 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupled Sensitivity-Consistency Learning for Weakly Supervised Video Anomaly Detection
Mar 20, 2026Recent weakly supervised video anomaly detection methods have achieved significant advances by employing unified frameworks for joint optimization. However, this paradigm is limited by a fundamental sensitivity-stability trade-off, as the conflicting objectives for detecting transient and sustained anomalies lead to either fragmented predictions or over-smoothed responses. To address this limitation, we propose DeSC, a novel Decoupled Sensitivity-Consistency framework that trains two specialized streams using distinct optimization strategies. The temporal sensitivity stream adopts an aggressive optimization strategy to capture high-frequency abrupt changes, whereas the semantic consistency stream applies robust constraints to maintain long-term coherence and reduce noise. Their complementary strengths are fused through a collaborative inference mechanism that reduces individual biases and produces balanced predictions. Extensive experiments demonstrate that DeSC establishes new state-of-the-art performance by achieving 89.37% AUC on UCF-Crime (+1.29%) and 87.18% AP on XD-Violence (+2.22%). Code is available at https://github.com/imzht/DeSC.
Profit Mirage: Revisiting Information Leakage in LLM-based Financial Agents
Oct 09, 2025LLM-based financial agents have attracted widespread excitement for their ability to trade like human experts. However, most systems exhibit a "profit mirage": dazzling back-tested returns evaporate once the model's knowledge window ends, because of the inherent information leakage in LLMs. In this paper, we systematically quantify this leakage issue across four dimensions and release FinLake-Bench, a leakage-robust evaluation benchmark. Furthermore, to mitigate this issue, we introduce FactFin, a framework that applies counterfactual perturbations to compel LLM-based agents to learn causal drivers instead of memorized outcomes. FactFin integrates four core components: Strategy Code Generator, Retrieval-Augmented Generation, Monte Carlo Tree Search, and Counterfactual Simulator. Extensive experiments show that our method surpasses all baselines in out-of-sample generalization, delivering superior risk-adjusted performance.
QuantAgents: Towards Multi-agent Financial System via Simulated Trading
Oct 06, 2025In this paper, our objective is to develop a multi-agent financial system that incorporates simulated trading, a technique extensively utilized by financial professionals. While current LLM-based agent models demonstrate competitive performance, they still exhibit significant deviations from real-world fund companies. A critical distinction lies in the agents' reliance on ``post-reflection'', particularly in response to adverse outcomes, but lack a distinctly human capability: long-term prediction of future trends. Therefore, we introduce QuantAgents, a multi-agent system integrating simulated trading, to comprehensively evaluate various investment strategies and market scenarios without assuming actual risks. Specifically, QuantAgents comprises four agents: a simulated trading analyst, a risk control analyst, a market news analyst, and a manager, who collaborate through several meetings. Moreover, our system incentivizes agents to receive feedback on two fronts: performance in real-world markets and predictive accuracy in simulated trading. Extensive experiments demonstrate that our framework excels across all metrics, yielding an overall return of nearly 300% over the three years (https://quantagents.github.io/).
COME: Dual Structure-Semantic Learning with Collaborative MoE for Universal Lesion Detection Across Heterogeneous Ultrasound Datasets
