 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysDrift: Bridging the Embodiment Gap in Humanoid Co-Speech Motion Generation
Jun 18, 2026Humanoid robots require co-speech motions that are not only expressive and speech-aligned, but also physically executable under embodiment constraints. Existing co-speech generation pipelines are predominantly human-centric: motions are first generated in human-body representations such as SMPL-X and subsequently retargeted to humanoid robots. In this work, we identify a fundamental embodiment gap in this paradigm, where the mismatch between human motion manifolds and humanoid embodiment constraints disrupts embodiment consistency during motion transfer and physical execution. Through extensive analysis, we show that although retargeting can preserve coarse motion semantics, it significantly compresses motion diversity and weakens prosody-motion synchronization, limiting expressive humanoid behaviors. To address this problem, we first propose IK-EER, a prosody-preserving humanoid motion curation framework that jointly optimizes kinematic feasibility and speech-motion temporal alignment during retargeting. Building upon the curated robot-native motion dataset, we further introduce PhysDrift, an embodiment-aware co-speech motion generation framework that directly predicts executable humanoid joint trajectories from speech without relying on intermediate human-body representations. Unlike conventional human-centric pipelines, PhysDrift maintains embodiment consistency throughout both training and inference while incorporating physical regularization to stabilize robot motion dynamics. Extensive experiments and real-world humanoid deployment demonstrate that embodiment-aware robot-native generation substantially improves speech-motion alignment, physical plausibility, motion smoothness, inference efficiency, and real-time interaction capability.
NVMOS: Non-Verbal Vocalization Quality Assessment in Speech
Jun 14, 2026Non-verbal vocalizations (NVs), such as laughter, sighs, and coughs, are important acoustic cues for emotion and intent. Existing speech quality assessment methods typically focus on overall naturalness, while non-verbal TTS evaluations mainly examine whether a target NV appears with the correct type and position. However, the perceptual quality of NV events themselves remains underexplored. To address this gap, we construct an NV-MOS dataset containing outputs from multiple NV-TTS systems and naturally occurring NV samples, with ratings collected from three acoustic experts on a perceptual quality scale. We further analyze audio-capable multimodal large language models such as Gemini and find clear inconsistencies between their scores and expert ratings. These results suggest that general-purpose multimodal models cannot reliably replace human judgments for NV quality assessment. We then propose NVMOS, to our knowledge the first model that can reliably predict the perceptual quality of NV events in speech. Experimental results show that, with a local NV-event focusing module, NVMOS reaches expert-level or stronger agreement with human MOS.
MERRY: Semantically Decoupled Evaluation of Multimodal Emotional and Role Consistencies of Role-Playing Agents
Feb 24, 2026Multimodal Role-Playing Agents (MRPAs) are attracting increasing attention due to their ability to deliver more immersive multimodal emotional interactions. However, existing studies still rely on pure textual benchmarks to evaluate the text responses of MRPAs, while delegating the assessment of their multimodal expressions solely to modality-synthesis metrics. This evaluation paradigm, on the one hand, entangles semantic assessment with modality generation, leading to ambiguous error attribution, and on the other hand remains constrained by the heavy reliance on human judgment. To this end, we propose MERRY, a semantically decoupled evaluation framework for assessing Multimodal Emotional and Role consistencies of Role-playing agents. This framework introduce five refined metrics for EC and three for RC. Notably, we transform the traditional subjective scoring approach into a novel bidirectional-evidence-finding task, significantly improving the human agreement of LLM-as-Judge evaluations. Based on MERRY, we conduct extensive evaluations. Our empirical results primarily reveal that: (1) Training on synthetic datasets tends to reduce emotional consistency, whereas training on real-world datasets improves it; (2) Existing models suffer from emotional templatization and simplification, exhibiting positive-bias and performance bottleneck in fine-grained negative emotions; (3) Simple prompting method strengthens the weak models but constrains the strong ones, while simple fine-tuning method suffers from poor role generalization. Codes and dataset are available.
