 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Autoregressive Video Generation via Diagonal Distillation
Mar 11, 2026Large pretrained diffusion models have significantly enhanced the quality of generated videos, and yet their use in real-time streaming remains limited. Autoregressive models offer a natural framework for sequential frame synthesis but require heavy computation to achieve high fidelity. Diffusion distillation can compress these models into efficient few-step variants, but existing video distillation approaches largely adapt image-specific methods that neglect temporal dependencies. These techniques often excel in image generation but underperform in video synthesis, exhibiting reduced motion coherence, error accumulation over long sequences, and a latency-quality trade-off. We identify two factors that result in these limitations: insufficient utilization of temporal context during step reduction and implicit prediction of subsequent noise levels in next-chunk prediction (i.e., exposure bias). To address these issues, we propose Diagonal Distillation, which operates orthogonally to existing approaches and better exploits temporal information across both video chunks and denoising steps. Central to our approach is an asymmetric generation strategy: more steps early, fewer steps later. This design allows later chunks to inherit rich appearance information from thoroughly processed early chunks, while using partially denoised chunks as conditional inputs for subsequent synthesis. By aligning the implicit prediction of subsequent noise levels during chunk generation with the actual inference conditions, our approach mitigates error propagation and reduces oversaturation in long-range sequences. We further incorporate implicit optical flow modeling to preserve motion quality under strict step constraints. Our method generates a 5-second video in 2.61 seconds (up to 31 FPS), achieving a 277.3x speedup over the undistilled model.
DynamicScaler: Seamless and Scalable Video Generation for Panoramic Scenes
Dec 15, 2024The increasing demand for immersive AR/VR applications and spatial intelligence has heightened the need to generate high-quality scene-level and 360{\deg} panoramic video. However, most video diffusion models are constrained by limited resolution and aspect ratio, which restricts their applicability to scene-level dynamic content synthesis. In this work, we propose the DynamicScaler, addressing these challenges by enabling spatially scalable and panoramic dynamic scene synthesis that preserves coherence across panoramic scenes of arbitrary size. Specifically, we introduce a Offset Shifting Denoiser, facilitating efficient, synchronous, and coherent denoising panoramic dynamic scenes via a diffusion model with fixed resolution through a seamless rotating Window, which ensures seamless boundary transitions and consistency across the entire panoramic space, accommodating varying resolutions and aspect ratios. Additionally, we employ a Global Motion Guidance mechanism to ensure both local detail fidelity and global motion continuity. Extensive experiments demonstrate our method achieves superior content and motion quality in panoramic scene-level video generation, offering a training-free, efficient, and scalable solution for immersive dynamic scene creation with constant VRAM consumption regardless of the output video resolution. Our project page is available at \url{https://dynamic-scaler.pages.dev/}.
Openstory++: A Large-scale Dataset and Benchmark for Instance-aware Open-domain Visual Storytelling
Aug 07, 2024



Recent image generation models excel at creating high-quality images from brief captions. However, they fail to maintain consistency of multiple instances across images when encountering lengthy contexts. This inconsistency is largely due to in existing training datasets the absence of granular instance feature labeling in existing training datasets. To tackle these issues, we introduce Openstory++, a large-scale dataset combining additional instance-level annotations with both images and text. Furthermore, we develop a training methodology that emphasizes entity-centric image-text generation, ensuring that the models learn to effectively interweave visual and textual information. Specifically, Openstory++ streamlines the process of keyframe extraction from open-domain videos, employing vision-language models to generate captions that are then polished by a large language model for narrative continuity. It surpasses previous datasets by offering a more expansive open-domain resource, which incorporates automated captioning, high-resolution imagery tailored for instance count, and extensive frame sequences for temporal consistency. Additionally, we present Cohere-Bench, a pioneering benchmark framework for evaluating the image generation tasks when long multimodal context is provided, including the ability to keep the background, style, instances in the given context coherent. Compared to existing benchmarks, our work fills critical gaps in multi-modal generation, propelling the development of models that can adeptly generate and interpret complex narratives in open-domain environments. Experiments conducted within Cohere-Bench confirm the superiority of Openstory++ in nurturing high-quality visual storytelling models, enhancing their ability to address open-domain generation tasks. More details can be found at https://openstorypp.github.io/
InstructRL4Pix: Training Diffusion for Image Editing by Reinforcement Learning
Jun 14, 2024Instruction-based image editing has made a great process in using natural human language to manipulate the visual content of images. However, existing models are limited by the quality of the dataset and cannot accurately localize editing regions in images with complex object relationships. In this paper, we propose Reinforcement Learning Guided Image Editing Method(InstructRL4Pix) to train a diffusion model to generate images that are guided by the attention maps of the target object. Our method maximizes the output of the reward model by calculating the distance between attention maps as a reward function and fine-tuning the diffusion model using proximal policy optimization (PPO). We evaluate our model in object insertion, removal, replacement, and transformation. Experimental results show that InstructRL4Pix breaks through the limitations of traditional datasets and uses unsupervised learning to optimize editing goals and achieve accurate image editing based on natural human commands.
