 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt Guidance and Human Proximal Perception for HOT Prediction with Regional Joint Loss
Jul 02, 2025The task of Human-Object conTact (HOT) detection involves identifying the specific areas of the human body that are touching objects. Nevertheless, current models are restricted to just one type of image, often leading to too much segmentation in areas with little interaction, and struggling to maintain category consistency within specific regions. To tackle this issue, a HOT framework, termed \textbf{P3HOT}, is proposed, which blends \textbf{P}rompt guidance and human \textbf{P}roximal \textbf{P}erception. To begin with, we utilize a semantic-driven prompt mechanism to direct the network's attention towards the relevant regions based on the correlation between image and text. Then a human proximal perception mechanism is employed to dynamically perceive key depth range around the human, using learnable parameters to effectively eliminate regions where interactions are not expected. Calculating depth resolves the uncertainty of the overlap between humans and objects in a 2D perspective, providing a quasi-3D viewpoint. Moreover, a Regional Joint Loss (RJLoss) has been created as a new loss to inhibit abnormal categories in the same area. A new evaluation metric called ``AD-Acc.'' is introduced to address the shortcomings of existing methods in addressing negative samples. Comprehensive experimental results demonstrate that our approach achieves state-of-the-art performance in four metrics across two benchmark datasets. Specifically, our model achieves an improvement of \textbf{0.7}$\uparrow$, \textbf{2.0}$\uparrow$, \textbf{1.6}$\uparrow$, and \textbf{11.0}$\uparrow$ in SC-Acc., mIoU, wIoU, and AD-Acc. metrics, respectively, on the HOT-Annotated dataset. Code is available at https://github.com/YuxiaoWang-AI/P3HOT.
TeleOpBench: A Simulator-Centric Benchmark for Dual-Arm Dexterous Teleoperation
May 19, 2025Teleoperation is a cornerstone of embodied-robot learning, and bimanual dexterous teleoperation in particular provides rich demonstrations that are difficult to obtain with fully autonomous systems. While recent studies have proposed diverse hardware pipelines-ranging from inertial motion-capture gloves to exoskeletons and vision-based interfaces-there is still no unified benchmark that enables fair, reproducible comparison of these systems. In this paper, we introduce TeleOpBench, a simulator-centric benchmark tailored to bimanual dexterous teleoperation. TeleOpBench contains 30 high-fidelity task environments that span pick-and-place, tool use, and collaborative manipulation, covering a broad spectrum of kinematic and force-interaction difficulty. Within this benchmark we implement four representative teleoperation modalities-(i) MoCap, (ii) VR device, (iii) arm-hand exoskeletons, and (iv) monocular vision tracking-and evaluate them with a common protocol and metric suite. To validate that performance in simulation is predictive of real-world behavior, we conduct mirrored experiments on a physical dual-arm platform equipped with two 6-DoF dexterous hands. Across 10 held-out tasks we observe a strong correlation between simulator and hardware performance, confirming the external validity of TeleOpBench. TeleOpBench establishes a common yardstick for teleoperation research and provides an extensible platform for future algorithmic and hardware innovation.
Precision-Enhanced Human-Object Contact Detection via Depth-Aware Perspective Interaction and Object Texture Restoration
Dec 13, 2024



Human-object contact (HOT) is designed to accurately identify the areas where humans and objects come into contact. Current methods frequently fail to account for scenarios where objects are frequently blocking the view, resulting in inaccurate identification of contact areas. To tackle this problem, we suggest using a perspective interaction HOT detector called PIHOT, which utilizes a depth map generation model to offer depth information of humans and objects related to the camera, thereby preventing false interaction detection. Furthermore, we use mask dilatation and object restoration techniques to restore the texture details in covered areas, improve the boundaries between objects, and enhance the perception of humans interacting with objects. Moreover, a spatial awareness perception is intended to concentrate on the characteristic features close to the points of contact. The experimental results show that the PIHOT algorithm achieves state-of-the-art performance on three benchmark datasets for HOT detection tasks. Compared to the most recent DHOT, our method enjoys an average improvement of 13%, 27.5%, 16%, and 18.5% on SC-Acc., C-Acc., mIoU, and wIoU metrics, respectively.
