 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking with Geometry: Active Geometry Integration for Spatial Reasoning
Feb 05, 2026Recent progress in spatial reasoning with Multimodal Large Language Models (MLLMs) increasingly leverages geometric priors from 3D encoders. However, most existing integration strategies remain passive: geometry is exposed as a global stream and fused in an indiscriminate manner, which often induces semantic-geometry misalignment and redundant signals. We propose GeoThinker, a framework that shifts the paradigm from passive fusion to active perception. Instead of feature mixing, GeoThinker enables the model to selectively retrieve geometric evidence conditioned on its internal reasoning demands. GeoThinker achieves this through Spatial-Grounded Fusion applied at carefully selected VLM layers, where semantic visual priors selectively query and integrate task-relevant geometry via frame-strict cross-attention, further calibrated by Importance Gating that biases per-frame attention toward task-relevant structures. Comprehensive evaluation results show that GeoThinker sets a new state-of-the-art in spatial intelligence, achieving a peak score of 72.6 on the VSI-Bench. Furthermore, GeoThinker demonstrates robust generalization and significantly improved spatial perception across complex downstream scenarios, including embodied referring and autonomous driving. Our results indicate that the ability to actively integrate spatial structures is essential for next-generation spatial intelligence. Code can be found at https://github.com/Li-Hao-yuan/GeoThinker.
SlowFocus: Enhancing Fine-grained Temporal Understanding in Video LLM
Feb 03, 2026Large language models (LLMs) have demonstrated exceptional capabilities in text understanding, which has paved the way for their expansion into video LLMs (Vid-LLMs) to analyze video data. However, current Vid-LLMs struggle to simultaneously retain high-quality frame-level semantic information (i.e., a sufficient number of tokens per frame) and comprehensive video-level temporal information (i.e., an adequate number of sampled frames per video). This limitation hinders the advancement of Vid-LLMs towards fine-grained video understanding. To address this issue, we introduce the SlowFocus mechanism, which significantly enhances the equivalent sampling frequency without compromising the quality of frame-level visual tokens. SlowFocus begins by identifying the query-related temporal segment based on the posed question, then performs dense sampling on this segment to extract local high-frequency features. A multi-frequency mixing attention module is further leveraged to aggregate these local high-frequency details with global low-frequency contexts for enhanced temporal comprehension. Additionally, to tailor Vid-LLMs to this innovative mechanism, we introduce a set of training strategies aimed at bolstering both temporal grounding and detailed temporal reasoning capabilities. Furthermore, we establish FineAction-CGR, a benchmark specifically devised to assess the ability of Vid-LLMs to process fine-grained temporal understanding tasks. Comprehensive experiments demonstrate the superiority of our mechanism across both existing public video understanding benchmarks and our proposed FineAction-CGR.
PandaPose: 3D Human Pose Lifting from a Single Image via Propagating 2D Pose Prior to 3D Anchor Space
Feb 01, 20263D human pose lifting from a single RGB image is a challenging task in 3D vision. Existing methods typically establish a direct joint-to-joint mapping from 2D to 3D poses based on 2D features. This formulation suffers from two fundamental limitations: inevitable error propagation from input predicted 2D pose to 3D predictions and inherent difficulties in handling self-occlusion cases. In this paper, we propose PandaPose, a 3D human pose lifting approach via propagating 2D pose prior to 3D anchor space as the unified intermediate representation. Specifically, our 3D anchor space comprises: (1) Joint-wise 3D anchors in the canonical coordinate system, providing accurate and robust priors to mitigate 2D pose estimation inaccuracies. (2) Depth-aware joint-wise feature lifting that hierarchically integrates depth information to resolve self-occlusion ambiguities. (3) The anchor-feature interaction decoder that incorporates 3D anchors with lifted features to generate unified anchor queries encapsulating joint-wise 3D anchor set, visual cues and geometric depth information. The anchor queries are further employed to facilitate anchor-to-joint ensemble prediction. Experiments on three well-established benchmarks (i.e., Human3.6M, MPI-INF-3DHP and 3DPW) demonstrate the superiority of our proposition. The substantial reduction in error by $14.7\%$ compared to SOTA methods on the challenging conditions of Human3.6M and qualitative comparisons further showcase the effectiveness and robustness of our approach.
kNN-Graph: An adaptive graph model for $k$-nearest neighbors
Jan 23, 2026The k-nearest neighbors (kNN) algorithm is a cornerstone of non-parametric classification in artificial intelligence, yet its deployment in large-scale applications is persistently constrained by the computational trade-off between inference speed and accuracy. Existing approximate nearest neighbor solutions accelerate retrieval but often degrade classification precision and lack adaptability in selecting the optimal neighborhood size (k). Here, we present an adaptive graph model that decouples inference latency from computational complexity. By integrating a Hierarchical Navigable Small World (HNSW) graph with a pre-computed voting mechanism, our framework completely transfers the computational burden of neighbor selection and weighting to the training phase. Within this topological structure, higher graph layers enable rapid navigation, while lower layers encode precise, node-specific decision boundaries with adaptive neighbor counts. Benchmarking against eight state-of-the-art baselines across six diverse datasets, we demonstrate that this architecture significantly accelerates inference speeds, achieving real-time performance, without compromising classification accuracy. These findings offer a scalable, robust solution to the long-standing inference bottleneck of kNN, establishing a new structural paradigm for graph-based nonparametric learning.
