 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt Guidance and Human Proximal Perception for HOT Prediction with Regional Joint Loss
Jul 02, 2025



The task of Human-Object conTact (HOT) detection involves identifying the specific areas of the human body that are touching objects. Nevertheless, current models are restricted to just one type of image, often leading to too much segmentation in areas with little interaction, and struggling to maintain category consistency within specific regions. To tackle this issue, a HOT framework, termed \textbf{P3HOT}, is proposed, which blends \textbf{P}rompt guidance and human \textbf{P}roximal \textbf{P}erception. To begin with, we utilize a semantic-driven prompt mechanism to direct the network's attention towards the relevant regions based on the correlation between image and text. Then a human proximal perception mechanism is employed to dynamically perceive key depth range around the human, using learnable parameters to effectively eliminate regions where interactions are not expected. Calculating depth resolves the uncertainty of the overlap between humans and objects in a 2D perspective, providing a quasi-3D viewpoint. Moreover, a Regional Joint Loss (RJLoss) has been created as a new loss to inhibit abnormal categories in the same area. A new evaluation metric called ``AD-Acc.'' is introduced to address the shortcomings of existing methods in addressing negative samples. Comprehensive experimental results demonstrate that our approach achieves state-of-the-art performance in four metrics across two benchmark datasets. Specifically, our model achieves an improvement of \textbf{0.7}$\uparrow$, \textbf{2.0}$\uparrow$, \textbf{1.6}$\uparrow$, and \textbf{11.0}$\uparrow$ in SC-Acc., mIoU, wIoU, and AD-Acc. metrics, respectively, on the HOT-Annotated dataset. Code is available at https://github.com/YuxiaoWang-AI/P3HOT.
OpenVidVRD: Open-Vocabulary Video Visual Relation Detection via Prompt-Driven Semantic Space Alignment
Mar 12, 2025



The video visual relation detection (VidVRD) task is to identify objects and their relationships in videos, which is challenging due to the dynamic content, high annotation costs, and long-tailed distribution of relations. Visual language models (VLMs) help explore open-vocabulary visual relation detection tasks, yet often overlook the connections between various visual regions and their relations. Moreover, using VLMs to directly identify visual relations in videos poses significant challenges because of the large disparity between images and videos. Therefore, we propose a novel open-vocabulary VidVRD framework, termed OpenVidVRD, which transfers VLMs' rich knowledge and powerful capabilities to improve VidVRD tasks through prompt learning. Specificall y, We use VLM to extract text representations from automatically generated region captions based on the video's regions. Next, we develop a spatiotemporal refiner module to derive object-level relationship representations in the video by integrating cross-modal spatiotemporal complementary information. Furthermore, a prompt-driven strategy to align semantic spaces is employed to harness the semantic understanding of VLMs, enhancing the overall generalization ability of OpenVidVRD. Extensive experiments conducted on the VidVRD and VidOR public datasets show that the proposed model outperforms existing methods.
Precision-Enhanced Human-Object Contact Detection via Depth-Aware Perspective Interaction and Object Texture Restoration
Dec 13, 2024



Human-object contact (HOT) is designed to accurately identify the areas where humans and objects come into contact. Current methods frequently fail to account for scenarios where objects are frequently blocking the view, resulting in inaccurate identification of contact areas. To tackle this problem, we suggest using a perspective interaction HOT detector called PIHOT, which utilizes a depth map generation model to offer depth information of humans and objects related to the camera, thereby preventing false interaction detection. Furthermore, we use mask dilatation and object restoration techniques to restore the texture details in covered areas, improve the boundaries between objects, and enhance the perception of humans interacting with objects. Moreover, a spatial awareness perception is intended to concentrate on the characteristic features close to the points of contact. The experimental results show that the PIHOT algorithm achieves state-of-the-art performance on three benchmark datasets for HOT detection tasks. Compared to the most recent DHOT, our method enjoys an average improvement of 13%, 27.5%, 16%, and 18.5% on SC-Acc., C-Acc., mIoU, and wIoU metrics, respectively.