DRiVE: Diffusion-based Rigging Empowers Generation of Versatile and Expressive Characters
Nov 26, 2024


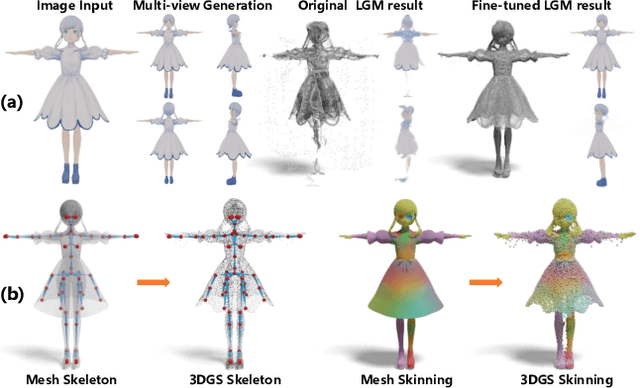
Recent advances in generative models have enabled high-quality 3D character reconstruction from multi-modal. However, animating these generated characters remains a challenging task, especially for complex elements like garments and hair, due to the lack of large-scale datasets and effective rigging methods. To address this gap, we curate AnimeRig, a large-scale dataset with detailed skeleton and skinning annotations. Building upon this, we propose DRiVE, a novel framework for generating and rigging 3D human characters with intricate structures. Unlike existing methods, DRiVE utilizes a 3D Gaussian representation, facilitating efficient animation and high-quality rendering. We further introduce GSDiff, a 3D Gaussian-based diffusion module that predicts joint positions as spatial distributions, overcoming the limitations of regression-based approaches. Extensive experiments demonstrate that DRiVE achieves precise rigging results, enabling realistic dynamics for clothing and hair, and surpassing previous methods in both quality and versatility. The code and dataset will be made public for academic use upon acceptance.
City-LEO: Toward Transparent City Management Using LLM with End-to-End Optimization
Jun 18, 2024Existing operations research (OR) models and tools play indispensable roles in smart-city operations, yet their practical implementation is limited by the complexity of modeling and deficiencies in optimization proficiency. To generate more relevant and accurate solutions to users' requirements, we propose a large language model (LLM)-based agent ("City-LEO") that enhances the efficiency and transparency of city management through conversational interactions. Specifically, to accommodate diverse users' requirements and enhance computational tractability, City-LEO leverages LLM's logical reasoning capabilities on prior knowledge to scope down large-scale optimization problems efficiently. In the human-like decision process, City-LEO also incorporates End-to-end (E2E) model to synergize the prediction and optimization. The E2E framework be conducive to coping with environmental uncertainties and involving more query-relevant features, and then facilitates transparent and interpretable decision-making process. In case study, we employ City-LEO in the operations management of e-bike sharing (EBS) system. The numerical results