 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOdysseyBench: Evaluating LLM Agents on Long-Horizon Complex Office Application Workflows
Aug 12, 2025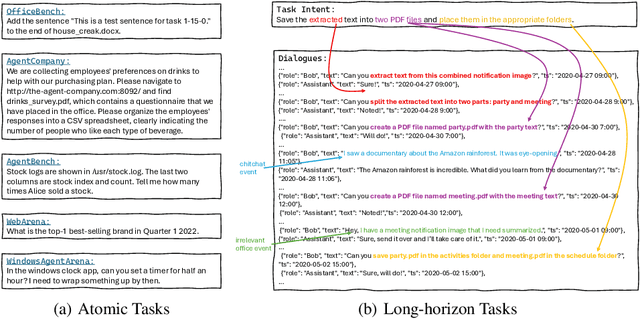
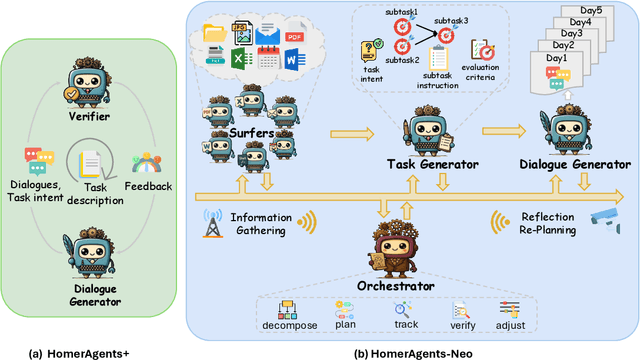
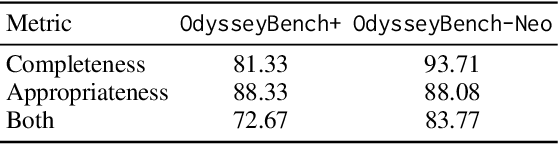
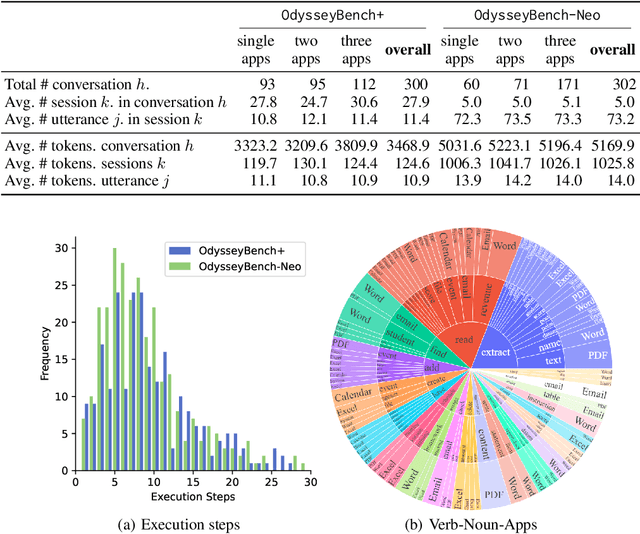
Autonomous agents powered by large language models (LLMs) are increasingly deployed in real-world applications requiring complex, long-horizon workflows. However, existing benchmarks predominantly focus on atomic tasks that are self-contained and independent, failing to capture the long-term contextual dependencies and multi-interaction coordination required in realistic scenarios. To address this gap, we introduce OdysseyBench, a comprehensive benchmark for evaluating LLM agents on long-horizon workflows across diverse office applications including Word, Excel, PDF, Email, and Calendar. Our benchmark comprises two complementary splits: OdysseyBench+ with 300 tasks derived from real-world use cases, and OdysseyBench-Neo with 302 newly synthesized complex tasks. Each task requires agent to identify essential information from long-horizon interaction histories and perform multi-step reasoning across various applications. To enable scalable benchmark creation, we propose HomerAgents, a multi-agent framework that automates the generation of long-horizon workflow benchmarks through systematic environment exploration, task generation, and dialogue synthesis. Our extensive evaluation demonstrates that OdysseyBench effectively challenges state-of-the-art LLM agents, providing more accurate assessment of their capabilities in complex, real-world contexts compared to existing atomic task benchmarks. We believe that OdysseyBench will serve as a valuable resource for advancing the development and evaluation of LLM agents in real-world productivity scenarios. In addition, we release OdysseyBench and HomerAgents to foster research along this line.