PoseAnimate: Zero-shot high fidelity pose controllable character animation
Apr 30, 2024
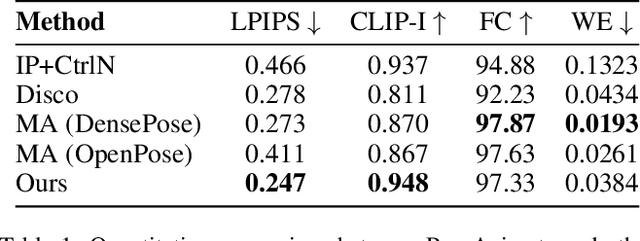
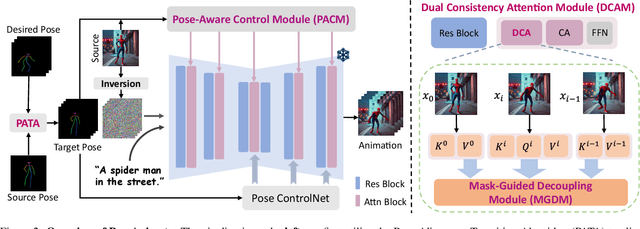
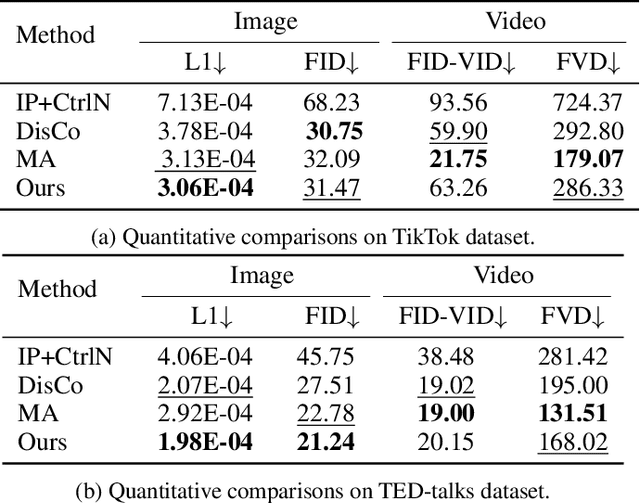
Image-to-video(I2V) generation aims to create a video sequence from a single image, which requires high temporal coherence and visual fidelity with the source image.However, existing approaches suffer from character appearance inconsistency and poor preservation of fine details. Moreover, they require a large amount of video data for training, which can be computationally demanding.To address these limitations,we propose PoseAnimate, a novel zero-shot I2V framework for character animation.PoseAnimate contains three key components: 1) Pose-Aware Control Module (PACM) incorporates diverse pose signals into conditional embeddings, to preserve character-independent content and maintain precise alignment of actions.2) Dual Consistency Attention Module (DCAM) enhances temporal consistency, and retains character identity and intricate background details.3) Mask-Guided Decoupling Module (MGDM) refines distinct feature perception, improving animation fidelity by decoupling the character and background.We also propose a Pose Alignment Transition Algorithm (PATA) to ensure smooth action transition.Extensive experiment results demonstrate that our approach outperforms the state-of-the-art training-based methods in terms of character consistency and detail fidelity. Moreover, it maintains a high level of temporal coherence throughout the generated animations.
