 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProAct: Agentic Lookahead in Interactive Environments
Feb 05, 2026Existing Large Language Model (LLM) agents struggle in interactive environments requiring long-horizon planning, primarily due to compounding errors when simulating future states. To address this, we propose ProAct, a framework that enables agents to internalize accurate lookahead reasoning through a two-stage training paradigm. First, we introduce Grounded LookAhead Distillation (GLAD), where the agent undergoes supervised fine-tuning on trajectories derived from environment-based search. By compressing complex search trees into concise, causal reasoning chains, the agent learns the logic of foresight without the computational overhead of inference-time search. Second, to further refine decision accuracy, we propose the Monte-Carlo Critic (MC-Critic), a plug-and-play auxiliary value estimator designed to enhance policy-gradient algorithms like PPO and GRPO. By leveraging lightweight environment rollouts to calibrate value estimates, MC-Critic provides a low-variance signal that facilitates stable policy optimization without relying on expensive model-based value approximation. Experiments on both stochastic (e.g., 2048) and deterministic (e.g., Sokoban) environments demonstrate that ProAct significantly improves planning accuracy. Notably, a 4B parameter model trained with ProAct outperforms all open-source baselines and rivals state-of-the-art closed-source models, while demonstrating robust generalization to unseen environments. The codes and models are available at https://github.com/GreatX3/ProAct
NextFlow: Unified Sequential Modeling Activates Multimodal Understanding and Generation
Jan 05, 2026We present NextFlow, a unified decoder-only autoregressive transformer trained on 6 trillion interleaved text-image discrete tokens. By leveraging a unified vision representation within a unified autoregressive architecture, NextFlow natively activates multimodal understanding and generation capabilities, unlocking abilities of image editing, interleaved content and video generation. Motivated by the distinct nature of modalities - where text is strictly sequential and images are inherently hierarchical - we retain next-token prediction for text but adopt next-scale prediction for visual generation. This departs from traditional raster-scan methods, enabling the generation of 1024x1024 images in just 5 seconds - orders of magnitude faster than comparable AR models. We address the instabilities of multi-scale generation through a robust training recipe. Furthermore, we introduce a prefix-tuning strategy for reinforcement learning. Experiments demonstrate that NextFlow achieves state-of-the-art performance among unified models and rivals specialized diffusion baselines in visual quality.
DetailFlow: 1D Coarse-to-Fine Autoregressive Image Generation via Next-Detail Prediction
May 27, 2025This paper presents DetailFlow, a coarse-to-fine 1D autoregressive (AR) image generation method that models images through a novel next-detail prediction strategy. By learning a resolution-aware token sequence supervised with progressively degraded images, DetailFlow enables the generation process to start from the global structure and incrementally refine details. This coarse-to-fine 1D token sequence aligns well with the autoregressive inference mechanism, providing a more natural and efficient way for the AR model to generate complex visual content. Our compact 1D AR model achieves high-quality image synthesis with significantly fewer tokens than previous approaches, i.e. VAR/VQGAN. We further propose a parallel inference mechanism with self-correction that accelerates generation speed by approximately 8x while reducing accumulation sampling error inherent in teacher-forcing supervision. On the ImageNet 256x256 benchmark, our method achieves 2.96 gFID with 128 tokens, outperforming VAR (3.3 FID) and FlexVAR (3.05 FID), which both require 680 tokens in their AR models. Moreover, due to the significantly reduced token count and parallel inference mechanism, our method runs nearly 2x faster inference speed compared to VAR and FlexVAR. Extensive experimental results demonstrate DetailFlow's superior generation quality and efficiency compared to existing state-of-the-art methods.
IFEval-Audio: Benchmarking Instruction-Following Capability in Audio-based Large Language Models
May 22, 2025Large language models (LLMs) have demonstrated strong instruction-following capabilities in text-based tasks. However, this ability often deteriorates in multimodal models after alignment with non-text modalities such as images or audio. While several recent efforts have investigated instruction-following performance in text and vision-language models, instruction-following in audio-based large language models remains largely unexplored. To bridge this gap, we introduce IFEval-Audio, a novel evaluation dataset designed to assess the ability to follow instructions in an audio LLM. IFEval-Audio contains 280 audio-instruction-answer triples across six diverse dimensions: Content, Capitalization, Symbol, List Structure, Length, and Format. Each example pairs an audio input with a text instruction, requiring the model to generate an output that follows a specified structure. We benchmark state-of-the-art audio LLMs on their ability to follow audio-involved instructions. The dataset is released publicly to support future research in this emerging area.