Aug 13, 2025Conventional single-dataset training often fails with new data distributions, especially in ultrasound (US) image analysis due to limited data, acoustic shadows, and speckle noise. Therefore, constructing a universal framework for multi-heterogeneous US datasets is imperative. However, a key challenge arises: how to effectively mitigate inter-dataset interference while preserving dataset-specific discriminative features for robust downstream task? Previous approaches utilize either a single source-specific decoder or a domain adaptation strategy, but these methods experienced a decline in performance when applied to other domains. Considering this, we propose a Universal Collaborative Mixture of Heterogeneous Source-Specific Experts (COME). Specifically, COME establishes dual structure-semantic shared experts that create a universal representation space and then collaborate with source-specific experts to extract discriminative features through providing complementary features. This design enables robust generalization by leveraging cross-datasets experience distributions and providing universal US priors for small-batch or unseen data scenarios. Extensive experiments under three evaluation modes (single-dataset, intra-organ, and inter-organ integration datasets) demonstrate COME's superiority, achieving significant mean AP improvements over state-of-the-art methods. Our project is available at: https://universalcome.github.io/UniversalCOME/.
MVISU-Bench: Benchmarking Mobile Agents for Real-World Tasks by Multi-App, Vague, Interactive, Single-App and Unethical Instructions
Aug 12, 2025Given the significant advances in Large Vision Language Models (LVLMs) in reasoning and visual understanding, mobile agents are rapidly emerging to meet users' automation needs. However, existing evaluation benchmarks are disconnected from the real world and fail to adequately address the diverse and complex requirements of users. From our extensive collection of user questionnaire, we identified five tasks: Multi-App, Vague, Interactive, Single-App, and Unethical Instructions. Around these tasks, we present \textbf{MVISU-Bench}, a bilingual benchmark that includes 404 tasks across 137 mobile applications. Furthermore, we propose Aider, a plug-and-play module that acts as a dynamic prompt prompter to mitigate risks and clarify user intent for mobile agents. Our Aider is easy to integrate into several frameworks and has successfully improved overall success rates by 19.55\% compared to the current state-of-the-art (SOTA) on MVISU-Bench. Specifically, it achieves success rate improvements of 53.52\% and 29.41\% for unethical and interactive instructions, respectively. Through extensive experiments and analysis, we highlight the gap between existing mobile agents and real-world user expectations.
DataMan: Data Manager for Pre-training Large Language Models
Feb 26, 2025The performance emergence of large language models (LLMs) driven by data scaling laws makes the selection of pre-training data increasingly important. However, existing methods rely on limited heuristics and human intuition, lacking comprehensive and clear guidelines. To address this, we are inspired by ``reverse thinking'' -- prompting LLMs to self-identify which criteria benefit its performance. As its pre-training capabilities are related to perplexity (PPL), we derive 14 quality criteria from the causes of text perplexity anomalies and introduce 15 common application domains to support domain mixing. In this paper, we train a Data Manager (DataMan) to learn quality ratings and domain recognition from pointwise rating, and use it to annotate a 447B token pre-training corpus with 14 quality ratings and domain type. Our experiments validate our approach, using DataMan to select 30B tokens to train a 1.3B-parameter language model, demonstrating significant improvements in in-context learning (ICL), perplexity, and instruction-following ability over the state-of-the-art baseline. The best-performing model, based on the Overall Score l=5 surpasses a model trained with 50% more data using uniform sampling. We continue pre-training with high-rated, domain-specific data annotated by DataMan to enhance domain-specific ICL performance and thus verify DataMan's domain mixing ability. Our findings emphasize the importance of quality ranking, the complementary nature of quality criteria, and their low correlation with perplexity, analyzing misalignment between PPL and ICL performance. We also thoroughly analyzed our pre-training dataset, examining its composition, the distribution of quality ratings, and the original document sources.
HedgeAgents: A Balanced-aware Multi-agent Financial Trading System
Feb 17, 2025
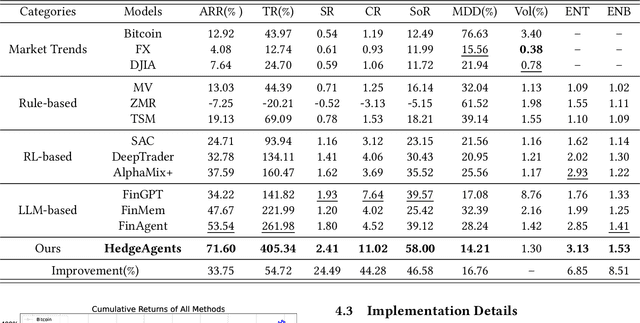
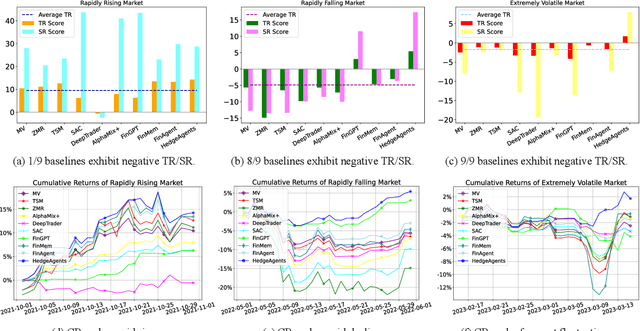

