 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaneformer: Object-aware Row-Column Transformers for Lane Detection
Mar 18, 2022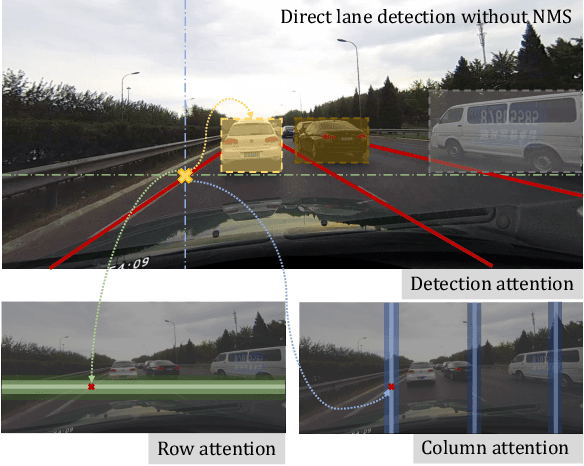
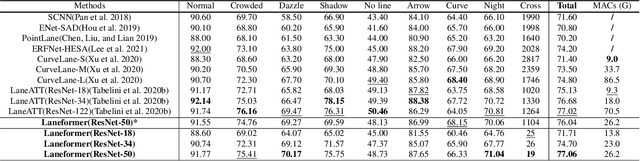

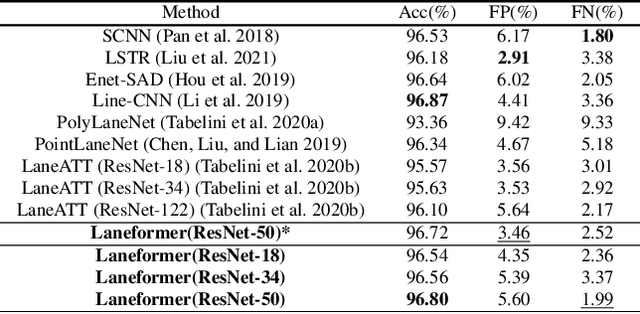
We present Laneformer, a conceptually simple yet powerful transformer-based architecture tailored for lane detection that is a long-standing research topic for visual perception in autonomous driving. The dominant paradigms rely on purely CNN-based architectures which often fail in incorporating relations of long-range lane points and global contexts induced by surrounding objects (e.g., pedestrians, vehicles). Inspired by recent advances of the transformer encoder-decoder architecture in various vision tasks, we move forwards to design a new end-to-end Laneformer architecture that revolutionizes the conventional transformers into better capturing the shape and semantic characteristics of lanes, with minimal overhead in latency. First, coupling with deformable pixel-wise self-attention in the encoder, Laneformer presents two new row and column self-attention operations to efficiently mine point context along with the lane shapes. Second, motivated by the appearing objects would affect the decision of predicting lane segments, Laneformer further includes the detected object instances as extra inputs of multi-head attention blocks in the encoder and decoder to facilitate the lane point detection by sensing semantic contexts. Specifically, the bounding box locations of objects are added into Key module to provide interaction with each pixel and query while the ROI-aligned features are inserted into Value module. Extensive experiments demonstrate our Laneformer achieves state-of-the-art performances on CULane benchmark, in terms of 77.1% F1 score. We hope our simple and effective Laneformer will serve as a strong baseline for future research in self-attention models for lane detection.
Bidirectional Graph Reasoning Network for Panoptic Segmentation
Apr 14, 2020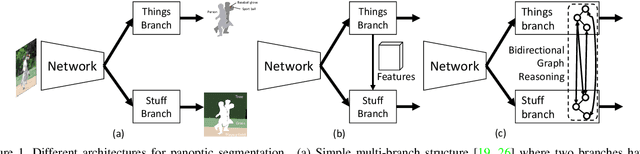
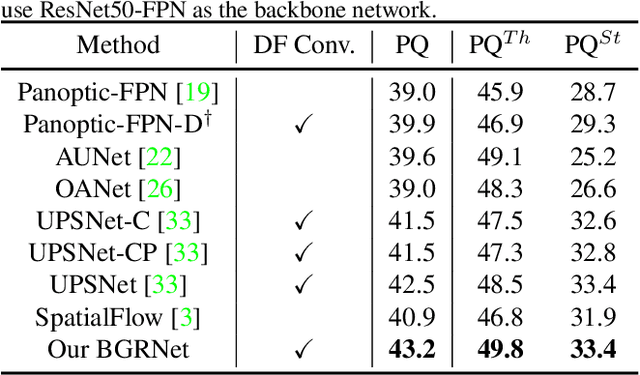
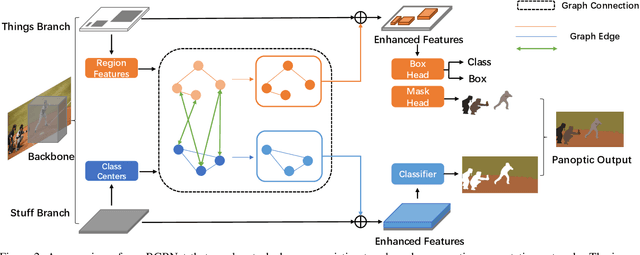

Recent researches on panoptic segmentation resort to a single end-to-end network to combine the tasks of instance segmentation and semantic segmentation. However, prior models only unified the two related tasks at the architectural level via a multi-branch scheme or revealed the underlying correlation between them by unidirectional feature fusion, which disregards the explicit semantic and co-occurrence relations among objects and background. Inspired by the fact that context information is critical to recognize and localize the objects, and inclusive object details are significant to parse the background scene, we thus investigate on explicitly modeling the correlations between object and background to achieve a holistic understanding of an image in the panoptic segmentation task. We introduce a Bidirectional Graph Reasoning Network (BGRNet), which incorporates graph structure into the conventional panoptic segmentation network to mine the intra-modular and intermodular relations within and between foreground things and background stuff classes. In particular, BGRNet first constructs image-specific graphs in both instance and semantic segmentation branches that enable flexible reasoning at the proposal level and class level, respectively. To establish the correlations between separate branches and fully leverage the complementary relations between things and stuff, we propose a Bidirectional Graph Connection Module to diffuse information across branches in a learnable fashion. Experimental results demonstrate the superiority of our BGRNet that achieves the new state-of-the-art performance on challenging COCO and ADE20K panoptic segmentation benchmarks.