 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefProtoFL: Communication-Efficient Federated Learning via External-Referenced Prototype Alignment
Jan 21, 2026Federated learning (FL) enables collaborative model training without sharing raw data in edge environments, but is constrained by limited communication bandwidth and heterogeneous client data distributions. Prototype-based FL mitigates this issue by exchanging class-wise feature prototypes instead of full model parameters; however, existing methods still suffer from suboptimal generalization under severe communication constraints. In this paper, we propose RefProtoFL, a communication-efficient FL framework that integrates External-Referenced Prototype Alignment (ERPA) for representation consistency with Adaptive Probabilistic Update Dropping (APUD) for communication efficiency. Specifically, we decompose the model into a private backbone and a lightweight shared adapter, and restrict federated communication to the adapter parameters only. To further reduce uplink cost, APUD performs magnitude-aware Top-K sparsification, transmitting only the most significant adapter updates for server-side aggregation. To address representation inconsistency across heterogeneous clients, ERPA leverages a small server-held public dataset to construct external reference prototypes that serve as shared semantic anchors. For classes covered by public data, clients directly align local representations to public-induced prototypes, whereas for uncovered classes, alignment relies on server-aggregated global reference prototypes via weighted averaging. Extensive experiments on standard benchmarks demonstrate that RefProtoFL attains higher classification accuracy than state-of-the-art prototype-based FL baselines.
CATS-V2V: A Real-World Vehicle-to-Vehicle Cooperative Perception Dataset with Complex Adverse Traffic Scenarios
Nov 14, 2025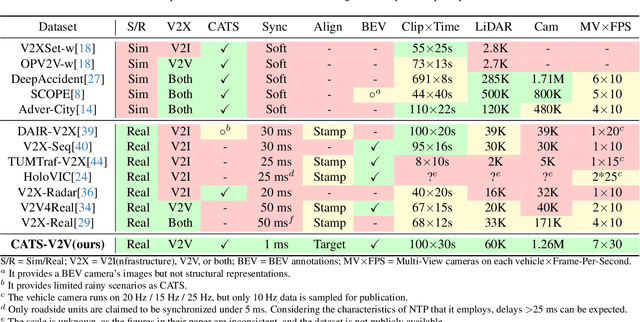


