 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWideband Near-Field Sensing in ISAC: Unified Algorithm Design and Decoupled Effect Analysis
Mar 29, 2026To advance integrated sensing and communications (ISAC) in sixth-generation (6G) extremely large-scale multiple-input multiple-output (XL-MIMO) networks, a low-complexity compressed sensing (CS)-based dictionary design is proposed for wideband near-field (WB-NF) target localization. Currently, the massive signal dimensions in the WB-NF regime impose severe computational burdens and high spatial-frequency coherence on conventional grid-based algorithms. Furthermore, a unified framework exploiting both wideband (WB) and near-field (NF) effects is lacking, and the analytical conditions for simplifying this model into decoupled approximations remain uncharacterized. To address these challenges, the proposed algorithm mathematically decouples the mutual coherence function and introduces a novel angle-distance sampling grid with customized distance adjustments, drastically reducing dictionary dimensions while ensuring low coherence. To isolate the individual WB and NF impacts, two coherence-based metrics are formulated to establish the effective boundaries of the narrowband near-field (NB-NF) and wideband far-field (WB-FF) regions, where respective multiple signal classification (MUSIC) algorithms are utilized. Simulations demonstrate that the CS-based method achieves robust performance across the entire regime, and the established boundaries provide crucial theoretical guidelines for WB and NF effect decoupling.
Deep Learning based Cross-Receiver Radio Frequency Fingerprint Identification Under Varying Channels
Mar 09, 2026Radio frequency fingerprint identification (RFFI) exploits device-specific hardware impairments for transmitter recognition, but its performance is highly vulnerable to receiver variations and changing wireless channels in cross-receiver deployment. To address both challenges, this paper proposes a novel cross-receiver RFFI framework with channel robustness. In the enrollment stage, a channel-robust preprocessing method is developed to construct denoised spectral quotient (DSQ) sequences, and a DSQ-based convolutional neural network (DSQCNN) is trained using data collected from the source receiver. In the cross-receiver deployment stage, a calibration dataset is built from signals captured by both the source and target receivers, and a trainable calibration neural network (TCNN) is designed to learn the nonlinear mapping between them. The cascaded TCNN-DSQCNN framework then enables robust transmitter classification on the target receiver under varying channel conditions. To the best of our knowledge, this is the first work to jointly address channel and receiver portability through combined channel suppression and nonlinear receiver calibration. Simulations with twelve WiFi transmitters and three receivers show that the proposed method achieves reliable cross-receiver classification, reaching over 90\% accuracy at an SNR of 24 dB.
Logi-PAR: Logic-Infused Patient Activity Recognition via Differentiable Rule
Mar 05, 2026Patient Activity Recognition (PAR) in clinical settings uses activity data to improve safety and quality of care. Although significant progress has been made, current models mainly identify which activity is occurring. They often spatially compose sub-sparse visual cues using global and local attention mechanisms, yet only learn logically implicit patterns due to their neural-pipeline. Advancing clinical safety requires methods that can infer why a set of visual cues implies a risk, and how these can be compositionally reasoned through explicit logic beyond mere classification. To address this, we proposed Logi-PAR, the first Logic-Infused Patient Activity Recognition Framework that integrates contextual fact fusion as a multi-view primitive extractor and injects neural-guided differentiable rules. Our method automatically learns rules from visual cues, optimizing them end-to-end while enabling the implicit emergence patterns to be explicitly labelled during training. To the best of our knowledge, Logi-PAR is the first framework to recognize patient activity by applying learnable logic rules to symbolic mappings. It produces auditable why explanations as rule traces and supports counterfactual interventions (e.g., risk would decrease by 65% if assistance were present). Extensive evaluation on clinical benchmarks (VAST and OmniFall) demonstrates state-of-the-art performance, significantly outperforming Vision-Language Models and transformer baselines. The code is available via: https://github.com/zararkhan985/Logi-PAR.git}
MUG: Meta-path-aware Universal Heterogeneous Graph Pre-Training
Feb 26, 2026Universal graph pre-training has emerged as a key paradigm in graph representation learning, offering a promising way to train encoders to learn transferable representations from unlabeled graphs and to effectively generalize across a wide range of downstream tasks. However, recent explorations in universal graph pre-training primarily focus on homogeneous graphs and it remains unexplored for heterogeneous graphs, which exhibit greater structural and semantic complexity. This heterogeneity makes it highly challenging to train a universal encoder for diverse heterogeneous graphs: (i) the diverse types with dataset-specific semantics hinder the construction of a unified representation space; (ii) the number and semantics of meta-paths vary across datasets, making encoding and aggregation patterns learned from one dataset difficult to apply to others. To address these challenges, we propose a novel Meta-path-aware Universal heterogeneous Graph pre-training (MUG) approach. Specifically, for challenge (i), MUG introduces a input unification module that integrates information from multiple node and relation types within each heterogeneous graph into a unified representation.This representation is then projected into a shared space by a dimension-aware encoder, enabling alignment across graphs with diverse schemas.Furthermore, for challenge (ii), MUG trains a shared encoder to capture consistent structural patterns across diverse meta-path views rather than relying on dataset-specific aggregation strategies, while a global objective encourages discriminability and reduces dataset-specific biases. Extensive experiments demonstrate the effectiveness of MUG on some real datasets.