ExpertSteer: Intervening in LLMs through Expert Knowledge
May 18, 2025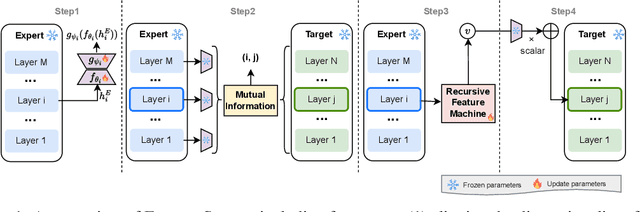
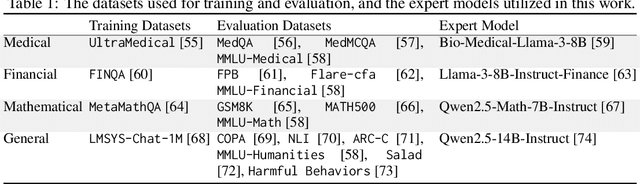
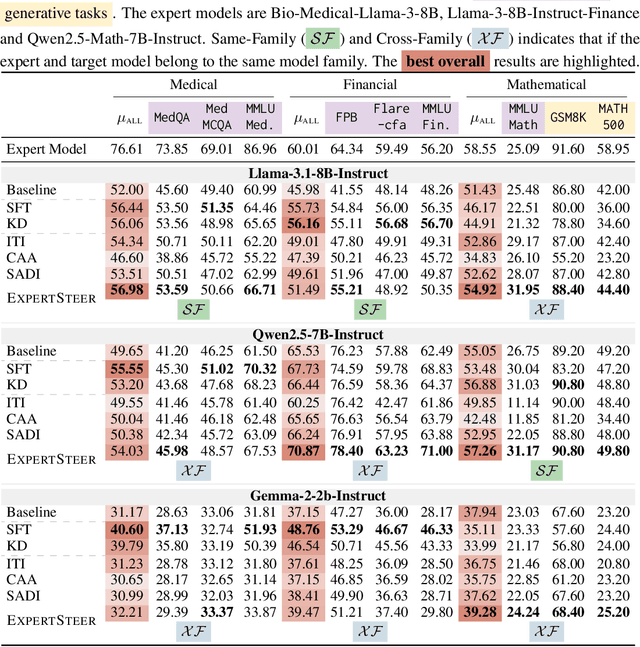
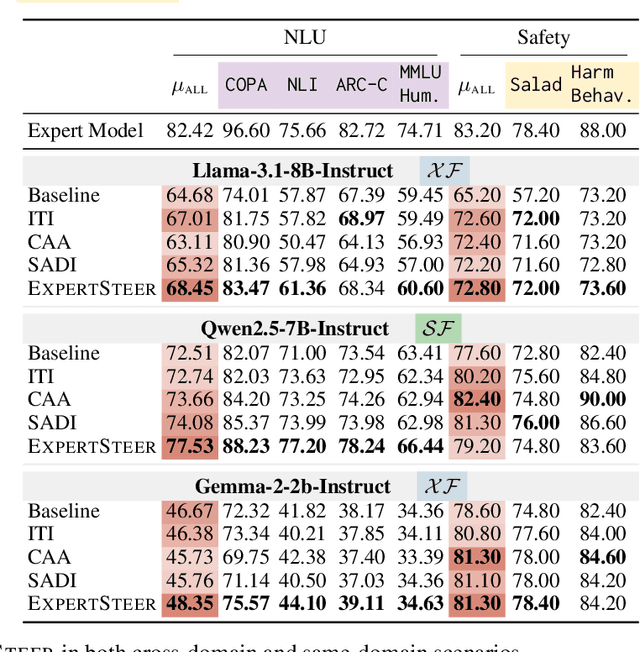
Large Language Models (LLMs) exhibit remarkable capabilities across various tasks, yet guiding them to follow desired behaviours during inference remains a significant challenge. Activation steering offers a promising method to control the generation process of LLMs by modifying their internal activations. However, existing methods commonly intervene in the model's behaviour using steering vectors generated by the model itself, which constrains their effectiveness to that specific model and excludes the possibility of leveraging powerful external expert models for steering. To address these limitations, we propose ExpertSteer, a novel approach that leverages arbitrary specialized expert models to generate steering vectors, enabling intervention in any LLMs. ExpertSteer transfers the knowledge from an expert model to a target LLM through a cohesive four-step process: first aligning representation dimensions with auto-encoders to enable cross-model transfer, then identifying intervention layer pairs based on mutual information analysis, next generating steering vectors from the expert model using Recursive Feature Machines, and finally applying these vectors on the identified layers during inference to selectively guide the target LLM without updating model parameters. We conduct comprehensive experiments using three LLMs on 15 popular benchmarks across four distinct domains. Experiments demonstrate that ExpertSteer significantly outperforms established baselines across diverse tasks at minimal cost.
HBO: Hierarchical Balancing Optimization for Fine-Tuning Large Language Models
May 18, 2025Fine-tuning large language models (LLMs) on a mixture of diverse datasets poses challenges due to data imbalance and heterogeneity. Existing methods often address these issues across datasets (globally) but overlook the imbalance and heterogeneity within individual datasets (locally), which limits their effectiveness. We introduce Hierarchical Balancing Optimization (HBO), a novel method that enables LLMs to autonomously adjust data allocation during fine-tuning both across datasets (globally) and within each individual dataset (locally). HBO employs a bilevel optimization strategy with two types of actors: a Global Actor, which balances data sampling across different subsets of the training mixture, and several Local Actors, which optimizes data usage within