 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniVideo-100K: A Dataset for Audio-Visual Reasoning through Structured Scripts and Evidence Chains
Jun 12, 2026Current automated pipelines for audio-visual Question Answering (QA) generally adopt a ``video-caption-QA'' paradigm. However, these methods typically segment videos into short clips and generate separate descriptions for audio and visual modalities. This decoupled processing severs inherent associations between sounds and their visual sources, while independent clip processing often causes inconsistent descriptions of the same entity across segments. Furthermore, coupling long-text comprehension and QA synthesis into a single step often restricts models to localized events, yielding questions lacking long-term temporal connections and deep cross-modal reasoning. To address these issues, we propose an automated data engine featuring two mechanisms: (1) \textbf{Entity-Anchored Video Scripting} transforms videos into structured scripts, comprising summaries, main entity lists, and segment-wise audio-visual descriptions. The entity list serves as a global prior to ensure cross-segment referential consistency and reconstruct audio-visual associations. (2) \textbf{Clue-Guided QA Generation} prompts models to first mine cross-segment, multimodal clues from the script, and subsequently generate QA pairs based on these high-value clues. Leveraging this pipeline, we construct the instruction-tuning dataset \textbf{OmniVideo-100K} and a human-verified test set, \textbf{OmniVideo-Test}. Fine-tuning VITA-1.5, Qwen2.5-Omni-7B and Qwen3-Omni-30B on OmniVideo-100K yields performance gains of up to 20.59% on OmniVideo-Test, demonstrating strong generalization (up to 12.64% improvements) across established benchmarks like Daily-Omni and JointAVBench.
From Flatland to Space: Teaching Vision-Language Models to Perceive and Reason in 3D
Mar 29, 2025
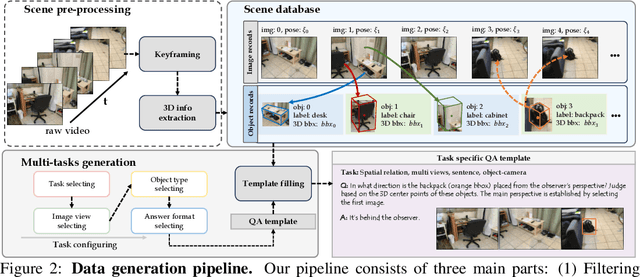
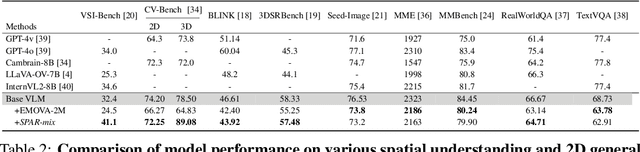

Recent advances in LVLMs have improved vision-language understanding, but they still struggle with spatial perception, limiting their ability to reason about complex 3D scenes. Unlike previous approaches that incorporate 3D representations into models to improve spatial understanding, we aim to unlock the potential of VLMs by leveraging spatially relevant image data. To this end, we introduce a novel 2D spatial data generation and annotation pipeline built upon scene data with 3D ground-truth. This pipeline enables the creation of a diverse set of spatial tasks, ranging from basic perception tasks to more complex reasoning tasks. Leveraging this pipeline, we construct SPAR-7M, a large-scale dataset generated from thousands of scenes across multiple public datasets. In addition, we introduce SPAR-Bench, a benchmark designed to offer a more comprehensive evaluation of spatial capabilities compared to existing spatial benchmarks, supporting both single-view and multi-view inputs. Training on both SPAR-7M and large-scale 2D datasets enables our models to achieve state-of-the-art performance on 2D spatial benchmarks. Further fine-tuning on 3D task-specific datasets yields competitive results, underscoring the effectiveness of our dataset in enhancing spatial reasoning.
TraDiffusion: Trajectory-Based Training-Free Image Generation
Aug 19, 2024



In this work, we propose a training-free, trajectory-based controllable T2I approach, termed TraDiffusion. This novel method allows users to effortlessly guide image generation via mouse trajectories. To achieve precise control, we design a distance awareness energy function to effectively guide latent variables, ensuring that the focus of generation is within the areas defined by the trajectory. The energy function encompasses a control function to draw the generation closer to the specified trajectory and a movement function to diminish activity in areas distant from the trajectory. Through extensive experiments and qualitative assessments on the COCO dataset, the results reveal that TraDiffusion facilitates simpler, more natural image control. Moreover, it showcases the ability to manipulate salient regions, attributes, and relationships within the generated images, alongside visual input based on arbitrary or enhanced trajectories.