demonstrate that City-LEO has superior performance when benchmarks against the full-scale optimization problem. With less computational time, City-LEO generates more satisfactory and relevant solutions to the users' requirements, and achieves lower global suboptimality without significantly compromising accuracy. In a broader sense, our proposed agent offers promise to develop LLM-embedded OR tools for smart-city operations management.
Beyond Talking -- Generating Holistic 3D Human Dyadic Motion for Communication
Mar 28, 2024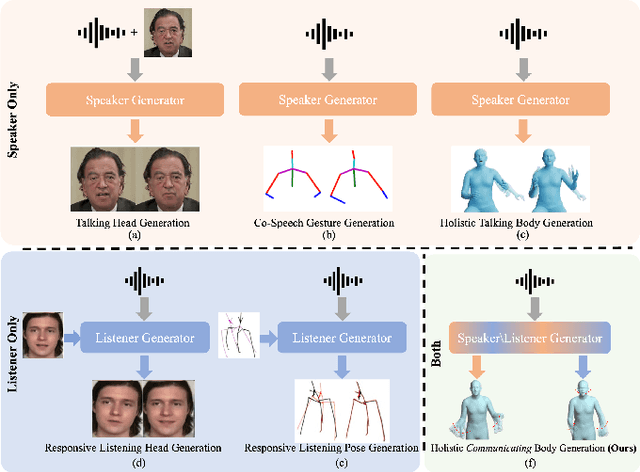

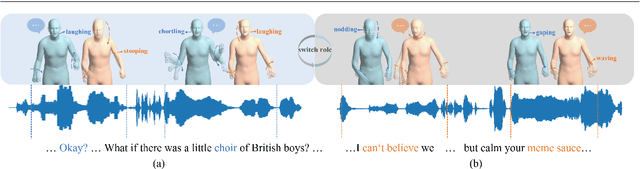
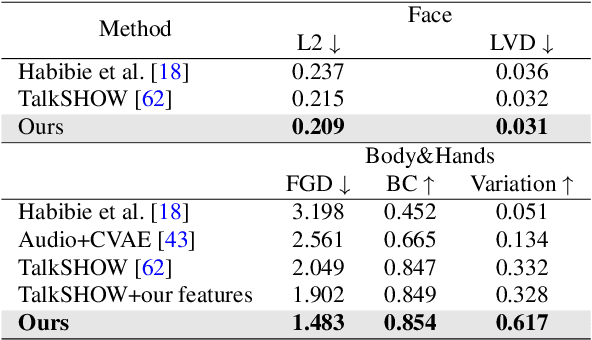
In this paper, we introduce an innovative task focused on human communication, aiming to generate 3D holistic human motions for both speakers and listeners. Central to our approach is the incorporation of factorization to decouple audio features and the combination of textual semantic information, thereby facilitating the creation of more realistic and coordinated movements. We separately train VQ-VAEs with respect to the holistic motions of both speaker and listener. We consider the real-time mutual influence between the speaker and the listener and propose a novel chain-like transformer-based auto-regressive model specifically designed to characterize real-world communication scenarios effectively which can generate the motions of both the speaker and the listener simultaneously. These designs ensure that the results we generate are both coordinated and diverse. Our approach demonstrates state-of-the-art performance on two benchmark datasets. Furthermore, we introduce the HoCo holistic communication dataset, which is a valuable resource for future research. Our HoCo dataset and code will be released for research purposes upon acceptance.
Federated Joint Learning of Robot Networks in Stroke Rehabilitation
Mar 08, 2024



Advanced by rich perception and precise execution, robots possess immense potential to provide professional and customized rehabilitation exercises for patients with mobility impairments caused by strokes. Autonomous robotic rehabilitation significantly reduces human workloads in the long and tedious rehabilitation process. However, training a rehabilitation robot is challenging due to the data scarcity issue. This challenge arises from privacy concerns (e.g., the risk of leaking private disease and identity information of patients) during clinical data access and usage. Data from various patients and hospitals