 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Representation for Interactive Recommendation
Dec 24, 2024



Interactive Recommendation (IR) has gained significant attention recently for its capability to quickly capture dynamic interest and optimize both short and long term objectives. IR agents are typically implemented through Deep Reinforcement Learning (DRL), because DRL is inherently compatible with the dynamic nature of IR. However, DRL is currently not perfect for IR. Due to the large action space and sample inefficiency problem, training DRL recommender agents is challenging. The key point is that useful features cannot be extracted as high-quality representations for the recommender agent to optimize its policy. To tackle this problem, we propose Contrastive Representation for Interactive Recommendation (CRIR). CRIR efficiently extracts latent, high-level preference ranking features from explicit interaction, and leverages the features to enhance users' representation. Specifically, the CRIR provides representation through one representation network, and refines it through our proposed Preference Ranking Contrastive Learning (PRCL). The key insight of PRCL is that it can perform contrastive learning without relying on computations involving high-level representations or large potential action sets. Furthermore, we also propose a data exploiting mechanism and an agent training mechanism to better adapt CRIR to the DRL backbone. Extensive experiments have been carried out to show our method's superior improvement on the sample efficiency while training an DRL-based IR agent.
FairSort: Learning to Fair Rank for Personalized Recommendations in Two-Sided Platforms
Nov 30, 2024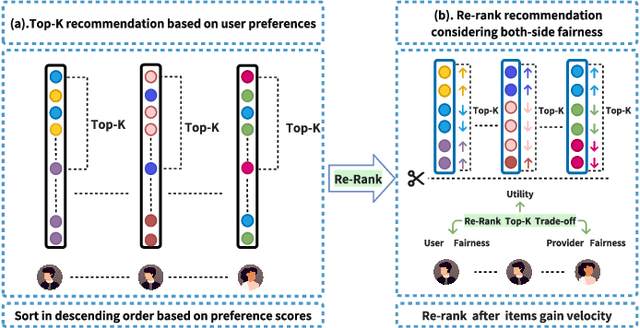

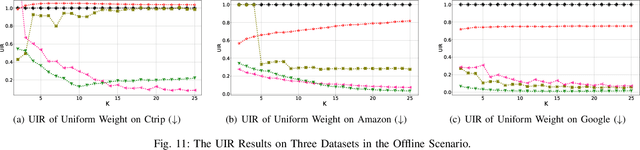
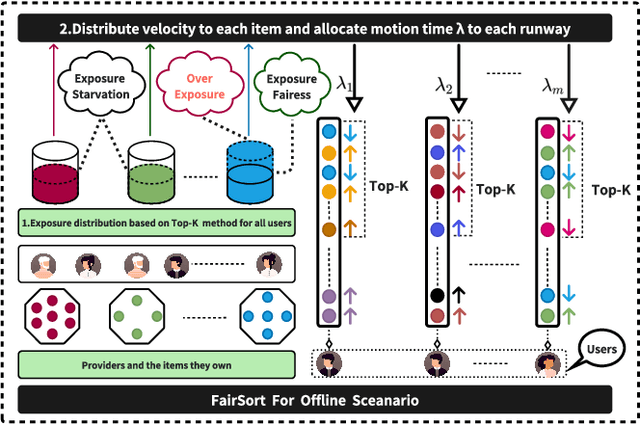
Traditional recommendation systems focus on maximizing user satisfaction by suggesting their favorite items. This user-centric approach may lead to unfair exposure distribution among the providers. On the contrary, a provider-centric design might become unfair to the users. Therefore, this paper proposes a re-ranking model FairSort\footnote{\textbf{Reproducibility:}The code and datasets are available at \url{https://github.com/13543024276/FairSort}} to find a trade-off solution among user-side fairness, provider-side fairness, and personalized recommendations utility. Previous works habitually treat this issue as a knapsack problem, incorporating both-side fairness as constraints. In this paper, we adopt a novel perspective, treating each recommendation list as a runway rather than a knapsack. In this perspective, each item on the runway gains a velocity and runs within a specific time, achieving re-ranking for both-side fairness. Meanwhile, we ensure the Minimum Utility Guarantee for personalized recommendations by designing a Binary Search approach. This can provide more reliable recommendations compared to the conventional greedy strategy based on the knapsack problem. We further broaden the applicability of FairSort, designing two versions for online and offline recommendation scenarios. Theoretical analysis and extensive experiments on real-world datasets indicate that FairSort can ensure more reliable personalized recommendations while considering fairness for both the provider and user.