each subset based on difficulty levels. These actors are guided by reward functions derived from the LLM's training state, which measure learning progress and relative performance improvement. We evaluate HBO on three LLM backbones across nine diverse tasks in multilingual and multitask setups. Results show that HBO consistently outperforms existing baselines, achieving significant accuracy gains. Our in-depth analysis further demonstrates that both the global actor and local actors of HBO effectively adjust data usage during fine-tuning. HBO provides a comprehensive solution to the challenges of data imbalance and heterogeneity in LLM fine-tuning, enabling more effective training across diverse datasets.
The Bitter Lesson Learned from 2,000+ Multilingual Benchmarks
Apr 22, 2025



As large language models (LLMs) continue to advance in linguistic capabilities, robust multilingual evaluation has become essential for promoting equitable technological progress. This position paper examines over 2,000 multilingual (non-English) benchmarks from 148 countries, published between 2021 and 2024, to evaluate past, present, and future practices in multilingual benchmarking. Our findings reveal that, despite significant investments amounting to tens of millions of dollars, English remains significantly overrepresented in these benchmarks. Additionally, most benchmarks rely on original language content rather than translations, with the majority sourced from high-resource countries such as China, India, Germany, the UK, and the USA. Furthermore, a comparison of benchmark performance with human judgments highlights notable disparities. STEM-related tasks exhibit strong correlations with human evaluations (0.70 to 0.85), while traditional NLP tasks like question answering (e.g., XQuAD) show much weaker correlations (0.11 to 0.30). Moreover, translating English benchmarks into other languages proves insufficient, as localized benchmarks demonstrate significantly higher alignment with local human judgments (0.68) than their translated counterparts (0.47). This underscores the importance of creating culturally and linguistically tailored benchmarks rather than relying solely on translations. Through this comprehensive analysis, we highlight six key limitations in current multilingual evaluation practices, propose the guiding principles accordingly for effective multilingual benchmarking, and outline five critical research directions to drive progress in the field. Finally, we call for a global collaborative effort to develop human-aligned benchmarks that prioritize real-world applications.