FreeA: Human-object Interaction Detection using Free Annotation Labels
Mar 04, 2024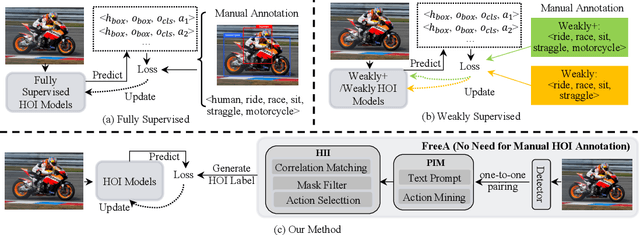
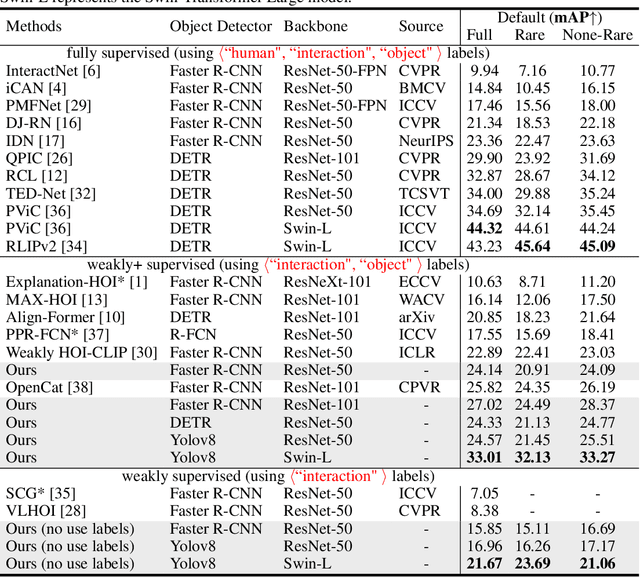
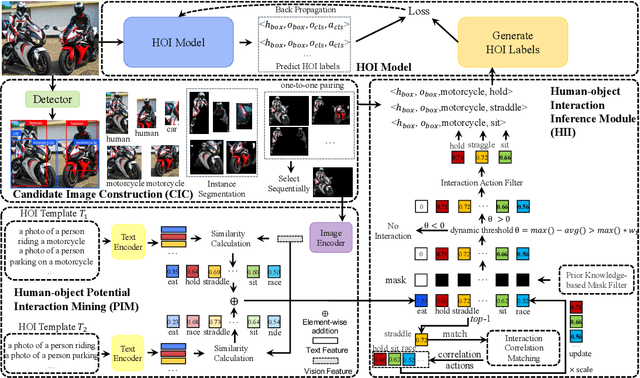
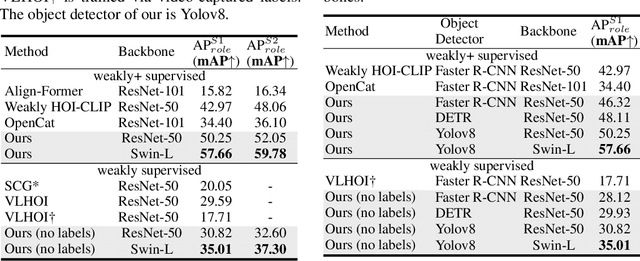
Recent human-object interaction (HOI) detection approaches rely on high cost of manpower and require comprehensive annotated image datasets. In this paper, we propose a novel self-adaption language-driven HOI detection method, termed as FreeA, without labeling by leveraging the adaptability of CLIP to generate latent HOI labels. To be specific, FreeA matches image features of human-object pairs with HOI text templates, and a priori knowledge-based mask method is developed to suppress improbable interactions. In addition, FreeA utilizes the proposed interaction correlation matching method to enhance the likelihood of actions related to a specified action, further refine the generated HOI labels. Experiments on two benchmark datasets show that FreeA achieves state-of-the-art performance among weakly supervised HOI models. Our approach is +8.58 mean Average Precision (mAP) on HICO-DET and +1.23 mAP on V-COCO more accurate in localizing and classifying the interactive actions than the newest weakly model, and +1.68 mAP and +7.28 mAP than the latest weakly+ model, respectively. Code will be available at https://drliuqi.github.io/.