a significant challenge, particularly for whole-body or long-range motion. Existing video generation models prioritize appearance fidelity, resulting in unrealistic or physically implausible human movements with poor structural coherence. Additionally, most existing human video datasets primarily focus on facial or upper-body motions, or consist of vertically oriented dance videos, limiting the scope of corresponding generation methods to simple movements. To overcome these challenges, we propose MoCo, which decouples the process of human video generation into two components: structure generation and appearance generation. Specifically, our method first employs an efficient 3D structure generator to produce a human motion sequence from a text prompt. The remaining video appearance is then synthesized under the guidance of the generated structural sequence. To improve fine-grained control over sparse human structures, we introduce Human-Aware Dynamic Control modules and integrate dense tracking constraints during training. Furthermore, recognizing the limitations of existing datasets, we construct a large-scale whole-body human video dataset featuring complex and diverse motions. Extensive experiments demonstrate that MoCo outperforms existing approaches in generating realistic and structurally coherent human videos.
MDIQA: Unified Image Quality Assessment for Multi-dimensional Evaluation and Restoration
Aug 23, 2025



Recent advancements in image quality assessment (IQA), driven by sophisticated deep neural network designs, have significantly improved the ability to approach human perceptions. However, most existing methods are obsessed with fitting the overall score, neglecting the fact that humans typically evaluate image quality from different dimensions before arriving at an overall quality assessment. To overcome this problem, we propose a multi-dimensional image quality assessment (MDIQA) framework. Specifically, we model image quality across various perceptual dimensions, including five technical and four aesthetic dimensions, to capture the multifaceted nature of human visual perception within distinct branches. Each branch of our MDIQA is initially trained under the guidance of a separate dimension, and the respective features are then amalgamated to generate the final IQA score. Additionally, when the MDIQA model is ready, we can deploy it for a flexible training of image restoration (IR) models, enabling the restoration results to better align with varying user preferences through the adjustment of perceptual dimension weights. Extensive experiments demonstrate that our MDIQA achieves superior performance and can be effectively and flexibly applied to image restoration tasks. The code is available: https://github.com/YaoShunyu19/MDIQA.
SelfHVD: Self-Supervised Handheld Video Deblurring for Mobile Phones
Aug 12, 2025Shooting video with a handheld mobile phone, the most common photographic device, often results in blurry frames due to shaking hands and other instability factors. Although previous video deblurring methods have achieved impressive progress, they still struggle to perform satisfactorily on real-world handheld video due to the blur domain gap between training and testing data. To address the issue, we propose a self-supervised method for handheld video deblurring, which is driven by sharp clues in the video. First, to train the deblurring model, we extract the sharp clues from the video and take them as misalignment labels of neighboring blurry frames. Second, to improve the model's ability, we propose a novel Self-Enhanced Video Deblurring (SEVD) method to create higher-quality paired video data. Third, we propose a Self-Constrained Spatial Consistency Maintenance (SCSCM) method to regularize the model, preventing position shifts between the output and input frames. Moreover, we construct a synthetic and a real-world handheld video dataset for handheld video deblurring. Extensive experiments on these two and other common real-world datasets demonstrate that our method significantly outperforms existing self-supervised ones. The code and datasets are publicly available at https://github.com/cshonglei/SelfHVD.
Image Demoiréing Using Dual Camera Fusion on Mobile Phones
Jun 10, 2025When shooting electronic screens, moir\'e patterns usually appear in captured images, which seriously affects the image quality. Existing image demoir\'eing methods face great challenges in removing large and heavy moir\'e. To address the issue, we propose to utilize Dual Camera fusion for Image Demoir\'eing (DCID), \ie, using the ultra-wide-angle (UW) image to assist the moir\'e removal of wide-angle (W) image. This is inspired by two motivations: (1) the two lenses are commonly equipped with modern smartphones, (2) the UW image generally can provide normal colors and textures when moir\'e exists in the W image mainly due to their different focal lengths. In particular, we propose an efficient DCID method, where a lightweight UW image encoder is integrated into an existing demoir\'eing network and a fast two-stage image alignment manner is present. Moreover, we construct a large-scale real-world dataset with diverse mobile phones and monitors, containing about 9,000 samples. Experiments on the dataset show our method performs better than state-of-the-art methods. Code and dataset are available at https://github.com/Mrduckk/DCID.
Pseudo-Label Guided Real-World Image De-weathering: A Learning Framework with Imperfect Supervision
Apr 14, 2025
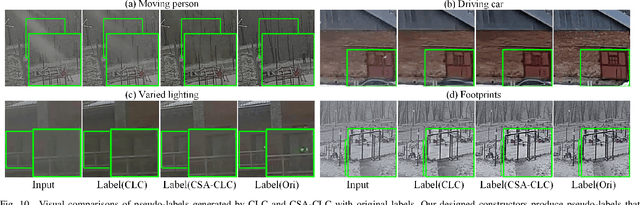