Demystifying Multilingual Chain-of-Thought in Process Reward Modeling
Feb 18, 2025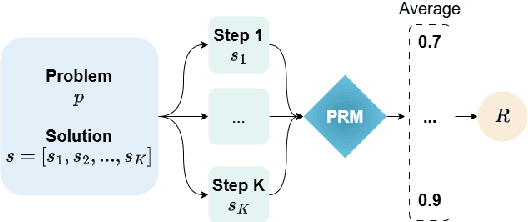
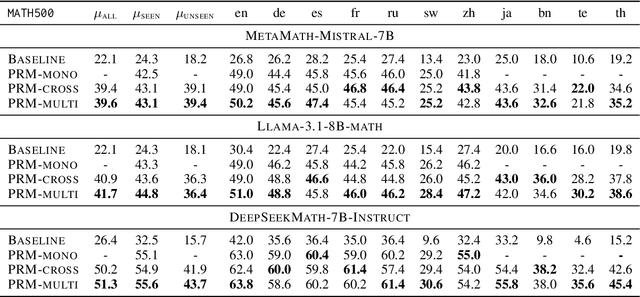
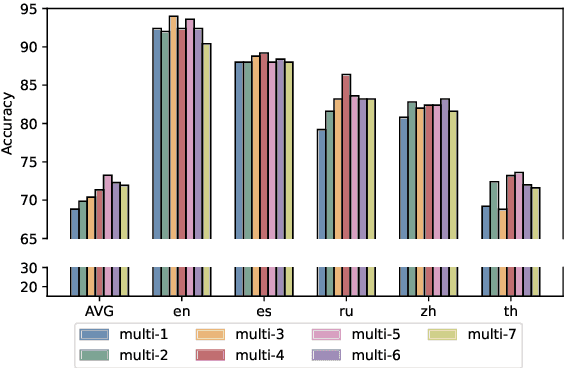

Large language models (LLMs) are designed to perform a wide range of tasks. To improve their ability to solve complex problems requiring multi-step reasoning, recent research leverages process reward modeling to provide fine-grained feedback at each step of the reasoning process for reinforcement learning (RL), but it predominantly focuses on English. In this paper, we tackle the critical challenge of extending process reward models (PRMs) to multilingual settings. To achieve this, we train multilingual PRMs on a dataset spanning seven languages, which is translated from English. Through comprehensive evaluations on two widely used reasoning benchmarks across 11 languages, we demonstrate that multilingual PRMs not only improve average accuracy but also reduce early-stage reasoning errors. Furthermore, our results highlight the sensitivity of multilingual PRMs to both the number of training languages and the volume of English data, while also uncovering the benefits arising from more candidate responses and trainable parameters. This work opens promising avenues for robust multilingual applications in complex, multi-step reasoning tasks. In addition, we release the code to foster research along this line.
