 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefProtoFL: Communication-Efficient Federated Learning via External-Referenced Prototype Alignment
Jan 21, 2026Federated learning (FL) enables collaborative model training without sharing raw data in edge environments, but is constrained by limited communication bandwidth and heterogeneous client data distributions. Prototype-based FL mitigates this issue by exchanging class-wise feature prototypes instead of full model parameters; however, existing methods still suffer from suboptimal generalization under severe communication constraints. In this paper, we propose RefProtoFL, a communication-efficient FL framework that integrates External-Referenced Prototype Alignment (ERPA) for representation consistency with Adaptive Probabilistic Update Dropping (APUD) for communication efficiency. Specifically, we decompose the model into a private backbone and a lightweight shared adapter, and restrict federated communication to the adapter parameters only. To further reduce uplink cost, APUD performs magnitude-aware Top-K sparsification, transmitting only the most significant adapter updates for server-side aggregation. To address representation inconsistency across heterogeneous clients, ERPA leverages a small server-held public dataset to construct external reference prototypes that serve as shared semantic anchors. For classes covered by public data, clients directly align local representations to public-induced prototypes, whereas for uncovered classes, alignment relies on server-aggregated global reference prototypes via weighted averaging. Extensive experiments on standard benchmarks demonstrate that RefProtoFL attains higher classification accuracy than state-of-the-art prototype-based FL baselines.
Efficient Federated Learning with Encrypted Data Sharing for Data-Heterogeneous Edge Devices
Jun 25, 2025As privacy protection gains increasing importance, more models are being trained on edge devices and subsequently merged into the central server through Federated Learning (FL). However, current research overlooks the impact of network topology, physical distance, and data heterogeneity on edge devices, leading to issues such as increased latency and degraded model performance. To address these issues, we propose a new federated learning scheme on edge devices that called Federated Learning with Encrypted Data Sharing(FedEDS). FedEDS uses the client model and the model's stochastic layer to train the data encryptor. The data encryptor generates encrypted data and shares it with other clients. The client uses the corresponding client's stochastic layer and encrypted data to train and adjust the local model. FedEDS uses the client's local private data and encrypted shared data from other clients to train the model. This approach accelerates the convergence speed of federated learning training and mitigates the negative impact of data heterogeneity, making it suitable for application services deployed on edge devices requiring rapid convergence. Experiments results show the efficacy of FedEDS in promoting model performance.
FairSort: Learning to Fair Rank for Personalized Recommendations in Two-Sided Platforms
Nov 30, 2024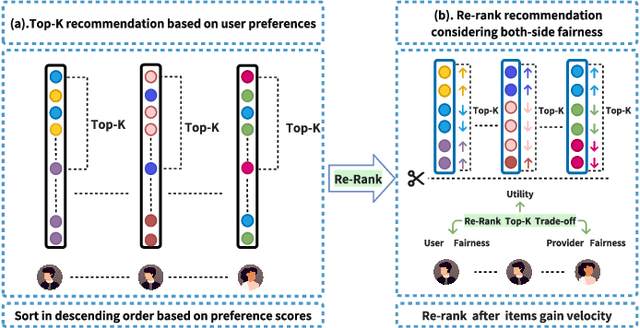

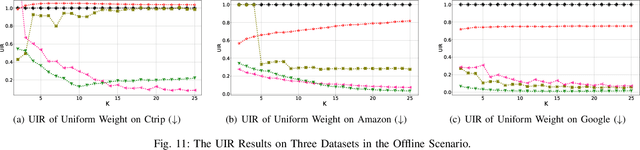
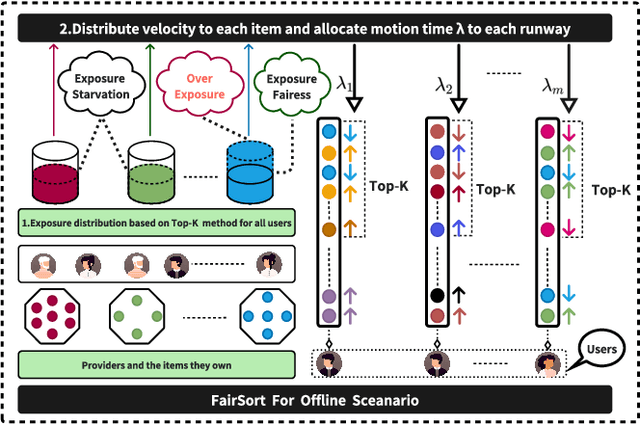
Traditional recommendation systems focus on maximizing user satisfaction by suggesting their favorite items. This user-centric approach may lead to unfair exposure distribution among the providers. On the contrary, a provider-centric design might become unfair to the users. Therefore, this paper proposes a re-ranking model FairSort\footnote{\textbf{Reproducibility:}The code and datasets are available at \url{https://github.com/13543024276/FairSort}} to find a trade-off solution among user-side fairness, provider-side fairness, and personalized recommendations utility. Previous works habitually treat this issue as a knapsack problem, incorporating both-side fairness as constraints. In this paper, we adopt a novel perspective, treating each recommendation list as a runway rather than a knapsack. In this perspective, each item on the runway gains a velocity and runs within a specific time, achieving re-ranking for both-side fairness. Meanwhile, we ensure the Minimum Utility Guarantee for personalized recommendations by designing a Binary Search approach. This can provide more reliable recommendations compared to the conventional greedy strategy based on the knapsack problem. We further broaden the applicability of FairSort, designing two versions for online and offline recommendation scenarios. Theoretical analysis and extensive experiments on real-world datasets indicate that FairSort can ensure more reliable personalized recommendations while considering fairness for both the provider and user.