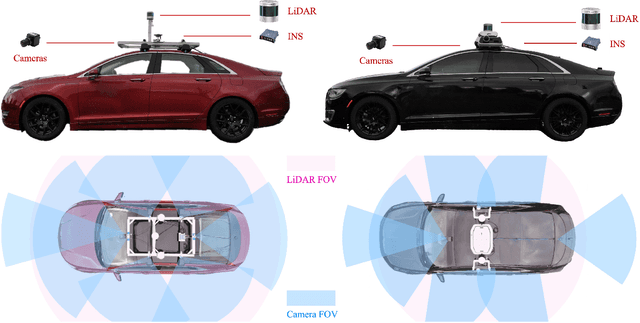
Vehicle-to-Vehicle (V2V) cooperative perception has great potential to enhance autonomous driving performance by overcoming perception limitations in complex adverse traffic scenarios (CATS). Meanwhile, data serves as the fundamental infrastructure for modern autonomous driving AI. However, due to stringent data collection requirements, existing datasets focus primarily on ordinary traffic scenarios, constraining the benefits of cooperative perception. To address this challenge, we introduce CATS-V2V, the first-of-its-kind real-world dataset for V2V cooperative perception under complex adverse traffic scenarios. The dataset was collected by two hardware time-synchronized vehicles, covering 10 weather and lighting conditions across 10 diverse locations. The 100-clip dataset includes 60K frames of 10 Hz LiDAR point clouds and 1.26M multi-view 30 Hz camera images, along with 750K anonymized yet high-precision RTK-fixed GNSS and IMU records. Correspondingly, we provide time-consistent 3D bounding box annotations for objects, as well as static scenes to construct a 4D BEV representation. On this basis, we propose a target-based temporal alignment method, ensuring that all objects are precisely aligned across all sensor modalities. We hope that CATS-V2V, the largest-scale, most supportive, and highest-quality dataset of its kind to date, will benefit the autonomous driving community in related tasks.
Efficient Federated Learning with Encrypted Data Sharing for Data-Heterogeneous Edge Devices
Jun 25, 2025As privacy protection gains increasing importance, more models are being trained on edge devices and subsequently merged into the central server through Federated Learning (FL). However, current research overlooks the impact of network topology, physical distance, and data heterogeneity on edge devices, leading to issues such as increased latency and degraded model performance. To address these issues, we propose a new federated learning scheme on edge devices that called Federated Learning with Encrypted Data Sharing(FedEDS). FedEDS uses the client model and the model's stochastic layer to train the data encryptor. The data encryptor generates encrypted data and shares it with other clients. The client uses the corresponding client's stochastic layer and encrypted data to train and adjust the local model. FedEDS uses the client's local private data and encrypted shared data from other clients to train the model. This approach accelerates the convergence speed of federated learning training and mitigates the negative impact of data heterogeneity, making it suitable for application services deployed on edge devices requiring rapid convergence. Experiments results show the efficacy of FedEDS in promoting model performance.
Reverse Preference Optimization for Complex Instruction Following
May 28, 2025Instruction following (IF) is a critical capability for large language models (LLMs). However, handling complex instructions with multiple constraints remains challenging. Previous methods typically select preference pairs based on the number of constraints they satisfy, introducing noise where chosen examples may fail to follow some constraints and rejected examples may excel in certain respects over the chosen ones. To address the challenge of aligning with multiple preferences, we propose a simple yet effective method called Reverse Preference Optimization (RPO). It mitigates noise in preference pairs by dynamically reversing the constraints within the instruction to ensure the chosen response is perfect, alleviating the burden of extensive sampling and filtering to collect perfect responses. Besides, reversal also enlarges the gap between chosen and rejected responses, thereby clarifying the optimization direction and making it more robust to noise. We evaluate RPO on two multi-turn IF benchmarks, Sysbench and Multi-IF, demonstrating average improvements over the DPO baseline of 4.6 and 2.5 points (on Llama-3.1 8B), respectively. Moreover, RPO scales effectively across model sizes (8B to 70B parameters), with the 70B RPO model surpassing GPT-4o.
TeleOpBench: A Simulator-Centric Benchmark for Dual-Arm Dexterous Teleoperation
May 19, 2025Teleoperation is a cornerstone of embodied-robot learning, and bimanual dexterous teleoperation in particular provides rich demonstrations that are difficult to obtain with fully autonomous systems. While recent studies have proposed diverse hardware pipelines-ranging from inertial motion-capture gloves to exoskeletons and vision-based interfaces-there is still no unified benchmark that enables fair, reproducible comparison of these systems. In this paper, we introduce TeleOpBench, a simulator-centric benchmark tailored to bimanual dexterous teleoperation. TeleOpBench contains 30 high-fidelity task environments that span pick-and-place, tool use, and collaborative manipulation, covering a broad spectrum of kinematic and force-interaction difficulty. Within this benchmark we implement four representative teleoperation modalities-(i) MoCap, (ii) VR device, (iii) arm-hand exoskeletons, and (iv) monocular vision tracking-and evaluate them with a common protocol and metric suite. To validate that performance in simulation is predictive of real-world behavior, we conduct mirrored experiments on a physical dual-arm platform equipped with two 6-DoF dexterous hands. Across 10 held-out tasks we observe a strong correlation between simulator and hardware performance, confirming the external validity of TeleOpBench. TeleOpBench establishes a common yardstick for teleoperation research and provides an extensible platform for future algorithmic and hardware innovation.
VMBench: A Benchmark for Perception-Aligned Video Motion Generation
Mar 13, 2025



Video generation has advanced rapidly, improving evaluation methods, yet assessing video's motion remains a major challenge. Specifically, there are two key issues: 1) current motion metrics do not fully align with human perceptions; 2) the existing motion prompts are limited. Based on these findings, we introduce VMBench--a comprehensive Video Motion Benchmark that has perception-aligned motion metrics and features the most diverse types of motion. VMBench has several appealing properties: 1) Perception-Driven Motion Evaluation Metrics, we identify five dimensions based on human perception in motion video assessment and develop fine-grained evaluation metrics, providing deeper insights into models' strengths and weaknesses in motion quality. 2) Meta-Guided Motion Prompt Generation, a structured method that extracts meta-information, generates diverse motion prompts with LLMs, and refines them through human-AI validation, resulting in a multi-level prompt library covering six key dynamic scene dimensions. 3) Human-Aligned Validation Mechanism, we provide human preference annotations to validate our benchmarks, with our metrics achieving an average 35.3% improvement in Spearman's correlation over baseline methods. This is the first time that the quality of motion in videos has been evaluated from the perspective of human perception alignment. Additionally, we will soon release VMBench at https://github.com/GD-AIGC/VMBench, setting a new standard for evaluating and advancing motion generation models.
Prioritize Denoising Steps on Diffusion Model Preference Alignment via Explicit Denoised Distribution Estimation
Nov 22, 2024