ControlMLLM: Training-Free Visual Prompt Learning for Multimodal Large Language Models
Jul 31, 2024In this work, we propose a training-free method to inject visual referring into Multimodal Large Language Models (MLLMs) through learnable visual token optimization. We observe the relationship between text prompt tokens and visual tokens in MLLMs, where attention layers model the connection between them. Our approach involves adjusting visual tokens from the MLP output during inference, controlling which text prompt tokens attend to which visual tokens. We optimize a learnable visual token based on an energy function, enhancing the strength of referential regions in the attention map. This enables detailed region description and reasoning without the need for substantial training costs or model retraining. Our method offers a promising direction for integrating referential abilities into MLLMs. Our method support referring with box, mask, scribble and point. The results demonstrate that our method exhibits controllability and interpretability.
LaneCorrect: Self-supervised Lane Detection
Apr 23, 2024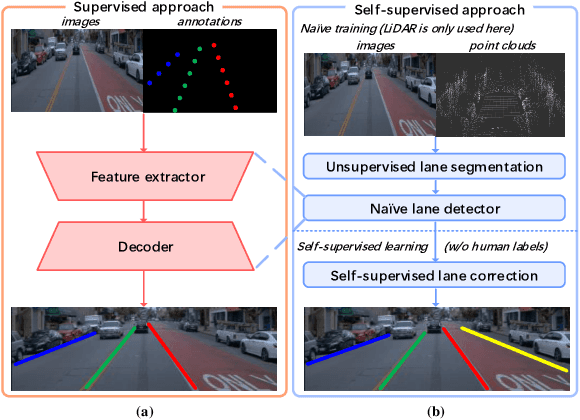



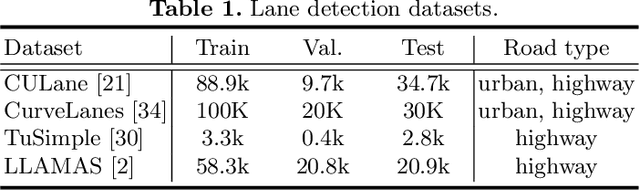
Lane detection has evolved highly functional autonomous driving system to understand driving scenes even under complex environments. In this paper, we work towards developing a generalized computer vision system able to detect lanes without using any annotation. We make the following contributions: (i) We illustrate how to perform unsupervised 3D lane segmentation by leveraging the distinctive intensity of lanes on the LiDAR point cloud frames, and then obtain the noisy lane labels in the 2D plane by projecting the 3D points; (ii) We propose a novel self-supervised training scheme, dubbed LaneCorrect, that automatically corrects the lane label by learning geometric consistency and instance awareness from the adversarial augmentations; (iii) With the self-supervised pre-trained model, we distill to train a student network for arbitrary target lane (e.g., TuSimple) detection without any human labels; (iv) We thoroughly evaluate our self-supervised method on four major lane detection benchmarks (including TuSimple, CULane, CurveLanes and LLAMAS) and demonstrate excellent performance compared with existing supervised counterpart, whilst showing more effective results on alleviating the domain gap, i.e., training on CULane and test on TuSimple.
Translating Images to Road Network:A Non-Autoregressive Sequence-to-Sequence Approach
Feb 13, 2024



The extraction of road network is essential for the generation of high-definition maps since it enables the precise localization of road landmarks and their interconnections. However, generating road network poses a significant challenge due to the conflicting underlying combination of Euclidean (e.g., road landmarks location) and non-Euclidean (e.g., road topological connectivity) structures. Existing methods struggle to merge the two types of data domains effectively, but few of them address it properly. Instead, our work establishes a unified representation of both types of data domain by projecting both Euclidean and non-Euclidean data into an integer series called RoadNet Sequence. Further than modeling an auto-regressive sequence-to-sequence Transformer model to understand RoadNet Sequence, we decouple the dependency of RoadNet Sequence into a mixture of auto-regressive and non-autoregressive dependency. Building on this, our proposed non-autoregressive sequence-to-sequence approach leverages non-autoregressive dependencies while fixing the gap towards auto-regressive dependencies, resulting in success on both efficiency and accuracy. Extensive experiments on nuScenes dataset demonstrate the superiority of RoadNet Sequence representation and the non-autoregressive approach compared to existing state-of-the-art alternatives. The code is open-source on https://github.com/fudan-zvg/RoadNetworkTRansformer.