Real-world image de-weathering aims at removingvarious undesirable weather-related artifacts, e.g., rain, snow,and fog. To this end, acquiring ideal training pairs is crucial.Existing real-world datasets are typically constructed paired databy extracting clean and degraded images from live streamsof landscape scene on the Internet. Despite the use of strictfiltering mechanisms during collection, training pairs inevitablyencounter inconsistency in terms of lighting, object position, scenedetails, etc, making de-weathering models possibly suffer fromdeformation artifacts under non-ideal supervision. In this work,we propose a unified solution for real-world image de-weatheringwith non-ideal supervision, i.e., a pseudo-label guided learningframework, to address various inconsistencies within the realworld paired dataset. Generally, it consists of a de-weatheringmodel (De-W) and a Consistent Label Constructor (CLC), bywhich restoration result can be adaptively supervised by originalground-truth image to recover sharp textures while maintainingconsistency with the degraded inputs in non-weather contentthrough the supervision of pseudo-labels. Particularly, a Crossframe Similarity Aggregation (CSA) module is deployed withinCLC to enhance the quality of pseudo-labels by exploring thepotential complementary information of multi-frames throughgraph model. Moreover, we introduce an Information AllocationStrategy (IAS) to integrate the original ground-truth imagesand pseudo-labels, thereby facilitating the joint supervision forthe training of de-weathering model. Extensive experimentsdemonstrate that our method exhibits significant advantageswhen trained on imperfectly aligned de-weathering datasets incomparison with other approaches.
UniRestorer: Universal Image Restoration via Adaptively Estimating Image Degradation at Proper Granularity
Dec 28, 2024



Recently, considerable progress has been made in allin-one image restoration. Generally, existing methods can be degradation-agnostic or degradation-aware. However, the former are limited in leveraging degradation-specific restoration, and the latter suffer from the inevitable error in degradation estimation. Consequently, the performance of existing methods has a large gap compared to specific single-task models. In this work, we make a step forward in this topic, and present our UniRestorer with improved restoration performance. Specifically, we perform hierarchical clustering on degradation space, and train a multi-granularity mixture-of-experts (MoE) restoration model. Then, UniRestorer adopts both degradation and granularity estimation to adaptively select an appropriate expert for image restoration. In contrast to existing degradation-agnostic and -aware methods, UniRestorer can leverage degradation estimation to benefit degradationspecific restoration, and use granularity estimation to make the model robust to degradation estimation error. Experimental results show that our UniRestorer outperforms stateof-the-art all-in-one methods by a large margin, and is promising in closing the performance gap to specific single task models. The code and pre-trained models will be publicly available at https://github.com/mrluin/UniRestorer.
Deblur4DGS: 4D Gaussian Splatting from Blurry Monocular Video
Dec 09, 2024



Recent 4D reconstruction methods have yielded impressive results but rely on sharp videos as supervision. However, motion blur often occurs in videos due to camera shake and object movement, while existing methods render blurry results when using such videos for reconstructing 4D models. Although a few NeRF-based approaches attempted to address the problem, they struggled to produce high-quality results, due to the inaccuracy in estimating continuous dynamic representations within the exposure time. Encouraged by recent works in 3D motion trajectory modeling using 3D Gaussian Splatting (3DGS), we suggest taking 3DGS as the scene representation manner, and propose the first 4D Gaussian Splatting framework to reconstruct a high-quality 4D model from blurry monocular video, named Deblur4DGS. Specifically, we transform continuous dynamic representations estimation within an exposure time into the exposure time estimation. Moreover, we introduce exposure regularization to avoid trivial solutions, as well as multi-frame and multi-resolution consistency ones to alleviate artifacts. Furthermore, to better represent objects with large motion, we suggest blur-aware variable canonical Gaussians. Beyond novel-view synthesis, Deblur4DGS can be applied to improve blurry video from multiple perspectives, including deblurring, frame interpolation, and video stabilization. Extensive experiments on the above four tasks show that Deblur4DGS outperforms state-of-the-art 4D reconstruction methods. The codes are available at https://github.com/ZcsrenlongZ/Deblur4DGS.
MV-VTON: Multi-View Virtual Try-On with Diffusion Models
Apr 29, 2024The goal of image-based virtual try-on is to generate an image of the target person naturally wearing the given clothing. However, most existing methods solely focus on the frontal try-on using the frontal clothing. When the views of the clothing and person are significantly inconsistent, particularly when the person's view is non-frontal, the results are unsatisfactory. To address this challenge, we introduce Multi-View Virtual Try-ON (MV-VTON), which aims to reconstruct the dressing results of a person from multiple views using the given clothes. On the one hand, given that single-view clothes provide insufficient information for MV-VTON, we instead employ two images, i.e., the frontal and back views of the clothing, to encompass the complete view as much as possible. On the other hand, the diffusion models that have demonstrated superior abilities are adopted to perform our MV-VTON. In particular, we propose a view-adaptive selection method where hard-selection and soft-selection are applied to the global and local clothing feature extraction, respectively. This ensures that the clothing features are roughly fit to the person's view. Subsequently, we suggest a joint attention block to align and fuse clothing features with person features. Additionally, we collect a MV-VTON dataset, i.e., Multi-View Garment (MVG), in which each person has multiple photos with diverse views and poses. Experiments show that the proposed method not only achieves state-of-the-art results on MV-VTON task using our MVG dataset, but also has superiority on frontal-view virtual try-on task using VITON-HD and DressCode datasets. Codes and datasets will be publicly released at https://github.com/hywang2002/MV-VTON .