BiKC+: Bimanual Hierarchical Imitation with Keypose-Conditioned Coordination-Aware Consistency Policies
Jan 17, 2026Robots are essential in industrial manufacturing due to their reliability and efficiency. They excel in performing simple and repetitive unimanual tasks but still face challenges with bimanual manipulation. This difficulty arises from the complexities of coordinating dual arms and handling multi-stage processes. Recent integration of generative models into imitation learning (IL) has made progress in tackling specific challenges. However, few approaches explicitly consider the multi-stage nature of bimanual tasks while also emphasizing the importance of inference speed. In multi-stage tasks, failures or delays at any stage can cascade over time, impacting the success and efficiency of subsequent sub-stages and ultimately hindering overall task performance. In this paper, we propose a novel keypose-conditioned coordination-aware consistency policy tailored for bimanual manipulation. Our framework instantiates hierarchical imitation learning with a high-level keypose predictor and a low-level trajectory generator. The predicted keyposes serve as sub-goals for trajectory generation, indicating targets for individual sub-stages. The trajectory generator is formulated as a consistency model, generating action sequences based on historical observations and predicted keyposes in a single inference step. In particular, we devise an innovative approach for identifying bimanual keyposes, considering both robot-centric action features and task-centric operation styles. Simulation and real-world experiments illustrate that our approach significantly outperforms baseline methods in terms of success rates and operational efficiency. Implementation codes can be found at https://github.com/JoanaHXU/BiKC-plus.
Incorporating rank-free coupling and external field via an amplitude-only modulated spatial photonic Ising machine
Dec 25, 2025


Ising machines have emerged as effective solvers for combinatorial optimization problems, such as NP-hard problems, machine learning, and financial modeling. Recent spatial photonic Ising machines (SPIMs) excel in multi-node optimization and spin glass simulations, leveraging their large-scale and fully connected characteristics. However, existing laser diffraction-based SPIMs usually sacrifice time efficiency or spin count to encode high-rank spin-spin coupling and external fields, limiting their scalability for real-world applications. Here, we demonstrate an amplitude-only modulated rank-free spatial photonic Ising machine (AR-SPIM) with 200 iterations per second. By re-formulating an arbitrary Ising Hamiltonian as the sum of Hadamard products, followed by loading the corresponding matrices/vectors onto an aligned amplitude spatial light modulator and digital micro-mirrors device, we directly map a 797-spin Ising model with external fields (nearly 9-bit precision, -255 to 255) into an incoherent light field, eliminating the need for repeated and auxiliary operations. Serving as encoding accuracy metrics, the linear coefficient of determination and Pearson correlation coefficient between measured light intensities and Ising Hamiltonians exceed 0.9800, with values exceed 0.9997 globally. The AR-SPIM achieves less than 0.3% error rate for ground-state search of biased Max-cut problems with arbitrary ranks and weights, enables complex phase transition observations, and facilitates scalable spin counts for sparse Ising problems via removing zero-valued Hadamard product terms. This reconfigurable AR-SPIM can be further developed to support large-scale machine-learning training and deployed for practical applications in discrete optimization and quantum many-body simulations.
MaskFocus: Focusing Policy Optimization on Critical Steps for Masked Image Generation
Dec 21, 2025Reinforcement learning (RL) has demonstrated significant potential for post-training language models and autoregressive visual generative models, but adapting RL to masked generative models remains challenging. The core factor is that policy optimization requires accounting for the probability likelihood of each step due to its multi-step and iterative refinement process. This reliance on entire sampling trajectories introduces high computational cost, whereas natively optimizing random steps often yields suboptimal results. In this paper, we present MaskFocus, a novel RL framework that achieves effective policy optimization for masked generative models by focusing on critical steps. Specifically, we determine the step-level information gain by measuring the similarity between the intermediate images at each sampling step and the final generated image. Crucially, we leverage this to identify the most critical and valuable steps and execute focused policy optimization on them. Furthermore, we design a dynamic routing sampling mechanism based on entropy to encourage the model to explore more valuable masking strategies for samples with low entropy. Extensive experiments on multiple Text-to-Image benchmarks validate the effectiveness of our method.
Deep (Predictive) Discounted Counterfactual Regret Minimization
Nov 11, 2025Counterfactual regret minimization (CFR) is a family of algorithms for effectively solving imperfect-information games. To enhance CFR's applicability in large games, researchers use neural networks to approximate its behavior. However, existing methods are mainly based on vanilla CFR and struggle to effectively integrate more advanced CFR variants. In this work, we propose an efficient model-free neural CFR algorithm, overcoming the limitations of existing methods in approximating advanced CFR variants. At each iteration, it collects variance-reduced sampled advantages based on a value network, fits cumulative advantages by bootstrapping, and applies discounting and clipping operations to simulate the update mechanisms of advanced CFR variants. Experimental results show that, compared with model-free neural algorithms, it exhibits faster convergence in typical imperfect-information games and demonstrates stronger adversarial performance in a large poker game.