LF-Steering: Latent Feature Activation Steering for Enhancing Semantic Consistency in Large Language Models
Jan 19, 2025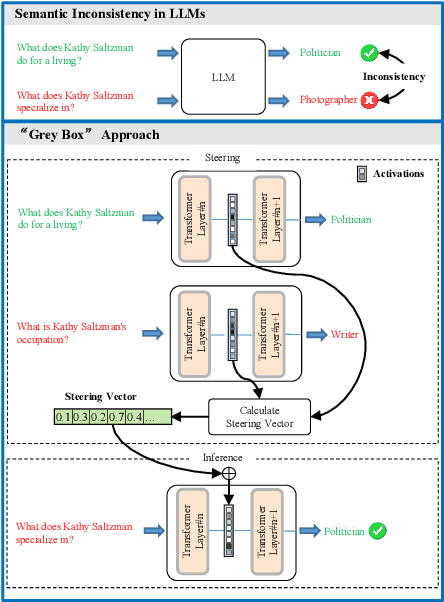

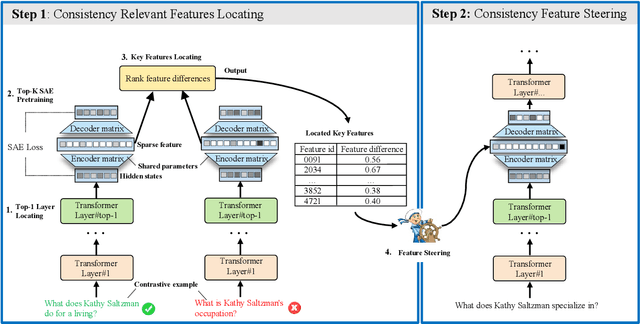

Large Language Models (LLMs) often generate inconsistent responses when prompted with semantically equivalent paraphrased inputs. Recently, activation steering, a technique that modulates LLM behavior by adjusting their latent representations during inference time, has been explored to improve the semantic consistency of LLMs. However, these methods typically operate at the model component level, such as layer hidden states or attention heads. They face a challenge due to the ``polysemanticity issue'', where the model components of LLMs typically encode multiple entangled features, making precise steering difficult. To address this challenge, we drill down to feature-level representations and propose LF-Steering, a novel activation steering approach to precisely identify latent feature representations responsible for semantic inconsistency. More specifically, our method maps the hidden states of relevant transformer layer into a sparsely activated, high-dimensional feature space based on a sparse autoencoder (SAE), ensuring model steering based on decoupled feature representations with minimal interference. Comprehensive experiments on both NLU and NLG datasets demonstrate the effectiveness of our method in enhancing semantic consistency, resulting in significant performance gains for various NLU and NLG tasks.
Bridging the Language Gaps in Large Language Models with Inference-Time Cross-Lingual Intervention
Oct 16, 2024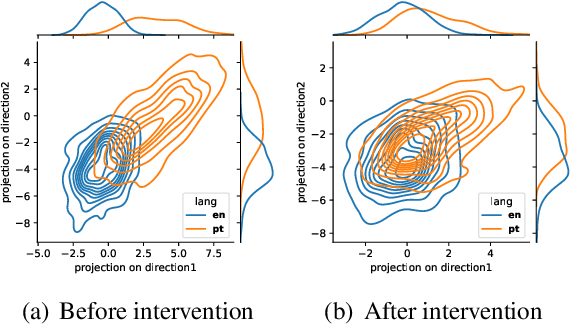
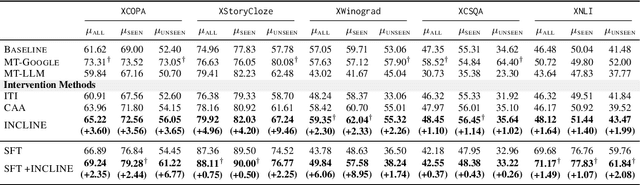
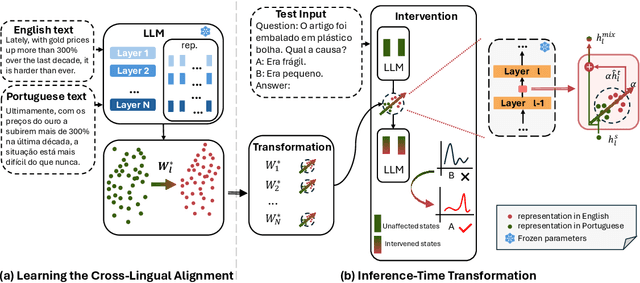
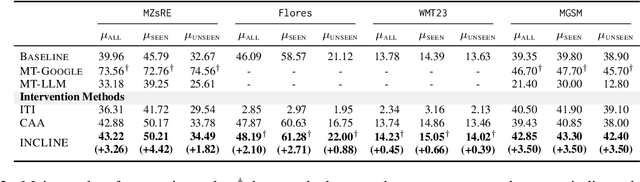
Large Language Models (LLMs) have shown remarkable capabilities in natural language processing but exhibit significant performance gaps among different languages. Most existing approaches to address these disparities rely on pretraining or fine-tuning, which are resource-intensive. To overcome these limitations without incurring significant costs, we propose Inference-Time Cross-Lingual Intervention (INCLINE), a novel framework that enhances LLM performance on low-performing (source) languages by aligning their internal representations with those of high-performing (target) languages during inference. INCLINE initially learns alignment matrices using parallel sentences from source and target languages through a Least-Squares optimization, and then applies these matrices during inference to transform the low-performing language representations toward the high-performing language space. Extensive experiments on nine benchmarks with five LLMs demonstrate that INCLINE significantly improves performance across diverse tasks and languages, compared to recent strong baselines. Our analysis demonstrates that INCLINE is highly cost-effective and applicable to a wide range of applications. In addition, we release the code to foster research along this line: https://github.com/weixuan-wang123/INCLINE.