TokenFlow: Unified Image Tokenizer for Multimodal Understanding and Generation
Dec 04, 2024



We present TokenFlow, a novel unified image tokenizer that bridges the long-standing gap between multimodal understanding and generation. Prior research attempt to employ a single reconstruction-targeted Vector Quantization (VQ) encoder for unifying these two tasks. We observe that understanding and generation require fundamentally different granularities of visual information. This leads to a critical trade-off, particularly compromising performance in multimodal understanding tasks. TokenFlow addresses this challenge through an innovative dual-codebook architecture that decouples semantic and pixel-level feature learning while maintaining their alignment via a shared mapping mechanism. This design enables direct access to both high-level semantic representations crucial for understanding tasks and fine-grained visual features essential for generation through shared indices. Our extensive experiments demonstrate TokenFlow's superiority across multiple dimensions. Leveraging TokenFlow, we demonstrate for the first time that discrete visual input can surpass LLaVA-1.5 13B in understanding performance, achieving a 7.2\% average improvement. For image reconstruction, we achieve a strong FID score of 0.63 at 384*384 resolution. Moreover, TokenFlow establishes state-of-the-art performance in autoregressive image generation with a GenEval score of 0.55 at 256*256 resolution, achieving comparable results to SDXL.
NovelGS: Consistent Novel-view Denoising via Large Gaussian Reconstruction Model
Nov 25, 2024

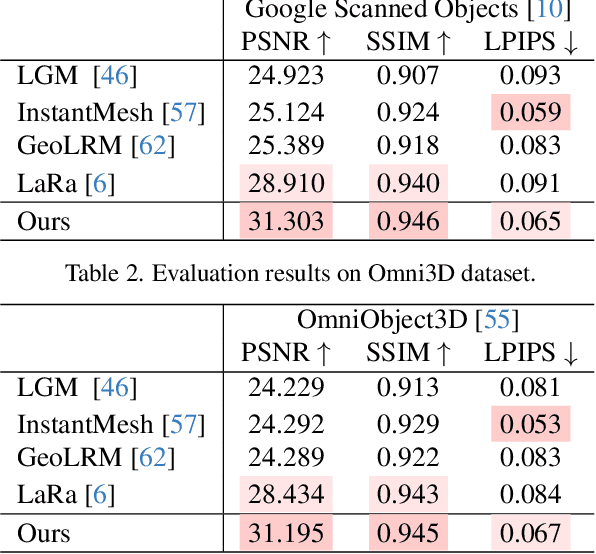

We introduce NovelGS, a diffusion model for Gaussian Splatting (GS) given sparse-view images. Recent works leverage feed-forward networks to generate pixel-aligned Gaussians, which could be fast rendered. Unfortunately, the method was unable to produce satisfactory results for areas not covered by the input images due to the formulation of these methods. In contrast, we leverage the novel view denoising through a transformer-based network to generate 3D Gaussians. Specifically, by incorporating both conditional views and noisy target views, the network predicts pixel-aligned Gaussians for each view. During training, the rendered target and some additional views of the Gaussians are supervised. During inference, the target views are iteratively rendered and denoised from pure noise. Our approach demonstrates state-of-the-art performance in addressing the multi-view image reconstruction challenge. Due to generative modeling of unseen regions, NovelGS effectively reconstructs 3D objects with consistent and sharp textures. Experimental results on publicly available datasets indicate that NovelGS substantially surpasses existing image-to-3D frameworks, both qualitatively and quantitatively. We also demonstrate the potential of NovelGS in generative tasks, such as text-to-3D and image-to-3D, by integrating it with existing multiview diffusion models. We will make the code publicly accessible.
