 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Flatland to Space: Teaching Vision-Language Models to Perceive and Reason in 3D
Mar 29, 2025
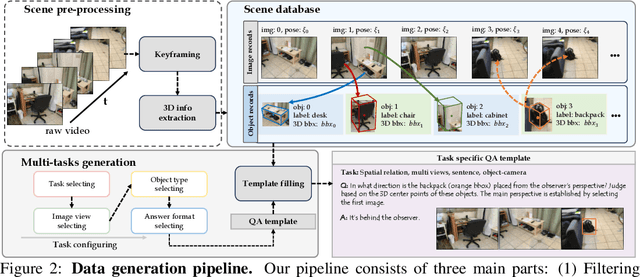
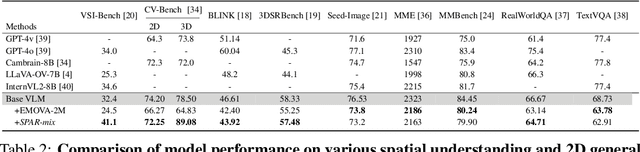

Recent advances in LVLMs have improved vision-language understanding, but they still struggle with spatial perception, limiting their ability to reason about complex 3D scenes. Unlike previous approaches that incorporate 3D representations into models to improve spatial understanding, we aim to unlock the potential of VLMs by leveraging spatially relevant image data. To this end, we introduce a novel 2D spatial data generation and annotation pipeline built upon scene data with 3D ground-truth. This pipeline enables the creation of a diverse set of spatial tasks, ranging from basic perception tasks to more complex reasoning tasks. Leveraging this pipeline, we construct SPAR-7M, a large-scale dataset generated from thousands of scenes across multiple public datasets. In addition, we introduce SPAR-Bench, a benchmark designed to offer a more comprehensive evaluation of spatial capabilities compared to existing spatial benchmarks, supporting both single-view and multi-view inputs. Training on both SPAR-7M and large-scale 2D datasets enables our models to achieve state-of-the-art performance on 2D spatial benchmarks. Further fine-tuning on 3D task-specific datasets yields competitive results, underscoring the effectiveness of our dataset in enhancing spatial reasoning.
Neural Scoring, Not Embedding: A Novel Framework for Robust Speaker Verification
Oct 21, 2024


Current mainstream speaker verification systems are predominantly based on the concept of ``speaker embedding", which transforms variable-length speech signals into fixed-length speaker vectors, followed by verification based on cosine similarity between the embeddings of the enrollment and test utterances. However, this approach suffers from considerable performance degradation in the presence of severe noise and interference speakers. This paper introduces Neural Scoring, a novel framework that re-treats speaker verification as a scoring task using a Transformer-based architecture. The proposed method first extracts an embedding from the enrollment speech and frame-level features from the test speech. A Transformer network then generates a decision score that quantifies the likelihood of the enrolled speaker being present in the test speech. We evaluated Neural Scoring on the VoxCeleb dataset across five test scenarios, comparing it with the state-of-the-art embedding-based approach. While Neural Scoring achieves comparable performance to the state-of-the-art under the benchmark (clean) test condition, it demonstrates a remarkable advantage in the four complex scenarios, achieving an overall 64.53% reduction in equal error rate (EER) compared to the baseline.
Adversarial Data Augmentation for Robust Speaker Verification
Feb 05, 2024


Data augmentation (DA) has gained widespread popularity in deep speaker models due to its ease of implementation and significant effectiveness. It enriches training data by simulating real-life acoustic variations, enabling deep neural networks to learn speaker-related representations while disregarding irrelevant acoustic variations, thereby improving robustness and generalization. However, a potential issue with the vanilla DA is augmentation residual, i.e., unwanted distortion caused by different types of augmentation. To address this problem, this paper proposes a novel approach called adversarial data augmentation (A-DA) which combines DA with adversarial learning. Specifically, it involves an additional augmentation classifier to categorize various augmentation types used in data augmentation. This adversarial learning empowers the network to generate speaker embeddings that can deceive the augmentation classifier, making the learned speaker embeddings more robust in the face of augmentation variations. Experiments conducted on VoxCeleb and CN-Celeb datasets demonstrate that our proposed A-DA outperforms standard DA in both augmentation matched and mismatched test conditions, showcasing its superior robustness and generalization against acoustic variations.
An Investigation of Distribution Alignment in Multi-Genre Speaker Recognition
Sep 25, 2023


Multi-genre speaker recognition is becoming increasingly popular due to its ability to better represent the complexities of real-world applications. However, a major challenge is the significant shift in the distribution of speaker vectors across different genres. While distribution alignment is a common approach to address this challenge, previous studies have mainly focused on aligning a source domain with a target domain, and the performance of multi-genre data is unknown. This paper presents a comprehensive study of mainstream distribution alignment methods on multi-genre data, where multiple distributions need to be aligned. We analyze various methods both qualitatively and quantitatively. Our experiments on the CN-Celeb dataset show that within-between distribution alignment (WBDA) performs relatively better. However, we also found that none of the investigated methods consistently improved performance in all test cases. This suggests that solely aligning the distributions of speaker vectors may not fully address the challenges posed by multi-genre speaker recognition. Further investigation is necessary to develop a more comprehensive solution.
A Multi-Scale Attentive Transformer for Multi-Instrument Symbolic Music Generation
May 26, 2023