Profit Mirage: Revisiting Information Leakage in LLM-based Financial Agents
Oct 09, 2025LLM-based financial agents have attracted widespread excitement for their ability to trade like human experts. However, most systems exhibit a "profit mirage": dazzling back-tested returns evaporate once the model's knowledge window ends, because of the inherent information leakage in LLMs. In this paper, we systematically quantify this leakage issue across four dimensions and release FinLake-Bench, a leakage-robust evaluation benchmark. Furthermore, to mitigate this issue, we introduce FactFin, a framework that applies counterfactual perturbations to compel LLM-based agents to learn causal drivers instead of memorized outcomes. FactFin integrates four core components: Strategy Code Generator, Retrieval-Augmented Generation, Monte Carlo Tree Search, and Counterfactual Simulator. Extensive experiments show that our method surpasses all baselines in out-of-sample generalization, delivering superior risk-adjusted performance.
QuantAgents: Towards Multi-agent Financial System via Simulated Trading
Oct 06, 2025In this paper, our objective is to develop a multi-agent financial system that incorporates simulated trading, a technique extensively utilized by financial professionals. While current LLM-based agent models demonstrate competitive performance, they still exhibit significant deviations from real-world fund companies. A critical distinction lies in the agents' reliance on ``post-reflection'', particularly in response to adverse outcomes, but lack a distinctly human capability: long-term prediction of future trends. Therefore, we introduce QuantAgents, a multi-agent system integrating simulated trading, to comprehensively evaluate various investment strategies and market scenarios without assuming actual risks. Specifically, QuantAgents comprises four agents: a simulated trading analyst, a risk control analyst, a market news analyst, and a manager, who collaborate through several meetings. Moreover, our system incentivizes agents to receive feedback on two fronts: performance in real-world markets and predictive accuracy in simulated trading. Extensive experiments demonstrate that our framework excels across all metrics, yielding an overall return of nearly 300% over the three years (https://quantagents.github.io/).
Patch-as-Decodable-Token: Towards Unified Multi-Modal Vision Tasks in MLLMs
Oct 02, 2025
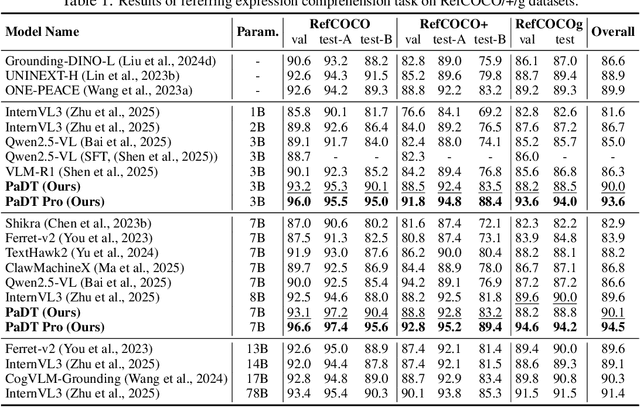

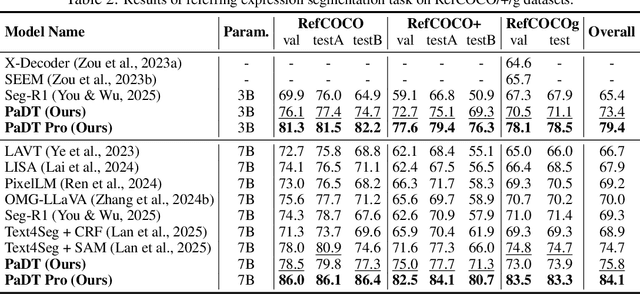
Multimodal large language models (MLLMs) have advanced rapidly in recent years. However, existing approaches for vision tasks often rely on indirect representations, such as generating coordinates as text for detection, which limits performance and prevents dense prediction tasks like segmentation. To overcome these challenges, we introduce Patch-as-Decodable Token (PaDT), a unified paradigm that enables MLLMs to directly generate both textual and diverse visual outputs. Central to PaDT are Visual Reference Tokens (VRTs), derived from visual patch embeddings of query images and interleaved seamlessly with LLM's output textual tokens. A lightweight decoder then transforms LLM's outputs into detection, segmentation, and grounding predictions. Unlike prior methods, PaDT processes VRTs independently at each forward pass and dynamically expands the embedding table, thus improving localization and differentiation among similar objects. We further tailor a training strategy for PaDT by randomly selecting VRTs for supervised fine-tuning and introducing a robust per-token cross-entropy loss. Our empirical studies across four visual perception and understanding tasks suggest PaDT consistently achieving state-of-the-art performance, even compared with significantly larger MLLM models. The code is available at https://github.com/Gorilla-Lab-SCUT/PaDT.