RefProtoFL: Communication-Efficient Federated Learning via External-Referenced Prototype Alignment
Jan 21, 2026Federated learning (FL) enables collaborative model training without sharing raw data in edge environments, but is constrained by limited communication bandwidth and heterogeneous client data distributions. Prototype-based FL mitigates this issue by exchanging class-wise feature prototypes instead of full model parameters; however, existing methods still suffer from suboptimal generalization under severe communication constraints. In this paper, we propose RefProtoFL, a communication-efficient FL framework that integrates External-Referenced Prototype Alignment (ERPA) for representation consistency with Adaptive Probabilistic Update Dropping (APUD) for communication efficiency. Specifically, we decompose the model into a private backbone and a lightweight shared adapter, and restrict federated communication to the adapter parameters only. To further reduce uplink cost, APUD performs magnitude-aware Top-K sparsification, transmitting only the most significant adapter updates for server-side aggregation. To address representation inconsistency across heterogeneous clients, ERPA leverages a small server-held public dataset to construct external reference prototypes that serve as shared semantic anchors. For classes covered by public data, clients directly align local representations to public-induced prototypes, whereas for uncovered classes, alignment relies on server-aggregated global reference prototypes via weighted averaging. Extensive experiments on standard benchmarks demonstrate that RefProtoFL attains higher classification accuracy than state-of-the-art prototype-based FL baselines.
Integrated Sensing, Communication and Control enabled Agile UAV Swarm
Jan 21, 2026Uncrewed aerial vehicle (UAV) swarms are pivotal in the applications such as disaster relief, aerial base station (BS) and logistics transportation. These scenarios require the capabilities in accurate sensing, efficient communication and flexible control for real-time and reliable task execution. However, sensing, communication and control are studied independently in traditional research, which limits the overall performance of UAV swarms. To overcome this disadvantage, we propose a deeply coupled scheme of integrated sensing, communication and control (ISCC) for UAV swarms, which is a systemic paradigm that transcends traditional isolated designs of sensing, communication and control by establishing a tightly-coupled closed-loop through the co-optimization of sensing, communication and control. In this article, we firstly analyze the requirements of scenarios and key performance metrics. Subsequently, the enabling technologies are proposed, including communication-and-control-enhanced sensing, sensing-and-control-enhanced communication, and sensing-and-communication-enhanced control. Simulation results validate the performance of the proposed ISCC framework, demonstrating its application potential in the future.
Beyond Target-Level: ISAC-Enabled Event-Level Sensing for Behavioral Intention Prediction
Jan 17, 2026Integrated Sensing and Communication (ISAC) holds great promise for enabling event-level sensing, such as behavioral intention prediction (BIP) in autonomous driving, particularly under non-line-of-sight (NLoS) or adverse weather conditions where conventional sensors degrade. However, as a key instance of event-level sensing, ISAC-based BIP remains unexplored. To address this gap, we propose an ISAC-enabled BIP framework and validate its feasibility and effectiveness through extensive simulations. Our framework achieves robust performance in safety-critical scenarios, improving the F1-score by 11.4% over sensor-based baselines in adverse weather, thereby demonstrating ISAC's potential for intelligent event-level sensing.
