 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUI-Voyager: A Self-Evolving GUI Agent Learning via Failed Experience
Mar 25, 2026Autonomous mobile GUI agents have attracted increasing attention along with the advancement of Multimodal Large Language Models (MLLMs). However, existing methods still suffer from inefficient learning from failed trajectories and ambiguous credit assignment under sparse rewards for long-horizon GUI tasks. To that end, we propose UI-Voyager, a novel two-stage self-evolving mobile GUI agent. In the first stage, we employ Rejection Fine-Tuning (RFT), which enables the continuous co-evolution of data and models in a fully autonomous loop. The second stage introduces Group Relative Self-Distillation (GRSD), which identifies critical fork points in group rollouts and constructs dense step-level supervision from successful trajectories to correct failed ones. Extensive experiments on AndroidWorld show that our 4B model achieves an 81.0% Pass@1 success rate, outperforming numerous recent baselines and exceeding human-level performance. Ablation and case studies further verify the effectiveness of GRSD. Our method represents a significant leap toward efficient, self-evolving, and high-performance mobile GUI automation without expensive manual data annotation.
ProAct: Agentic Lookahead in Interactive Environments
Feb 05, 2026Existing Large Language Model (LLM) agents struggle in interactive environments requiring long-horizon planning, primarily due to compounding errors when simulating future states. To address this, we propose ProAct, a framework that enables agents to internalize accurate lookahead reasoning through a two-stage training paradigm. First, we introduce Grounded LookAhead Distillation (GLAD), where the agent undergoes supervised fine-tuning on trajectories derived from environment-based search. By compressing complex search trees into concise, causal reasoning chains, the agent learns the logic of foresight without the computational overhead of inference-time search. Second, to further refine decision accuracy, we propose the Monte-Carlo Critic (MC-Critic), a plug-and-play auxiliary value estimator designed to enhance policy-gradient algorithms like PPO and GRPO. By leveraging lightweight environment rollouts to calibrate value estimates, MC-Critic provides a low-variance signal that facilitates stable policy optimization without relying on expensive model-based value approximation. Experiments on both stochastic (e.g., 2048) and deterministic (e.g., Sokoban) environments demonstrate that ProAct significantly improves planning accuracy. Notably, a 4B parameter model trained with ProAct outperforms all open-source baselines and rivals state-of-the-art closed-source models, while demonstrating robust generalization to unseen environments. The codes and models are available at https://github.com/GreatX3/ProAct
Enhancing Human Experience in Human-Agent Collaboration: A Human-Centered Modeling Approach Based on Positive Human Gain
Jan 28, 2024



