 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTBSN: Transformer-Based Blind-Spot Network for Self-Supervised Image Denoising
Paper and Code
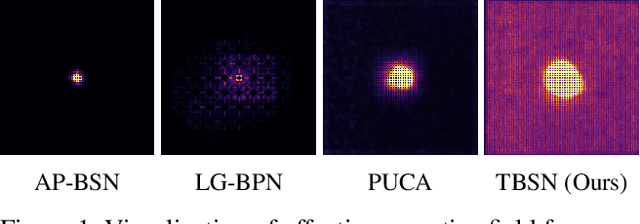
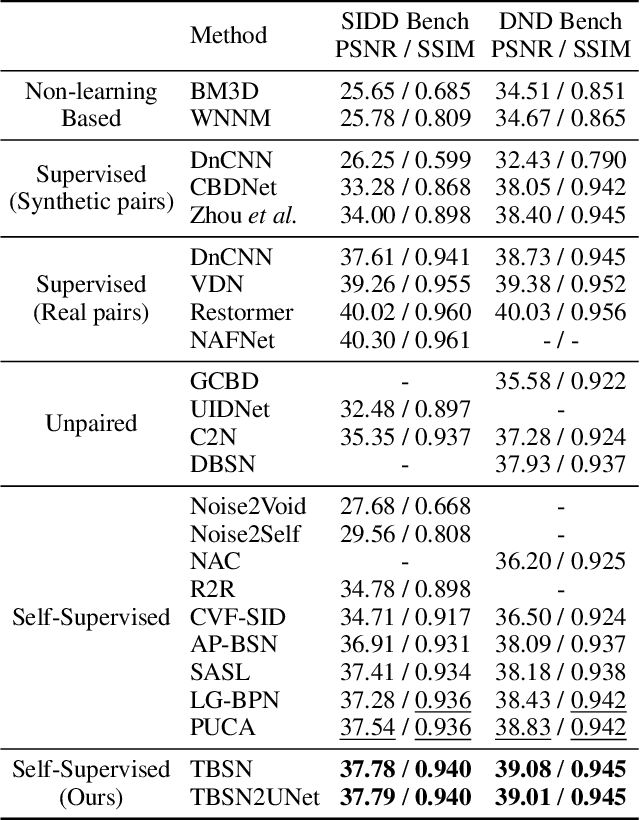
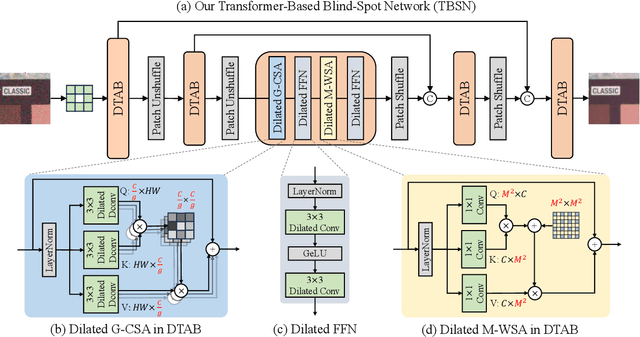

Blind-spot networks (BSN) have been prevalent network architectures in self-supervised image denoising (SSID). Existing BSNs are mostly conducted with convolution layers. Although transformers offer potential solutions to the limitations of convolutions and have demonstrated success in various image restoration tasks, their attention mechanisms may violate the blind-spot requirement, thus restricting their applicability in SSID. In this paper, we present a transformer-based blind-spot network (TBSN) by analyzing and redesigning the transformer operators that meet the blind-spot requirement. Specifically, TBSN follows the architectural principles of dilated BSNs, and incorporates spatial as well as channel self-attention layers to enhance the network capability. For spatial self-attention, an elaborate mask is applied to the attention matrix to restrict its receptive field, thus mimicking the dilated convolution. For channel self-attention, we observe that it may leak the blind-spot information when the channel number is greater than spatial size in the deep layers of multi-scale architectures. To eliminate this effect, we divide the channel into several groups and perform channel attention separately. Furthermore, we introduce a knowledge distillation strategy that distills TBSN into smaller denoisers to improve computational efficiency while maintaining performance. Extensive experiments on real-world image denoising datasets show that TBSN largely extends the receptive field and exhibits favorable performance against state-of-the-art SSID methods. The code and pre-trained models will be publicly available at https://github.com/nagejacob/TBSN.