Long-Context Speech Synthesis with Context-Aware Memory
Aug 20, 2025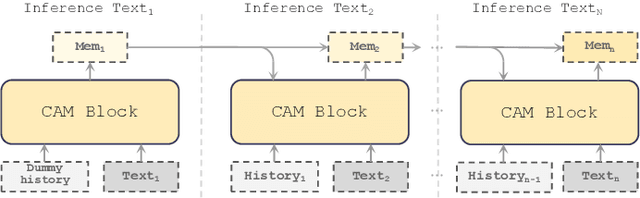
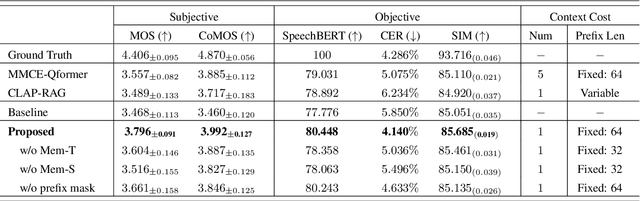
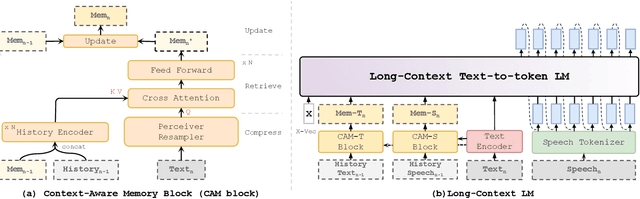
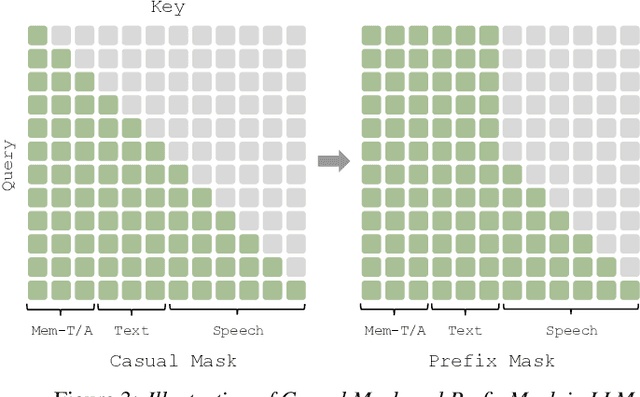
In long-text speech synthesis, current approaches typically convert text to speech at the sentence-level and concatenate the results to form pseudo-paragraph-level speech. These methods overlook the contextual coherence of paragraphs, leading to reduced naturalness and inconsistencies in style and timbre across the long-form speech. To address these issues, we propose a Context-Aware Memory (CAM)-based long-context Text-to-Speech (TTS) model. The CAM block integrates and retrieves both long-term memory and local context details, enabling dynamic memory updates and transfers within long paragraphs to guide sentence-level speech synthesis. Furthermore, the prefix mask enhances the in-context learning ability by enabling bidirectional attention on prefix tokens while maintaining unidirectional generation. Experimental results demonstrate that the proposed method outperforms baseline and state-of-the-art long-context methods in terms of prosody expressiveness, coherence and context inference cost across paragraph-level speech.