LaneGraph2Seq: Lane Topology Extraction with Language Model via Vertex-Edge Encoding and Connectivity Enhancement
Jan 31, 2024Understanding road structures is crucial for autonomous driving. Intricate road structures are often depicted using lane graphs, which include centerline curves and connections forming a Directed Acyclic Graph (DAG). Accurate extraction of lane graphs relies on precisely estimating vertex and edge information within the DAG. Recent research highlights Transformer-based language models' impressive sequence prediction abilities, making them effective for learning graph representations when graph data are encoded as sequences. However, existing studies focus mainly on modeling vertices explicitly, leaving edge information simply embedded in the network. Consequently, these approaches fall short in the task of lane graph extraction. To address this, we introduce LaneGraph2Seq, a novel approach for lane graph extraction. It leverages a language model with vertex-edge encoding and connectivity enhancement. Our serialization strategy includes a vertex-centric depth-first traversal and a concise edge-based partition sequence. Additionally, we use classifier-free guidance combined with nucleus sampling to improve lane connectivity. We validate our method on prominent datasets, nuScenes and Argoverse 2, showcasing consistent and compelling results. Our LaneGraph2Seq approach demonstrates superior performance compared to state-of-the-art techniques in lane graph extraction.
Reason2Drive: Towards Interpretable and Chain-based Reasoning for Autonomous Driving
Dec 06, 2023Large vision-language models (VLMs) have garnered increasing interest in autonomous driving areas, due to their advanced capabilities in complex reasoning tasks essential for highly autonomous vehicle behavior. Despite their potential, research in autonomous systems is hindered by the lack of datasets with annotated reasoning chains that explain the decision-making processes in driving. To bridge this gap, we present Reason2Drive, a benchmark dataset with over 600K video-text pairs, aimed at facilitating the study of interpretable reasoning in complex driving environments. We distinctly characterize the autonomous driving process as a sequential combination of perception, prediction, and reasoning steps, and the question-answer pairs are automatically collected from a diverse range of open-source outdoor driving datasets, including nuScenes, Waymo and ONCE. Moreover, we introduce a novel aggregated evaluation metric to assess chain-based reasoning performance in autonomous systems, addressing the semantic ambiguities of existing metrics such as BLEU and CIDEr. Based on the proposed benchmark, we conduct experiments to assess various existing VLMs, revealing insights into their reasoning capabilities. Additionally, we develop an efficient approach to empower VLMs to leverage object-level perceptual elements in both feature extraction and prediction, further enhancing their reasoning accuracy. The code and dataset will be released.
RCLane: Relay Chain Prediction for Lane Detection
Jul 19, 2022
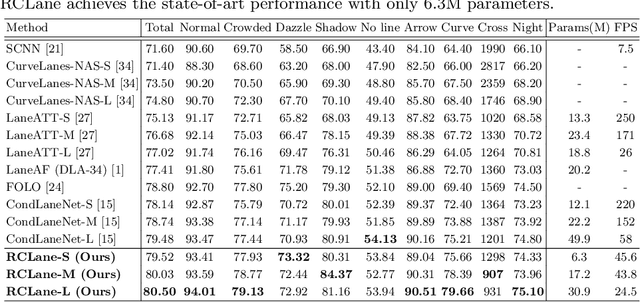
Lane detection is an important component of many real-world autonomous systems. Despite a wide variety of lane detection approaches have been proposed, reporting steady benchmark improvements over time, lane detection remains a largely unsolved problem. This is because most of the existing lane detection methods either treat the lane detection as a dense prediction or a detection task, few of them consider the unique topologies (Y-shape, Fork-shape, nearly horizontal lane) of the lane markers, which leads to sub-optimal solution. In this paper, we present a new method for lane detection based on relay chain prediction. Specifically, our model predicts a segmentation map to classify the foreground and background region. For each pixel point in the foreground region, we go through the forward branch and backward branch to recover the whole lane. Each branch decodes a transfer map and a distance map to produce the direction moving to the next point, and how many steps to progressively predict a relay station (next point). As such, our model is able to capture the keypoints along the lanes. Despite its simplicity, our strategy allows us to establish new state-of-the-art on four major benchmarks including TuSimple, CULane, CurveLanes and LLAMAS.