A Review of Human-Object Interaction Detection
Aug 20, 2024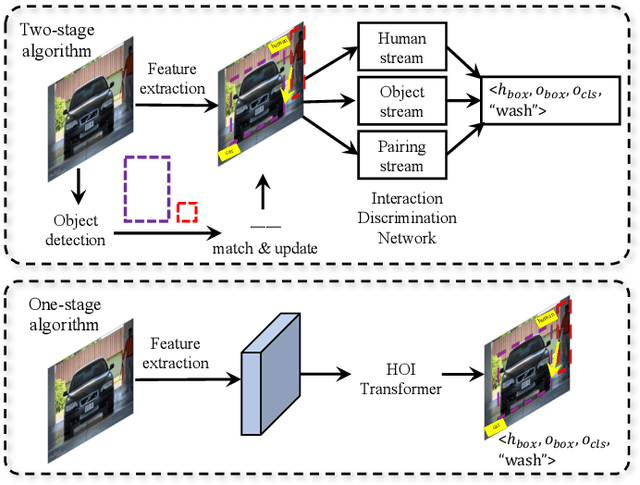
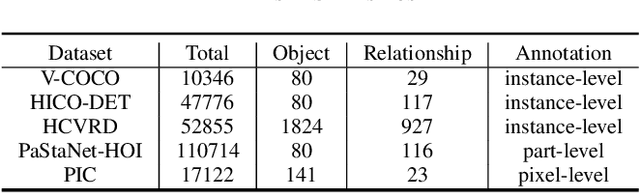
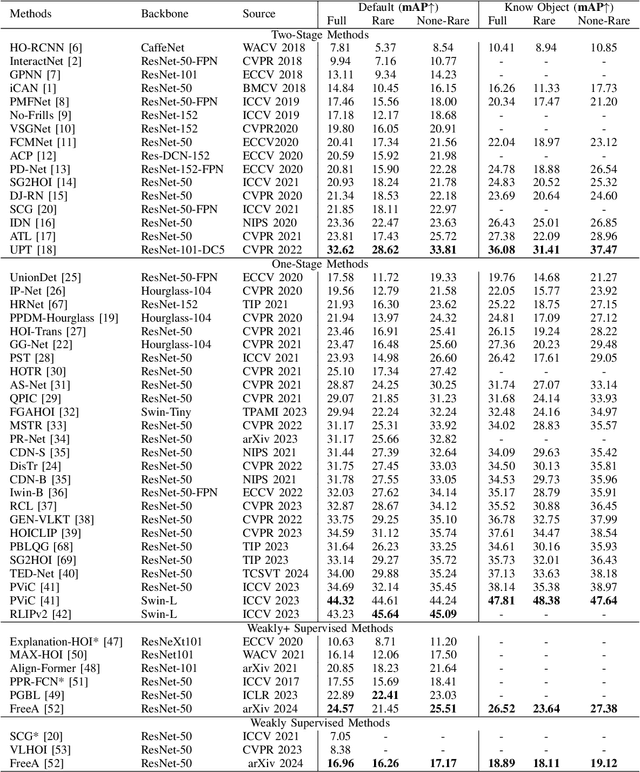
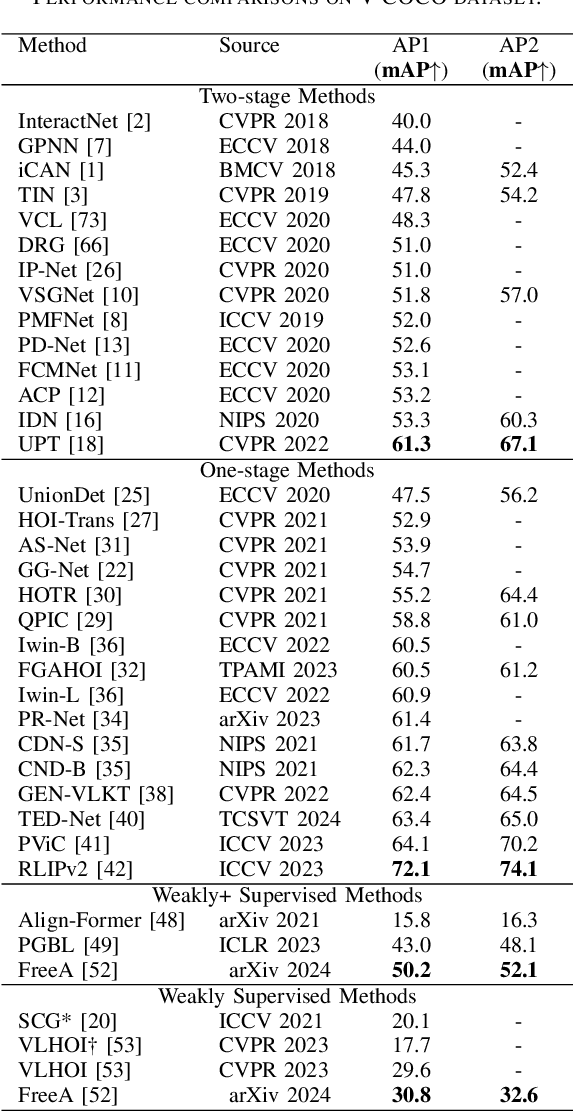
Human-object interaction (HOI) detection plays a key role in high-level visual understanding, facilitating a deep comprehension of human activities. Specifically, HOI detection aims to locate the humans and objects involved in interactions within images or videos and classify the specific interactions between them. The success of this task is influenced by several key factors, including the accurate localization of human and object instances, as well as the correct classification of object categories and interaction relationships. This paper systematically summarizes and discusses the recent work in image-based HOI detection. First, the mainstream datasets involved in HOI relationship detection are introduced. Furthermore, starting with two-stage methods and end-to-end one-stage detection approaches, this paper comprehensively discusses the current developments in image-based HOI detection, analyzing the strengths and weaknesses of these two methods. Additionally, the advancements of zero-shot learning, weakly supervised learning, and the application of large-scale language models in HOI detection are discussed. Finally, the current challenges in HOI detection are outlined, and potential research directions and future trends are explored.
Towards Zero-shot Human-Object Interaction Detection via Vision-Language Integration
Mar 12, 2024



Human-object interaction (HOI) detection aims to locate human-object pairs and identify their interaction categories in images. Most existing methods primarily focus on supervised learning, which relies on extensive manual HOI annotations. In this paper, we propose a novel framework, termed Knowledge Integration to HOI (KI2HOI), that effectively integrates the knowledge of visual-language model to improve zero-shot HOI detection. Specifically, the verb feature learning module is designed based on visual semantics, by employing the verb extraction decoder to convert corresponding verb queries into interaction-specific category representations. We develop an effective additive self-attention mechanism to generate more comprehensive visual representations. Moreover, the innovative interaction representation decoder effectively extracts informative regions by integrating spatial and visual feature information through a cross-attention mechanism. To deal with zero-shot learning in low-data, we leverage a priori knowledge from the CLIP text encoder to initialize the linear classifier for enhanced interaction understanding. Extensive experiments conducted on the mainstream HICO-DET and V-COCO datasets demonstrate that our model outperforms the previous methods in various zero-shot and full-supervised settings.