Parallel GPT: Harmonizing the Independence and Interdependence of Acoustic and Semantic Information for Zero-Shot Text-to-Speech
Aug 06, 2025Advances in speech representation and large language models have enhanced zero-shot text-to-speech (TTS) performance. However, existing zero-shot TTS models face challenges in capturing the complex correlations between acoustic and semantic features, resulting in a lack of expressiveness and similarity. The primary reason lies in the complex relationship between semantic and acoustic features, which manifests independent and interdependent aspects.This paper introduces a TTS framework that combines both autoregressive (AR) and non-autoregressive (NAR) modules to harmonize the independence and interdependence of acoustic and semantic information. The AR model leverages the proposed Parallel Tokenizer to synthesize the top semantic and acoustic tokens simultaneously. In contrast, considering the interdependence, the Coupled NAR model predicts detailed tokens based on the general AR model's output. Parallel GPT, built on this architecture, is designed to improve zero-shot text-to-speech synthesis through its parallel structure. Experiments on English and Chinese datasets demonstrate that the proposed model significantly outperforms the quality and efficiency of the synthesis of existing zero-shot TTS models. Speech demos are available at https://t1235-ch.github.io/pgpt/.
S2SBench: A Benchmark for Quantifying Intelligence Degradation in Speech-to-Speech Large Language Models
May 20, 2025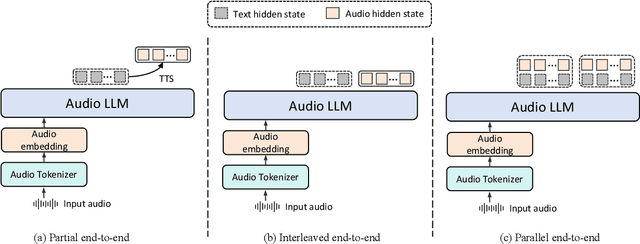
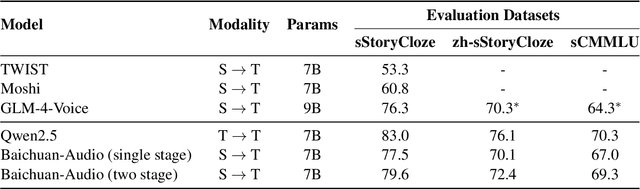
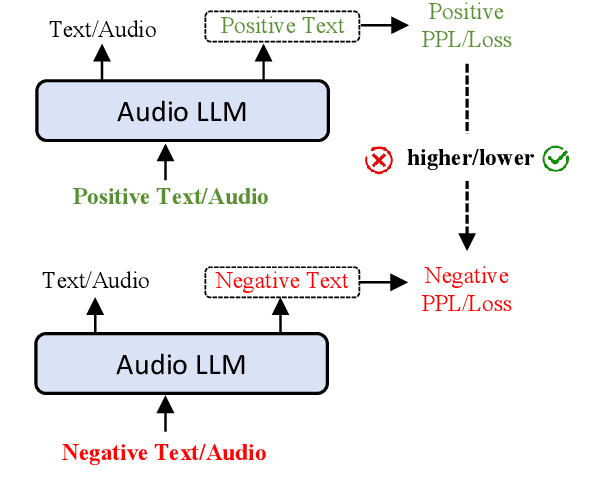
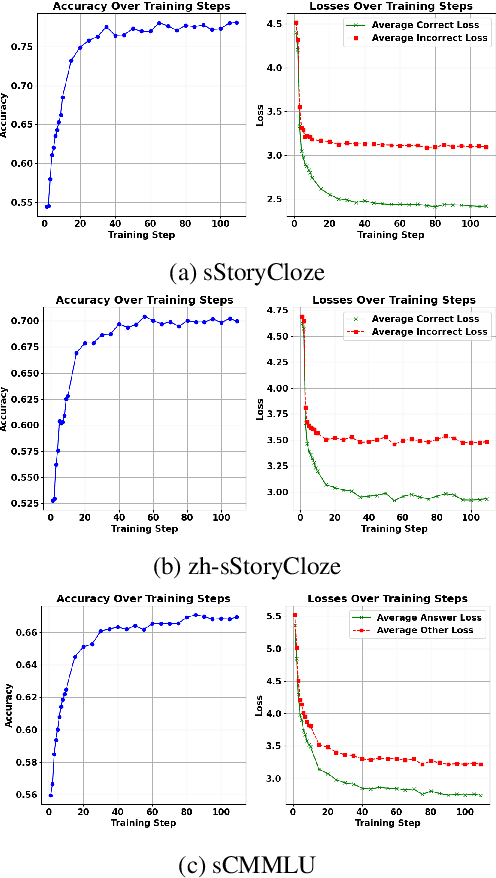
End-to-end speech large language models ((LLMs)) extend the capabilities of text-based models to directly process and generate audio tokens. However, this often leads to a decline in reasoning and generation performance compared to text input, a phenomenon referred to as intelligence degradation. To systematically evaluate this gap, we propose S2SBench, a benchmark designed to quantify performance degradation in Speech LLMs. It includes diagnostic datasets targeting sentence continuation and commonsense reasoning under audio