As automated trading gains traction in the financial market, algorithmic investment strategies are increasingly prominent. While Large Language Models (LLMs) and Agent-based models exhibit promising potential in real-time market analysis and trading decisions, they still experience a significant -20% loss when confronted with rapid declines or frequent fluctuations, impeding their practical application. Hence, there is an imperative to explore a more robust and resilient framework. This paper introduces an innovative multi-agent system, HedgeAgents, aimed at bolstering system robustness via ``hedging'' strategies. In this well-balanced system, an array of hedging agents has been tailored, where HedgeAgents consist of a central fund manager and multiple hedging experts specializing in various financial asset classes. These agents leverage LLMs' cognitive capabilities to make decisions and coordinate through three types of conferences. Benefiting from the powerful understanding of LLMs, our HedgeAgents attained a 70% annualized return and a 400% total return over a period of 3 years. Moreover, we have observed with delight that HedgeAgents can even formulate investment experience comparable to those of human experts (https://hedgeagents.github.io/).
RTBAgent: A LLM-based Agent System for Real-Time Bidding
Feb 02, 2025



Real-Time Bidding (RTB) enables advertisers to place competitive bids on impression opportunities instantaneously, striving for cost-effectiveness in a highly competitive landscape. Although RTB has widely benefited from the utilization of technologies such as deep learning and reinforcement learning, the reliability of related methods often encounters challenges due to the discrepancies between online and offline environments and the rapid fluctuations of online bidding. To handle these challenges, RTBAgent is proposed as the first RTB agent system based on large language models (LLMs), which synchronizes real competitive advertising bidding environments and obtains bidding prices through an integrated decision-making process. Specifically, obtaining reasoning ability through LLMs, RTBAgent is further tailored to be more professional for RTB via involved auxiliary modules, i.e., click-through rate estimation model, expert strategy knowledge, and daily reflection. In addition, we propose a two-step decision-making process and multi-memory retrieval mechanism, which enables RTBAgent to review historical decisions and transaction records and subsequently make decisions more adaptive to market changes in real-time bidding. Empirical testing with real advertising datasets demonstrates that RTBAgent significantly enhances profitability. The RTBAgent code will be publicly accessible at: https://github.com/CaiLeng/RTBAgent.
VideoCoT: A Video Chain-of-Thought Dataset with Active Annotation Tool
Jul 07, 2024



Multimodal large language models (MLLMs) are flourishing, but mainly focus on images with less attention than videos, especially in sub-fields such as prompt engineering, video chain-of-thought (CoT), and instruction tuning on videos. Therefore, we try to explore the collection of CoT datasets in videos to lead to video OpenQA and improve the reasoning ability of MLLMs. Unfortunately, making such video CoT datasets is not an easy task. Given that human annotation is too cumbersome and expensive, while machine-generated is not reliable due to the hallucination issue, we develop an automatic annotation tool that combines machine and human experts, under the active learning paradigm. Active learning is an interactive strategy between the model and human experts, in this way, the workload of human labeling can be reduced and the quality of the dataset can be guaranteed. With the help of the automatic annotation tool, we strive to contribute three datasets, namely VideoCoT, TopicQA, TopicCoT. Furthermore, we propose a simple but effective benchmark based on the collected datasets, which exploits CoT to maximize the complex reasoning capabilities of MLLMs. Extensive experiments demonstrate the effectiveness our solution.
FinReport: Explainable Stock Earnings Forecasting via News Factor Analyzing Model
Mar 05, 2024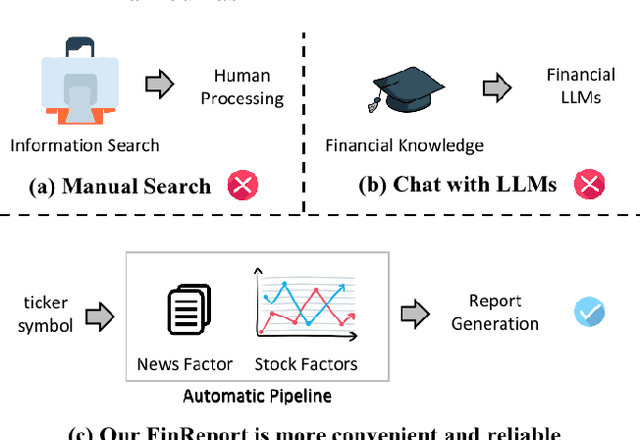

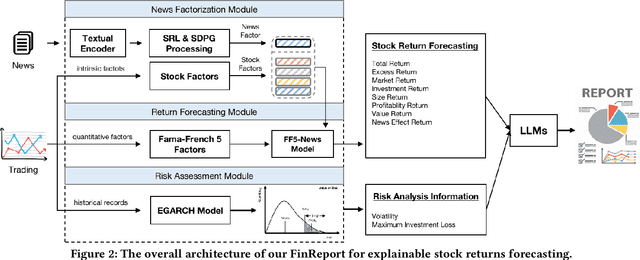

The task of stock earnings forecasting has received considerable attention due to the demand investors in real-world scenarios. However, compared with financial institutions, it is not easy for ordinary investors to mine factors and analyze news. On the other hand, although large language models in the financial field can serve users in the form of dialogue robots, it still requires users to have financial knowledge to ask reasonable questions. To serve the user experience, we aim to build an automatic system, FinReport, for ordinary investors to collect information, analyze it, and generate reports after summarizing. Specifically, our FinReport is based on financial news announcements and a multi-factor model to ensure the professionalism of the report. The FinReport consists of three modules: news factorization module, return forecasting module, risk assessment module. The news factorization module involves understanding news information and combining it with stock factors, the return forecasting module aim to analysis the impact of news on market sentiment, and the risk assessment module is adopted to control investment risk. Extensive experiments on real-world datasets have well verified the effectiveness and explainability of our proposed FinReport. Our codes and datasets are available at https://github.com/frinkleko/FinReport.