MiraData: A Large-Scale Video Dataset with Long Durations and Structured Captions
Jul 08, 2024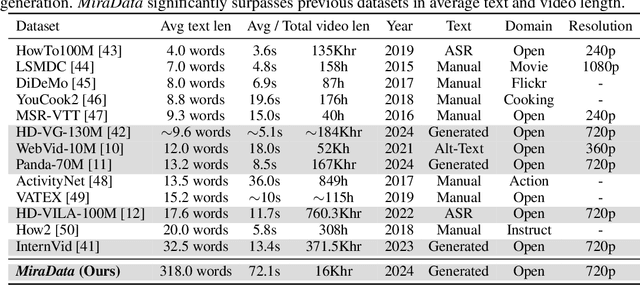
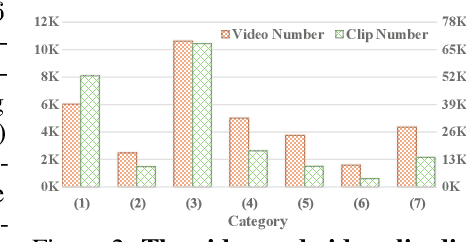


Sora's high-motion intensity and long consistent videos have significantly impacted the field of video generation, attracting unprecedented attention. However, existing publicly available datasets are inadequate for generating Sora-like videos, as they mainly contain short videos with low motion intensity and brief captions. To address these issues, we propose MiraData, a high-quality video dataset that surpasses previous ones in video duration, caption detail, motion strength, and visual quality. We curate MiraData from diverse, manually selected sources and meticulously process the data to obtain semantically consistent clips. GPT-4V is employed to annotate structured captions, providing detailed descriptions from four different perspectives along with a summarized dense caption. To better assess temporal consistency and motion intensity in video generation, we introduce MiraBench, which enhances existing benchmarks by adding 3D consistency and tracking-based motion strength metrics. MiraBench includes 150 evaluation prompts and 17 metrics covering temporal consistency, motion strength, 3D consistency, visual quality, text-video alignment, and distribution similarity. To demonstrate the utility and effectiveness of MiraData, we conduct experiments using our DiT-based video generation model, MiraDiT. The experimental results on MiraBench demonstrate the superiority of MiraData, especially in motion strength.
InstantMesh: Efficient 3D Mesh Generation from a Single Image with Sparse-view Large Reconstruction Models
Apr 14, 2024



We present InstantMesh, a feed-forward framework for instant 3D mesh generation from a single image, featuring state-of-the-art generation quality and significant training scalability. By synergizing the strengths of an off-the-shelf multiview diffusion model and a sparse-view reconstruction model based on the LRM architecture, InstantMesh is able to create diverse 3D assets within 10 seconds. To enhance the training efficiency and exploit more geometric supervisions, e.g, depths and normals, we integrate a differentiable iso-surface extraction module into our framework and directly optimize on the mesh representation. Experimental results on public datasets demonstrate that InstantMesh significantly outperforms other latest image-to-3D baselines, both qualitatively and quantitatively. We release all the code, weights, and demo of InstantMesh, with the intention that it can make substantial contributions to the community of 3D generative AI and empower both researchers and content creators.