FreeA: Human-object Interaction Detection using Free Annotation Labels
Mar 04, 2024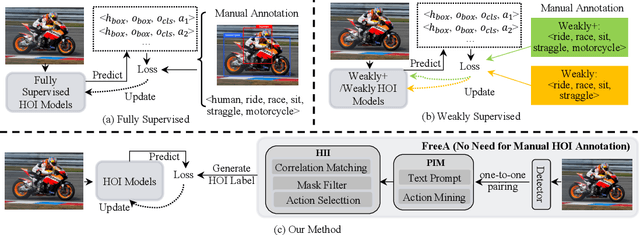
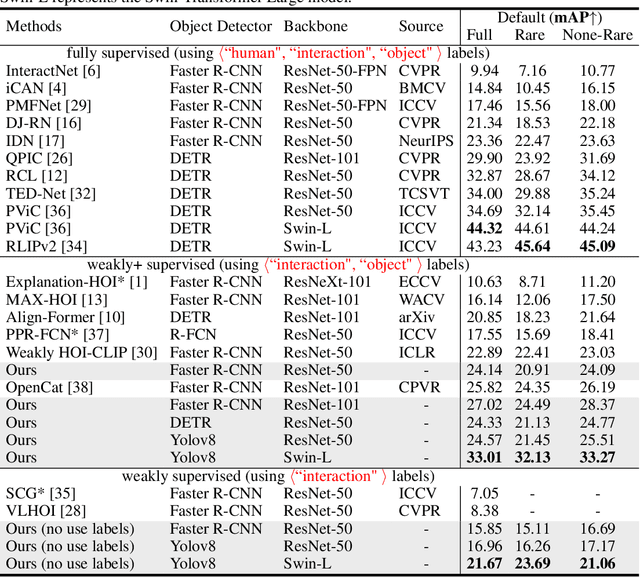
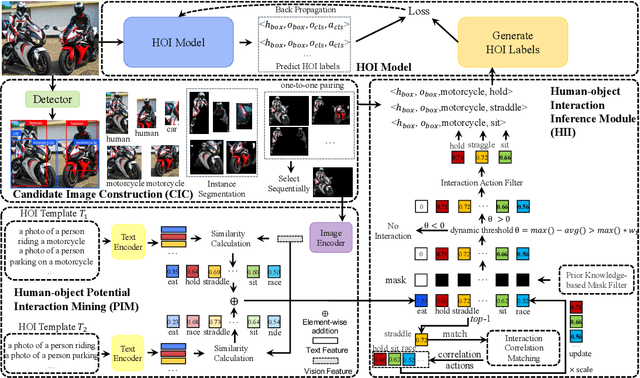
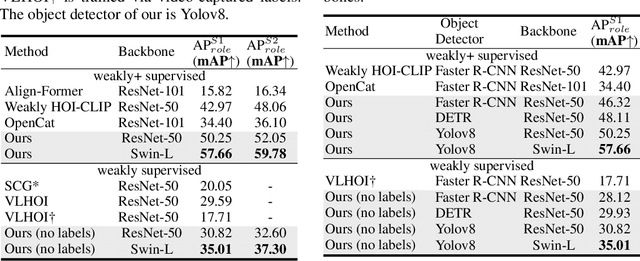
Recent human-object interaction (HOI) detection approaches rely on high cost of manpower and require comprehensive annotated image datasets. In this paper, we propose a novel self-adaption language-driven HOI detection method, termed as FreeA, without labeling by leveraging the adaptability of CLIP to generate latent HOI labels. To be specific, FreeA matches image features of human-object pairs with HOI text templates, and a priori knowledge-based mask method is developed to suppress improbable interactions. In addition, FreeA utilizes the proposed interaction correlation matching method to enhance the likelihood of actions related to a specified action, further refine the generated HOI labels. Experiments on two benchmark datasets show that FreeA achieves state-of-the-art performance among weakly supervised HOI models. Our approach is +8.58 mean Average Precision (mAP) on HICO-DET and +1.23 mAP on V-COCO more accurate in localizing and classifying the interactive actions than the newest weakly model, and +1.68 mAP and +7.28 mAP than the latest weakly+ model, respectively. Code will be available at https://drliuqi.github.io/.