Recently, multi-instrument music generation has become a hot topic. Different from single-instrument generation, multi-instrument generation needs to consider inter-track harmony besides intra-track coherence. This is usually achieved by composing note segments from different instruments into a signal sequence. This composition could be on different scales, such as note, bar, or track. Most existing work focuses on a particular scale, leading to a shortage in modeling music with diverse temporal and track dependencies. This paper proposes a multi-scale attentive Transformer model to improve the quality of multi-instrument generation. We first employ multiple Transformer decoders to learn multi-instrument representations of different scales and then design an attentive mechanism to fuse the multi-scale information. Experiments conducted on SOD and LMD datasets show that our model improves both quantitative and qualitative performance compared to models based on single-scale information. The source code and some generated samples can be found at https://github.com/HaRry-qaq/MSAT.
Split Time Series into Patches: Rethinking Long-term Series Forecasting with Dateformer
Jul 12, 2022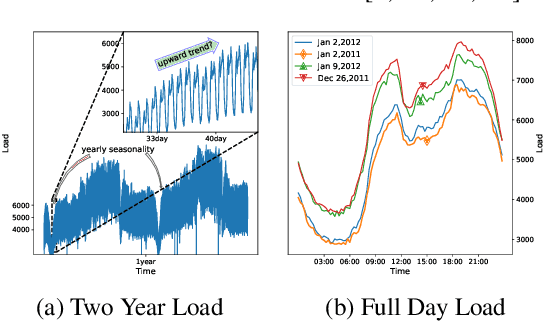
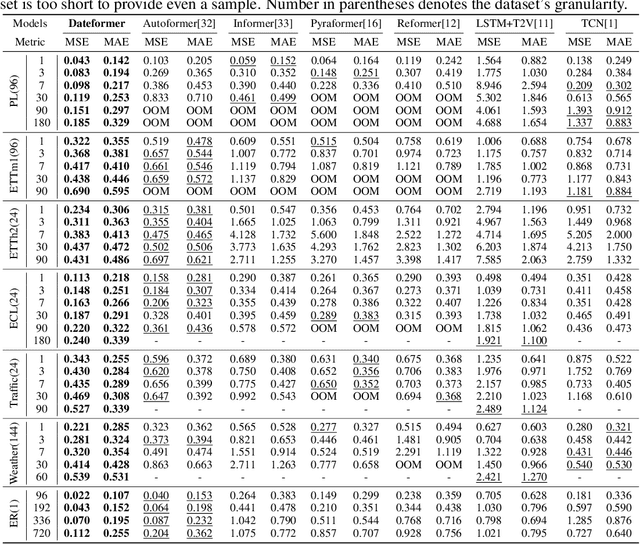
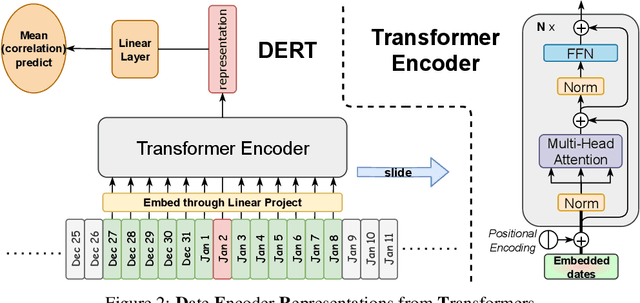
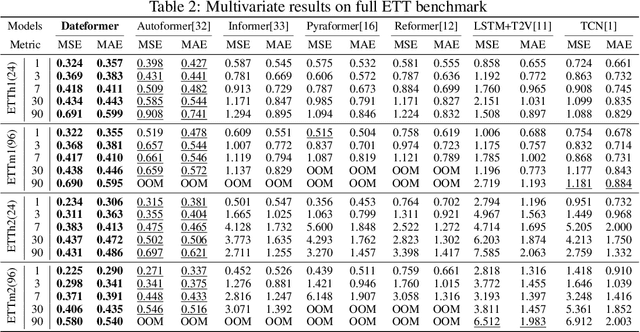
Time is one of the most significant characteristics of time-series, yet has received insufficient attention. Prior time-series forecasting research has mainly focused on mapping a past subseries (lookback window) to a future series (forecast window), and time of series often just play an auxiliary role even completely ignored in most cases. Due to the point-wise processing within these windows, extrapolating series to longer-term future is tough in the pattern. To overcome this barrier, we propose a brand-new time-series forecasting framework named Dateformer who turns attention to modeling time instead of following the above practice. Specifically, time-series are first split into patches by day to supervise the learning of dynamic date-representations with Date Encoder Representations from Transformers (DERT). These representations are then fed into a simple decoder to produce a coarser (or global) prediction, and used to help the model seek valuable information from the lookback window to learn a refined (or local) prediction. Dateformer obtains the final result by summing the above two parts. Our empirical studies on seven benchmarks show that the time-modeling method is more efficient for long-term series forecasting compared with sequence modeling methods. Dateformer yields state-of-the-art accuracy with a 40% remarkable relative improvement, and broadens the maximum credible forecasting range to a half-yearly level.