Near-field Target Localization: Effect of Hardware Impairments
Dec 25, 2025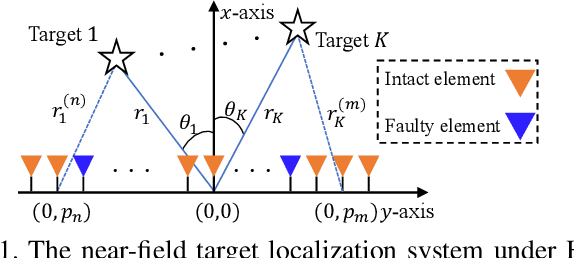
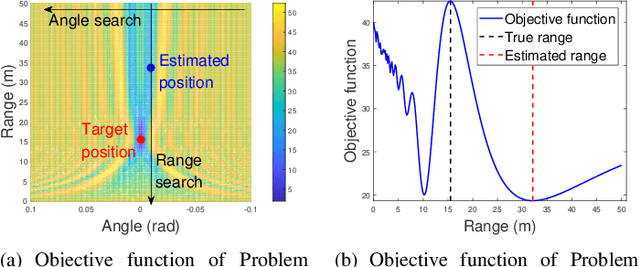
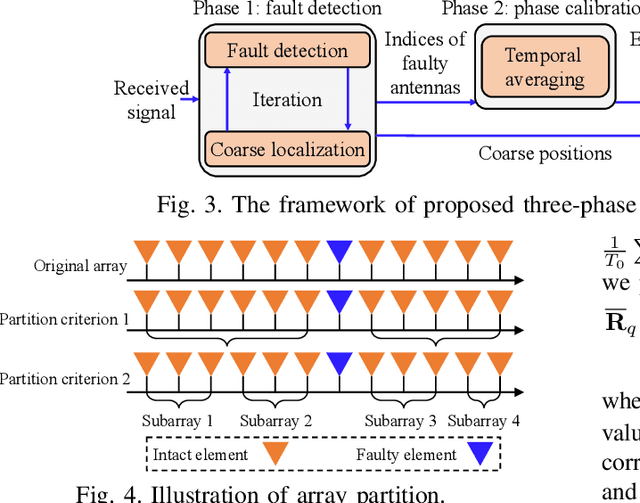
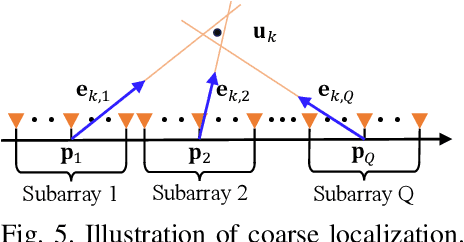
The prior works on near-field target localization have mostly assumed ideal hardware models and thus suffer from two limitations in practice. First, extremely large-scale arrays (XL-arrays) usually face a variety of hardware impairments (HIs) that may introduce unknown phase and/or amplitude errors. Second, the existing block coordinate descent (BCD)-based methods for joint estimation of the HI indicator, channel gain, angle, and range may induce considerable target localization error when the target is very close to the XL-array. To address these issues, we propose in this paper a new three-phase HI-aware near-field localization method, by efficiently detecting faulty antennas and estimating the positions of targets. Specifically, we first determine faulty antennas by using compressed sensing (CS) methods and improve detection accuracy based on coarse target localization. Then, a dedicated phase calibration method is designed to correct phase errors induced by detected faulty antennas. Subsequently, an efficient near-field localization method is devised to accurately estimate the positions of targets based on the full XL-array with phase calibration. Additionally, we resort to the misspecified Cramer-Rao bound (MCRB) to quantify the performance loss caused by HIs. Last, numerical results demonstrate that our proposed method significantly reduces the localization errors as compared to various benchmark schemes, especially for the case with a short target range and/or a high fault probability.
Integrated Sensing and Communication: Towards Multifunctional Perceptive Network
Oct 16, 2025The capacity-maximization design philosophy has driven the growth of wireless networks for decades. However, with the slowdown in recent data traffic demand, the mobile industry can no longer rely solely on communication services to sustain development. In response, Integrated Sensing and Communications (ISAC) has emerged as a transformative solution, embedding sensing capabilities into communication networks to enable multifunctional wireless systems. This paradigm shift expands the role of networks from sole data transmission to versatile platforms supporting diverse applications. In this review, we provide a bird's-eye view of ISAC for new researchers, highlighting key challenges, opportunities, and application scenarios to guide future exploration in this field.
One Prompt Fits All: Universal Graph Adaptation for Pretrained Models
Sep 26, 2025Graph Prompt Learning (GPL) has emerged as a promising paradigm that bridges graph pretraining models and downstream scenarios, mitigating label dependency and the misalignment between upstream pretraining and downstream tasks. Although existing GPL studies explore various prompt strategies, their effectiveness and underlying principles remain unclear. We identify two critical limitations: (1) Lack of consensus on underlying mechanisms: Despite current GPLs have advanced the field, there is no consensus on how prompts interact with pretrained models, as different strategies intervene at varying spaces within the model, i.e., input-level, layer-wise, and representation-level prompts. (2) Limited scenario adaptability: Most methods fail to generalize across diverse downstream scenarios, especially under data distribution shifts (e.g., homophilic-to-heterophilic graphs). To address these issues, we theoretically analyze existing GPL approaches and reveal that representation-level prompts essentially function as fine-tuning a simple downstream classifier, proposing that graph prompt learning should focus on unleashing the capability of pretrained models, and the classifier adapts to downstream scenarios. Based on our findings, we propose UniPrompt, a novel GPL method that adapts any pretrained models, unleashing the capability of pretrained models while preserving the structure of the input graph. Extensive experiments demonstrate that our method can effectively integrate with various pretrained models and achieve strong performance across in-domain and cross-domain scenarios.