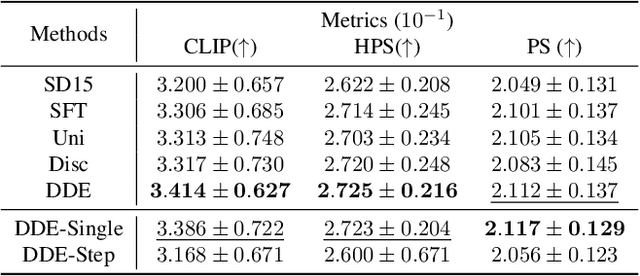
Diffusion models have shown remarkable success in text-to-image generation, making alignment methods for these models increasingly important. A key challenge is the sparsity of preference labels, which are typically available only at the terminal of denoising trajectories. This raises the issue of how to assign credit across denoising steps based on these sparse labels. In this paper, we propose Denoised Distribution Estimation (DDE), a novel method for credit assignment. Unlike previous approaches that rely on auxiliary models or hand-crafted schemes, DDE derives its strategy more explicitly. The proposed DDE directly estimates the terminal denoised distribution from the perspective of each step. It is equipped with two estimation strategies and capable of representing the entire denoising trajectory with a single model inference. Theoretically and empirically, we show that DDE prioritizes optimizing the middle part of the denoising trajectory, resulting in a novel and effective credit assignment scheme. Extensive experiments demonstrate that our approach achieves superior performance, both quantitatively and qualitatively.
Knowledge-Enhanced Facial Expression Recognition with Emotional-to-Neutral Transformation
Sep 13, 2024



Existing facial expression recognition (FER) methods typically fine-tune a pre-trained visual encoder using discrete labels. However, this form of supervision limits to specify the emotional concept of different facial expressions. In this paper, we observe that the rich knowledge in text embeddings, generated by vision-language models, is a promising alternative for learning discriminative facial expression representations. Inspired by this, we propose a novel knowledge-enhanced FER method with an emotional-to-neutral transformation. Specifically, we formulate the FER problem as a process to match the similarity between a facial expression representation and text embeddings. Then, we transform the facial expression representation to a neutral representation by simulating the difference in text embeddings from textual facial expression to textual neutral. Finally, a self-contrast objective is introduced to pull the facial expression representation closer to the textual facial expression, while pushing it farther from the neutral representation. We conduct evaluation with diverse pre-trained visual encoders including ResNet-18 and Swin-T on four challenging facial expression datasets. Extensive experiments demonstrate that our method significantly outperforms state-of-the-art FER methods. The code will be publicly available.
EvLight++: Low-Light Video Enhancement with an Event Camera: A Large-Scale Real-World Dataset, Novel Method, and More
Aug 29, 2024



Event cameras offer significant advantages for low-light video enhancement, primarily due to their high dynamic range. Current research, however, is severely limited by the absence of large-scale, real-world, and spatio-temporally aligned event-video datasets. To address this, we introduce a large-scale dataset with over 30,000 pairs of frames and events captured under varying illumination. This dataset was curated using a robotic arm that traces a consistent non-linear trajectory, achieving spatial alignment precision under 0.03mm and temporal alignment with errors under 0.01s for 90% of the dataset. Based on the dataset, we propose \textbf{EvLight++}, a novel event-guided low-light video enhancement approach designed for robust performance in real-world scenarios. Firstly, we design a multi-scale holistic fusion branch to integrate structural and textural information from both images and events. To counteract variations in regional illumination and noise, we introduce Signal-to-Noise Ratio (SNR)-guided regional feature selection, enhancing features from high SNR regions and augmenting those from low SNR regions by extracting structural information from events. To incorporate temporal information and ensure temporal coherence, we further introduce a recurrent module and temporal loss in the whole pipeline. Extensive experiments on our and the synthetic SDSD dataset demonstrate that EvLight++ significantly outperforms both single image- and video-based methods by 1.37 dB and 3.71 dB, respectively. To further explore its potential in downstream tasks like semantic segmentation and monocular depth estimation, we extend our datasets by adding pseudo segmentation and depth labels via meticulous annotation efforts with foundation models. Experiments under diverse low-light scenes show that the enhanced results achieve a 15.97% improvement in mIoU for semantic segmentation.
DreamCouple: Exploring High Quality Text-to-3D Generation Via Rectified Flow
Aug 09, 2024The Score Distillation Sampling (SDS), which exploits pretrained text-to-image model diffusion models as priors to 3D model training, has achieved significant success. Currently, the flow-based diffusion model has become a new trend for generations. Yet, adapting SDS to flow-based diffusion models in 3D generation remains unexplored. Our work is aimed to bridge this gap. In this paper, we adapt SDS to rectified flow and re-examine the over-smoothing issue under this novel framework. The issue can be explained that the model learns an average of multiple ODE trajectories. Then we propose DreamCouple, which instead of randomly sampling noise, uses a rectified flow model to find the coupled noise. Its Unique Couple Matching (UCM) loss guides the model to learn different trajectories and thus solves the over-smoothing issue. We apply our method to both NeRF and 3D Gaussian splatting and achieve state-of-the-art performances. We also identify some other interesting open questions such as initialization issues for NeRF and faster training convergence. Our code will be released soon.