Semantics-Adaptive Activation Intervention for LLMs via Dynamic Steering Vectors
Oct 16, 2024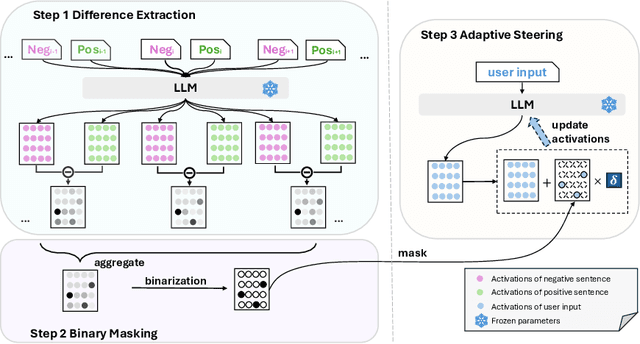
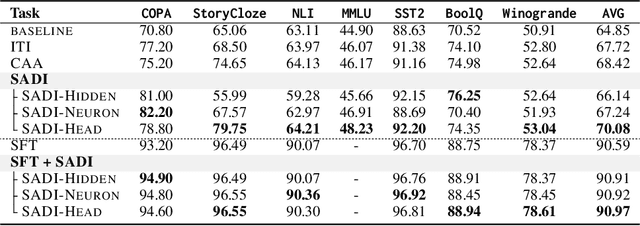
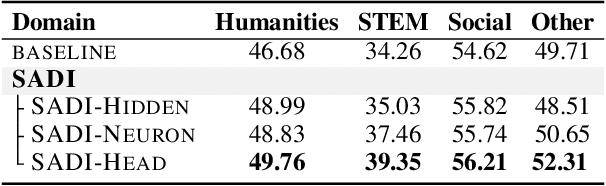

Large language models (LLMs) have achieved remarkable performance across many tasks, yet aligning them with desired behaviors remains challenging. Activation intervention has emerged as an effective and economical method to modify the behavior of LLMs. Despite considerable interest in this area, current intervention methods exclusively employ a fixed steering vector to modify model activations, lacking adaptability to diverse input semantics. To address this limitation, we propose Semantics-Adaptive Dynamic Intervention (SADI), a novel method that constructs a dynamic steering vector to intervene model activations at inference time. More specifically, SADI utilizes activation differences in contrastive pairs to precisely identify critical elements of an LLM (i.e., attention heads, hidden states, and neurons) for targeted intervention. During inference, SADI dynamically steers model behavior by scaling element-wise activations based on the directions of input semantics. Experimental results show that SADI outperforms established baselines by substantial margins, improving task performance without training. SADI's cost-effectiveness and generalizability across various LLM backbones and tasks highlight its potential as a versatile alignment technique. In addition, we release the code to foster research along this line:https://github.com/weixuan-wang123/SADI.