Advances in 3D Generation: A Survey
Jan 31, 2024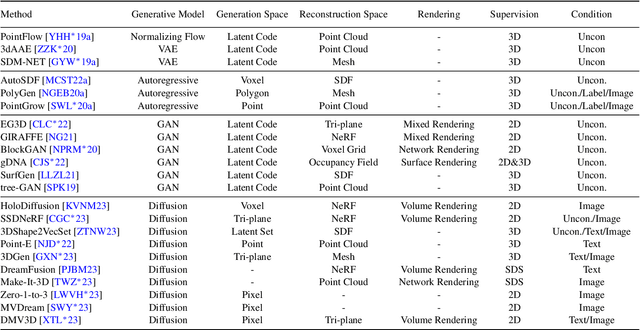
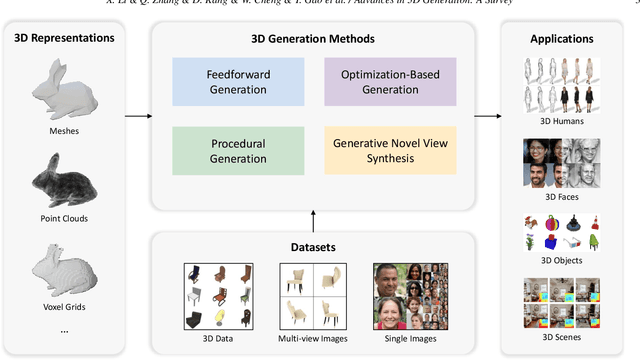
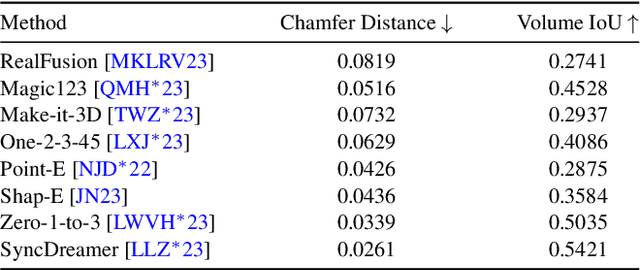
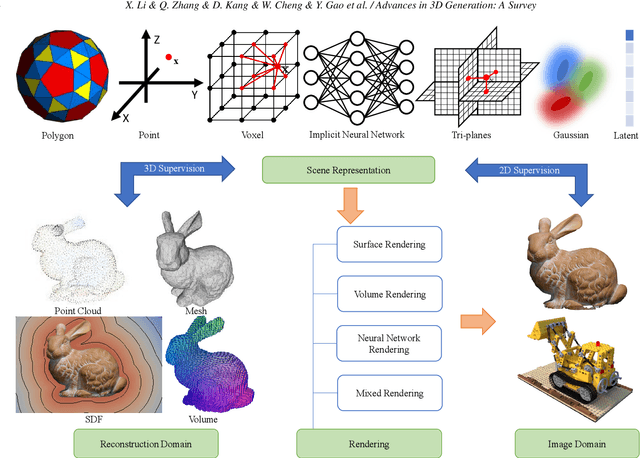
Generating 3D models lies at the core of computer graphics and has been the focus of decades of research. With the emergence of advanced neural representations and generative models, the field of 3D content generation is developing rapidly, enabling the creation of increasingly high-quality and diverse 3D models. The rapid growth of this field makes it difficult to stay abreast of all recent developments. In this survey, we aim to introduce the fundamental methodologies of 3D generation methods and establish a structured roadmap, encompassing 3D representation, generation methods, datasets, and corresponding applications. Specifically, we introduce the 3D representations that serve as the backbone for 3D generation. Furthermore, we provide a comprehensive overview of the rapidly growing literature on generation methods, categorized by the type of algorithmic paradigms, including feedforward generation, optimization-based generation, procedural generation, and generative novel view synthesis. Lastly, we discuss available datasets, applications, and open challenges. We hope this survey will help readers explore this exciting topic and foster further advancements in the field of 3D content generation.
Enhancing Human Experience in Human-Agent Collaboration: A Human-Centered Modeling Approach Based on Positive Human Gain
Jan 28, 2024



Existing game AI research mainly focuses on enhancing agents' abilities to win games, but this does not inherently make humans have a better experience when collaborating with these agents. For example, agents may dominate the collaboration and exhibit unintended or detrimental behaviors, leading to poor experiences for their human partners. In other words, most game AI agents are modeled in a "self-centered" manner. In this paper, we propose a "human-centered" modeling scheme for collaborative agents that aims to enhance the experience of humans. Specifically, we model the experience of humans as the goals they expect to achieve during the task. We expect that agents should learn to enhance the extent to which humans achieve these goals while maintaining agents' original abilities (e.g., winning games). To achieve this, we propose the Reinforcement Learning from Human Gain (RLHG) approach. The RLHG approach introduces a "baseline", which corresponds to the extent to which humans primitively achieve their goals, and encourages agents to learn behaviors that can effectively enhance humans in achieving their goals better. We evaluate the RLHG agent in the popular Multi-player Online Battle Arena (MOBA) game, Honor of Kings, by conducting real-world human-agent tests. Both objective performance and subjective preference results show that the RLHG agent provides participants better gaming experience.