Existing game AI research mainly focuses on enhancing agents' abilities to win games, but this does not inherently make humans have a better experience when collaborating with these agents. For example, agents may dominate the collaboration and exhibit unintended or detrimental behaviors, leading to poor experiences for their human partners. In other words, most game AI agents are modeled in a "self-centered" manner. In this paper, we propose a "human-centered" modeling scheme for collaborative agents that aims to enhance the experience of humans. Specifically, we model the experience of humans as the goals they expect to achieve during the task. We expect that agents should learn to enhance the extent to which humans achieve these goals while maintaining agents' original abilities (e.g., winning games). To achieve this, we propose the Reinforcement Learning from Human Gain (RLHG) approach. The RLHG approach introduces a "baseline", which corresponds to the extent to which humans primitively achieve their goals, and encourages agents to learn behaviors that can effectively enhance humans in achieving their goals better. We evaluate the RLHG agent in the popular Multi-player Online Battle Arena (MOBA) game, Honor of Kings, by conducting real-world human-agent tests. Both objective performance and subjective preference results show that the RLHG agent provides participants better gaming experience.
Few-shot Image Classification based on Gradual Machine Learning
Jul 28, 2023
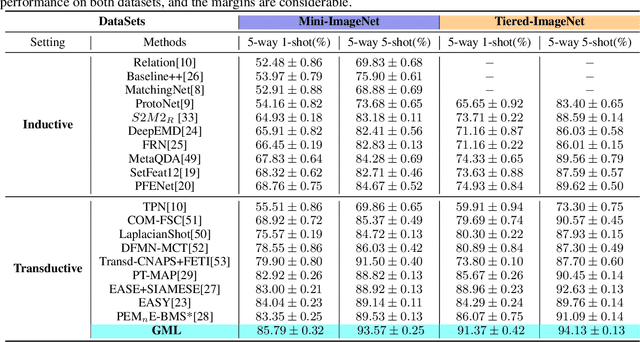
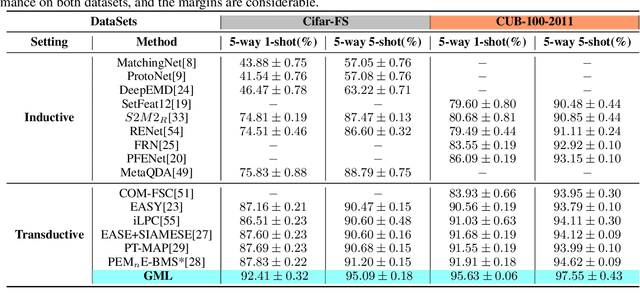
Few-shot image classification aims to accurately classify unlabeled images using only a few labeled samples. The state-of-the-art solutions are built by deep learning, which focuses on designing increasingly complex deep backbones. Unfortunately, the task remains very challenging due to the difficulty of transferring the knowledge learned in training classes to new ones. In this paper, we propose a novel approach based on the non-i.i.d paradigm of gradual machine learning (GML). It begins with only a few labeled observations, and then gradually labels target images in the increasing order of hardness by iterative factor inference in a factor graph. Specifically, our proposed solution extracts indicative feature representations by deep backbones, and then constructs both unary and binary factors based on the extracted features to facilitate gradual learning. The unary factors are constructed based on class center distance in an embedding space, while the binary factors are constructed based on k-nearest neighborhood. We have empirically validated the performance of the proposed approach on benchmark datasets by a comparative study. Our extensive experiments demonstrate that the proposed approach can improve the SOTA performance by 1-5% in terms of accuracy. More notably, it is more robust than the existing deep models in that its performance can consistently improve as the size of query set increases while the performance of deep models remains essentially flat or even becomes worse.
Towards Effective and Interpretable Human-Agent Collaboration in MOBA Games: A Communication Perspective
Apr 23, 2023

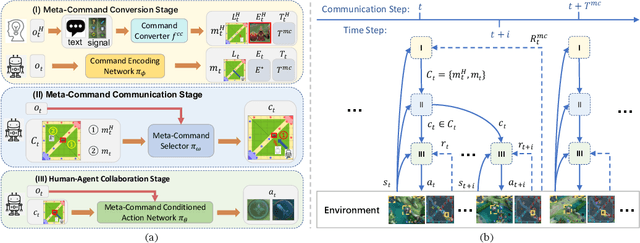

MOBA games, e.g., Dota2 and Honor of Kings, have been actively used as the testbed for the recent AI research on games, and various AI systems have been developed at the human level so far. However, these AI systems mainly focus on how to compete with humans, less on exploring how to collaborate with humans. To this end, this paper makes the first attempt to investigate human-agent collaboration in MOBA games. In this paper, we propose to enable humans and agents to collaborate through explicit communication by designing an efficient and interpretable Meta-Command Communication-based framework, dubbed MCC, for accomplishing effective human-agent collaboration in MOBA games. The MCC framework consists of two pivotal modules: 1) an interpretable communication protocol, i.e., the Meta-Command, to bridge the communication gap between humans and agents; 2) a meta-command value estimator, i.e., the Meta-Command Selector, to select a valuable meta-command for each agent to achieve effective human-agent collaboration. Experimental results in Honor of Kings demonstrate that MCC agents can collaborate reasonably well with human teammates and even generalize to collaborate with different levels and numbers of human teammates. Videos are available at https://sites.google.com/view/mcc-demo.