input. We further introduce a pairwise evaluation protocol based on perplexity differences between plausible and implausible samples to measure degradation relative to text input. We apply S2SBench to analyze the training process of Baichuan-Audio, which further demonstrates the benchmark's effectiveness. All datasets and evaluation code are available at https://github.com/undobug/S2SBench.
Enhancing User-Oriented Proactivity in Open-Domain Dialogues with Critic Guidance
May 18, 2025
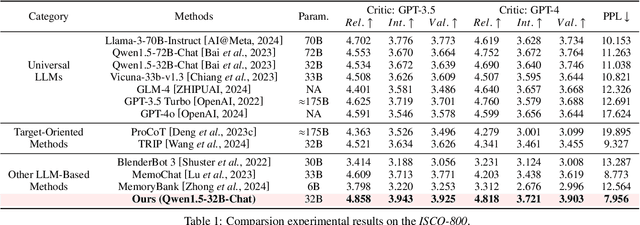
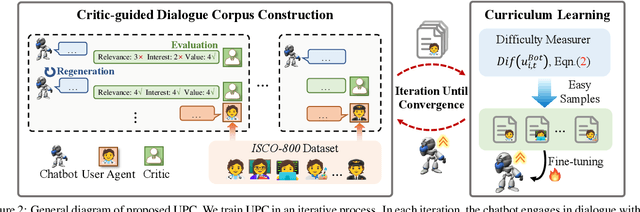

Open-domain dialogue systems aim to generate natural and engaging conversations, providing significant practical value in real applications such as social robotics and personal assistants. The advent of large language models (LLMs) has greatly advanced this field by improving context understanding and conversational fluency. However, existing LLM-based dialogue systems often fall short in proactively understanding the user's chatting preferences and guiding conversations toward user-centered topics. This lack of user-oriented proactivity can lead users to feel unappreciated, reducing their satisfaction and willingness to continue the conversation in human-computer interactions. To address this issue, we propose a User-oriented Proactive Chatbot (UPC) to enhance the user-oriented proactivity. Specifically, we first construct a critic to evaluate this proactivity inspired by the LLM-as-a-judge strategy. Given the scarcity of high-quality training data, we then employ the critic to guide dialogues between the chatbot and user agents, generating a corpus with enhanced user-oriented proactivity. To ensure the diversity of the user backgrounds, we introduce the ISCO-800, a diverse user background dataset for constructing user agents. Moreover, considering the communication difficulty varies among users, we propose an iterative curriculum learning method that trains the chatbot from easy-to-communicate users to more challenging ones, thereby gradually enhancing its performance. Experiments demonstrate that our proposed training method is applicable to different LLMs, improving user-oriented proactivity and attractiveness in open-domain dialogues.