cannot be shared for adequate robot training, further compromising rehabilitation safety and limiting implementation scopes. To address this challenge, this work developed a novel federated joint learning (FJL) method to jointly train robots across hospitals. FJL also adopted a long short-term memory network (LSTM)-Transformer learning mechanism to effectively explore the complex tempo-spatial relations among patient mobility conditions and robotic rehabilitation motions. To validate FJL's effectiveness in training a robot network, a clinic-simulation combined experiment was designed. Real rehabilitation exercise data from 200 patients with stroke diseases (upper limb hemiplegia, Parkinson's syndrome, and back pain syndrome) were adopted. Inversely driven by clinical data, 300,000 robotic rehabilitation guidances were simulated. FJL proved to be effective in joint rehabilitation learning, performing 20% - 30% better than baseline methods.
FreeA: Human-object Interaction Detection using Free Annotation Labels
Mar 04, 2024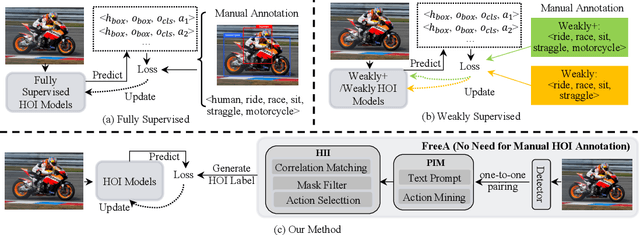
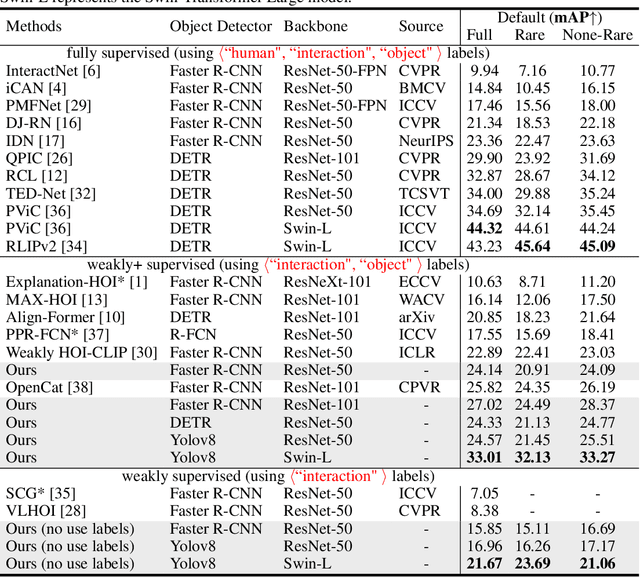
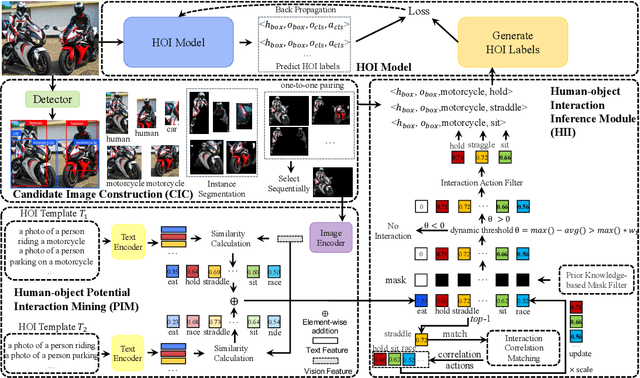
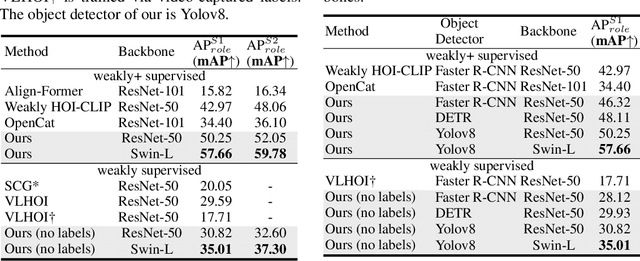
Recent human-object interaction (HOI) detection approaches rely on high cost of manpower and require comprehensive annotated image datasets. In this paper, we propose a novel self-adaption language-driven HOI detection method, termed as FreeA, without labeling by leveraging the adaptability of CLIP to generate latent HOI labels. To be specific, FreeA matches image features of human-object pairs with HOI text templates, and a priori knowledge-based mask method is developed to suppress improbable interactions. In addition, FreeA utilizes the proposed interaction correlation matching method to enhance the likelihood of actions related to a specified action, further refine the generated HOI labels. Experiments on two benchmark datasets show that FreeA achieves state-of-the-art performance among weakly supervised HOI models. Our approach is +8.58 mean Average Precision (mAP) on HICO-DET and +1.23 mAP on V-COCO more accurate in localizing and classifying the interactive actions than the newest weakly model, and +1.68 mAP and +7.28 mAP than the latest weakly+ model, respectively. Code will be available at https://drliuqi.github.io/.
Spotlights: Probing Shapes from Spherical Viewpoints
May 25, 2022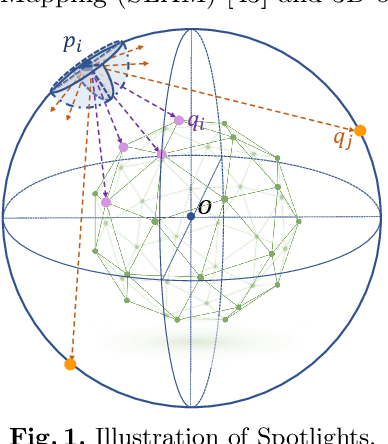
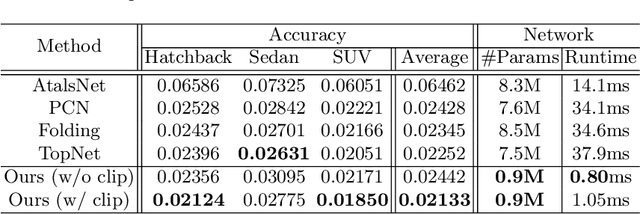