Sharing Matters: Analysing Neurons Across Languages and Tasks in LLMs
Jun 13, 2024
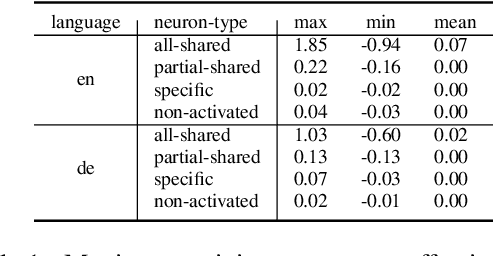
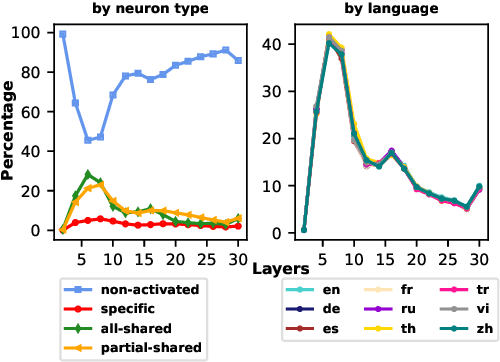
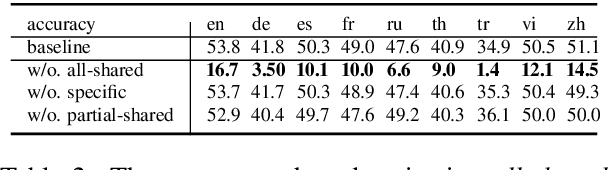
Multilingual large language models (LLMs) have greatly increased the ceiling of performance on non-English tasks. However the mechanisms behind multilingualism in these LLMs are poorly understood. Of particular interest is the degree to which internal representations are shared between languages. Recent work on neuron analysis of LLMs has focused on the monolingual case, and the limited work on the multilingual case has not considered the interaction between tasks and linguistic representations. In our work, we investigate how neuron activation is shared across languages by categorizing neurons into four distinct groups according to their responses across different languages for a particular input: all-shared, partial-shared, specific, and non-activated. This categorization is combined with a study of neuron attribution, i.e. the importance of a neuron w.r.t an output. Our analysis reveals the following insights: (i) the linguistic sharing patterns are strongly affected by the type of task, but neuron behaviour changes across different inputs even for the same task; (ii) all-shared neurons play a key role in generating correct responses; (iii) boosting multilingual alignment by increasing all-shared neurons can enhance accuracy on multilingual tasks. The code is available at https://github.com/weixuan-wang123/multilingual-neurons.
Enhancing Human Experience in Human-Agent Collaboration: A Human-Centered Modeling Approach Based on Positive Human Gain
Jan 28, 2024



Existing game AI research mainly focuses on enhancing agents' abilities to win games, but this does not inherently make humans have a better experience when collaborating with these agents. For example, agents may dominate the collaboration and exhibit unintended or detrimental behaviors, leading to poor experiences for their human partners. In other words, most game AI agents are modeled in a "self-centered" manner. In this paper, we propose a "human-centered" modeling scheme for collaborative agents that aims to enhance the experience of humans. Specifically, we model the experience of humans as the goals they expect to achieve during the task. We expect that agents should learn to enhance the extent to which humans achieve these goals while maintaining agents' original abilities (e.g., winning games). To achieve this, we propose the Reinforcement Learning from Human Gain (RLHG) approach. The RLHG approach introduces a "baseline", which corresponds to the extent to which humans primitively achieve their goals, and encourages agents to learn behaviors that can effectively enhance humans in achieving their goals better. We evaluate the RLHG agent in the popular Multi-player Online Battle Arena (MOBA) game, Honor of Kings, by conducting real-world human-agent tests. Both objective performance and subjective preference results show that the RLHG agent provides participants better gaming experience.