Towards Proprioception-Aware Embodied Planning for Dual-Arm Humanoid Robots
Oct 09, 2025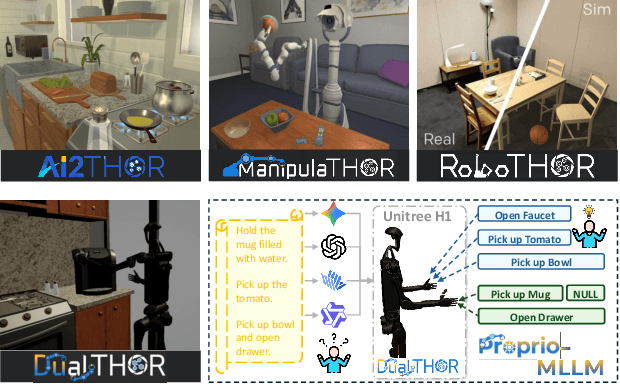


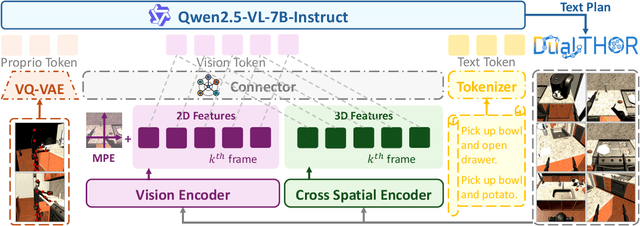
In recent years, Multimodal Large Language Models (MLLMs) have demonstrated the ability to serve as high-level planners, enabling robots to follow complex human instructions. However, their effectiveness, especially in long-horizon tasks involving dual-arm humanoid robots, remains limited. This limitation arises from two main challenges: (i) the absence of simulation platforms that systematically support task evaluation and data collection for humanoid robots, and (ii) the insufficient embodiment awareness of current MLLMs, which hinders reasoning about dual-arm selection logic and body positions during planning. To address these issues, we present DualTHOR, a new dual-arm humanoid simulator, with continuous transition and a contingency mechanism. Building on this platform, we propose Proprio-MLLM, a model that enhances embodiment awareness by incorporating proprioceptive information with motion-based position embedding and a cross-spatial encoder. Experiments show that, while existing MLLMs struggle in this environment, Proprio-MLLM achieves an average improvement of 19.75% in planning performance. Our work provides both an essential simulation platform and an effective model to advance embodied intelligence in humanoid robotics. The code is available at https://anonymous.4open.science/r/DualTHOR-5F3B.
Aligning Perception, Reasoning, Modeling and Interaction: A Survey on Physical AI
Oct 06, 2025
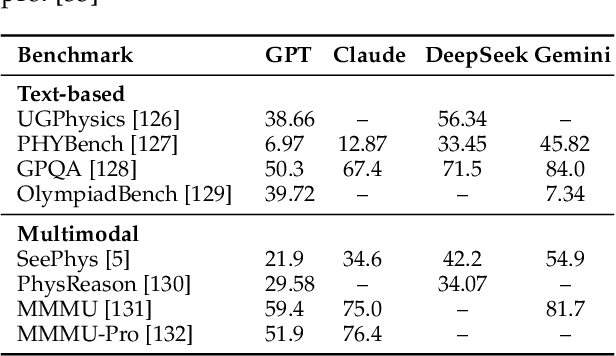

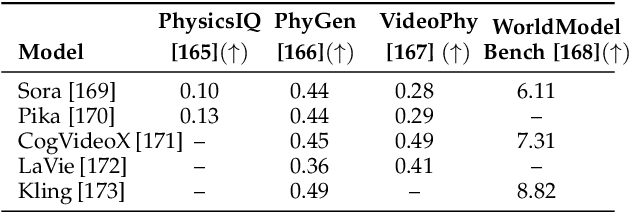
The rapid advancement of embodied intelligence and world models has intensified efforts to integrate physical laws into AI systems, yet physical perception and symbolic physics reasoning have developed along separate trajectories without a unified bridging framework. This work provides a comprehensive overview of physical AI, establishing clear distinctions between theoretical physics reasoning and applied physical understanding while systematically examining how physics-grounded methods enhance AI's real-world comprehension across structured symbolic reasoning, embodied systems, and generative models. Through rigorous analysis of recent advances, we advocate for intelligent systems that ground learning in both physical principles and embodied reasoning processes, transcending pattern recognition toward genuine understanding of physical laws. Our synthesis envisions next-generation world models capable of explaining physical phenomena and predicting future states, advancing safe, generalizable, and interpretable AI systems. We maintain a continuously updated resource at https://github.com/AI4Phys/Awesome-AI-for-Physics.