ONCE-3DLanes: Building Monocular 3D Lane Detection
May 14, 2022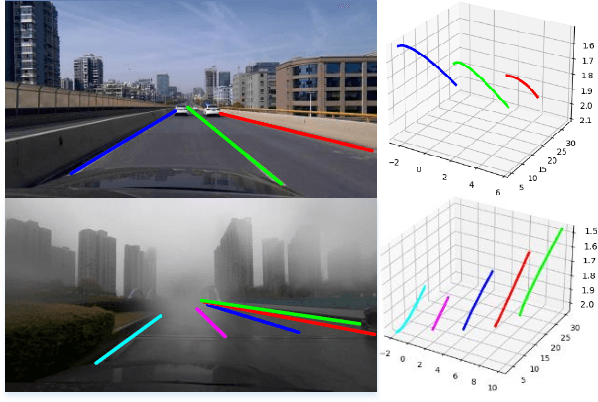
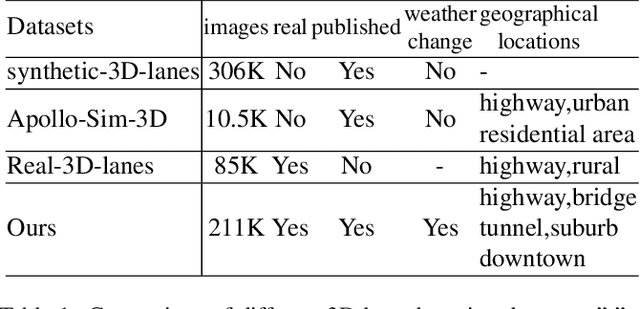
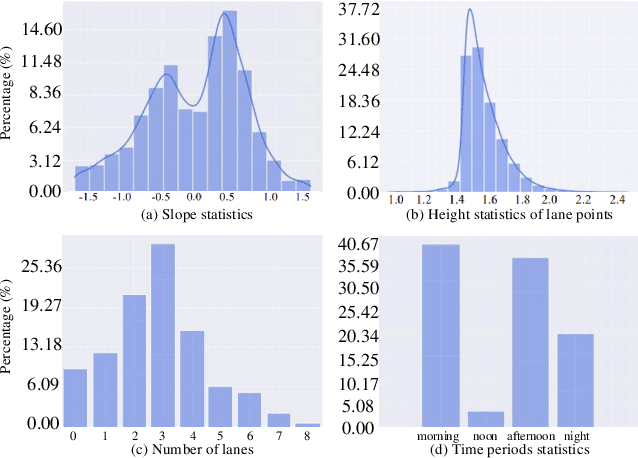
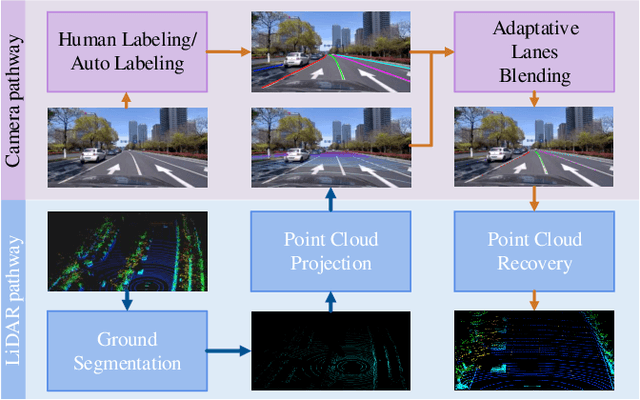
We present ONCE-3DLanes, a real-world autonomous driving dataset with lane layout annotation in 3D space. Conventional 2D lane detection from a monocular image yields poor performance of following planning and control tasks in autonomous driving due to the case of uneven road. Predicting the 3D lane layout is thus necessary and enables effective and safe driving. However, existing 3D lane detection datasets are either unpublished or synthesized from a simulated environment, severely hampering the development of this field. In this paper, we take steps towards addressing these issues. By exploiting the explicit relationship between point clouds and image pixels, a dataset annotation pipeline is designed to automatically generate high-quality 3D lane locations from 2D lane annotations in 211K road scenes. In addition, we present an extrinsic-free, anchor-free method, called SALAD, regressing the 3D coordinates of lanes in image view without converting the feature map into the bird's-eye view (BEV). To facilitate future research on 3D lane detection, we benchmark the dataset and provide a novel evaluation metric, performing extensive experiments of both existing approaches and our proposed method. The aim of our work is to revive the interest of 3D lane detection in a real-world scenario. We believe our work can lead to the expected and unexpected innovations in both academia and industry.