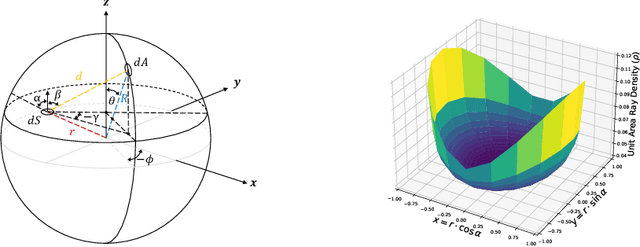
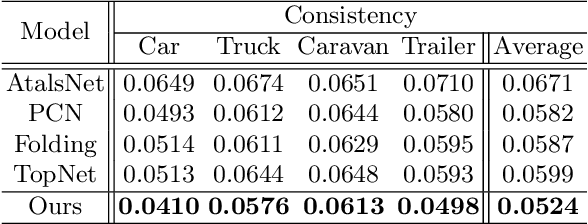
Recent years have witnessed the surge of learned representations that directly build upon point clouds. Though becoming increasingly expressive, most existing representations still struggle to generate ordered point sets. Inspired by spherical multi-view scanners, we propose a novel sampling model called Spotlights to represent a 3D shape as a compact 1D array of depth values. It simulates the configuration of cameras evenly distributed on a sphere, where each virtual camera casts light rays from its principal point through sample points on a small concentric spherical cap to probe for the possible intersections with the object surrounded by the sphere. The structured point cloud is hence given implicitly as a function of depths. We provide a detailed geometric analysis of this new sampling scheme and prove its effectiveness in the context of the point cloud completion task. Experimental results on both synthetic and real data demonstrate that our method achieves competitive accuracy and consistency while having a significantly reduced computational cost. Furthermore, we show superior performance on the downstream point cloud registration task over state-of-the-art completion methods.
S3E-GNN: Sparse Spatial Scene Embedding with Graph Neural Networks for Camera Relocalization
May 12, 2022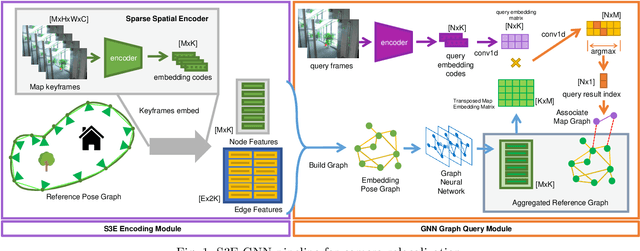
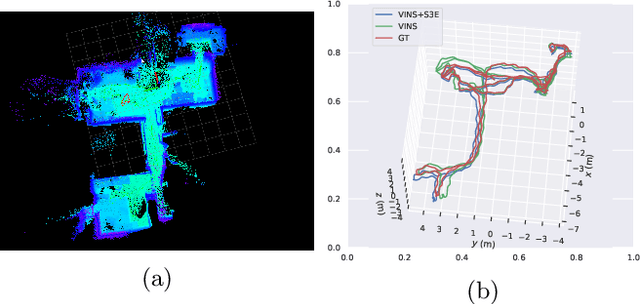
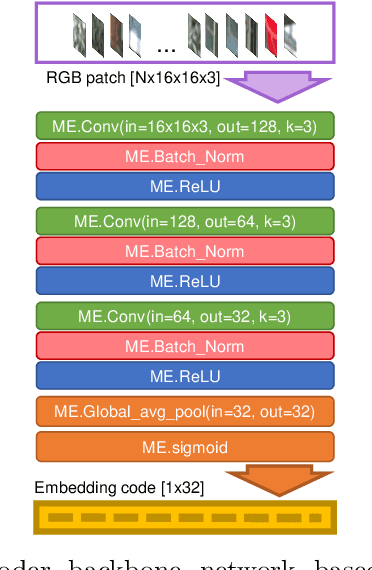
Camera relocalization is the key component of simultaneous localization and mapping (SLAM) systems. This paper proposes a learning-based approach, named Sparse Spatial Scene Embedding with Graph Neural Networks (S3E-GNN), as an end-to-end framework for efficient and robust camera relocalization. S3E-GNN consists of two modules. In the encoding module, a trained S3E network encodes RGB images into embedding codes to implicitly represent spatial and semantic embedding code. With embedding codes and the associated poses obtained from a SLAM system, each image is represented as a graph node in a pose graph. In the GNN query module, the pose graph is transformed to form a embedding-aggregated reference graph for camera relocalization. We collect various scene datasets in the challenging environments to perform experiments. Our results demonstrate that S3E-GNN method outperforms the traditional Bag-of-words (BoW) for camera relocalization due to learning-based embedding and GNN powered scene matching mechanism.