 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring $\ell_0$ Sparsification for Inference-free Sparse Retrievers
Apr 21, 2025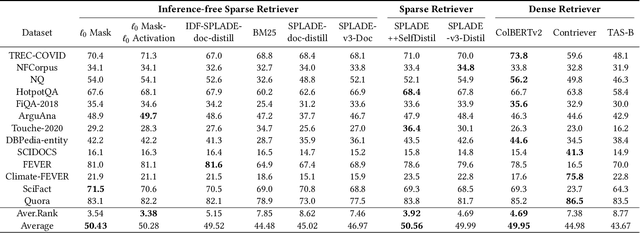
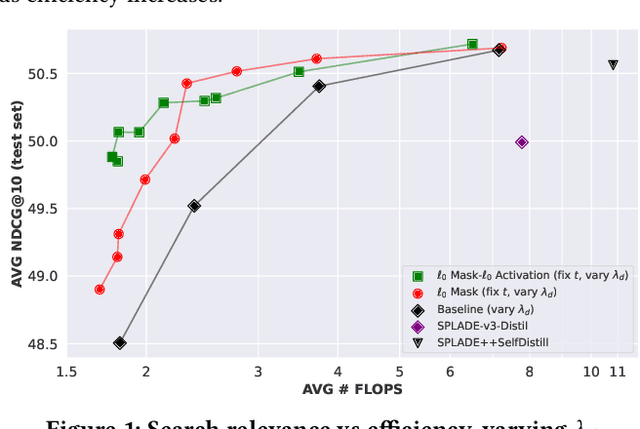
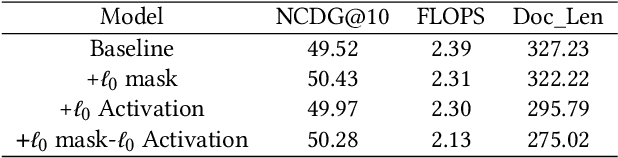
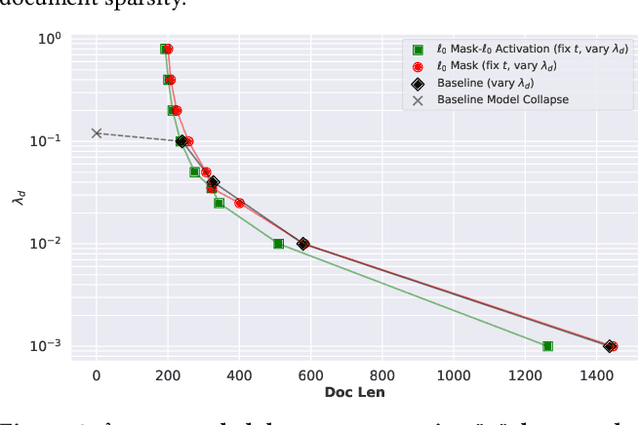
With increasing demands for efficiency, information retrieval has developed a branch of sparse retrieval, further advancing towards inference-free retrieval where the documents are encoded during indexing time and there is no model-inference for queries. Existing sparse retrieval models rely on FLOPS regularization for sparsification, while this mechanism was originally designed for Siamese encoders, it is considered to be suboptimal in inference-free scenarios which is asymmetric. Previous attempts to adapt FLOPS for inference-free scenarios have been limited to rule-based methods, leaving the potential of sparsification approaches for inference-free retrieval models largely unexplored. In this paper, we explore $\ell_0$ inspired sparsification manner for inference-free retrievers. Through comprehensive out-of-domain evaluation on the BEIR benchmark, our method achieves state-of-the-art performance among inference-free sparse retrieval models and is comparable to leading Siamese sparse retrieval models. Furthermore, we provide insights into the trade-off between retrieval effectiveness and computational efficiency, demonstrating practical value for real-world applications.
Collaborative Evolving Strategy for Automatic Data-Centric Development
Jul 26, 2024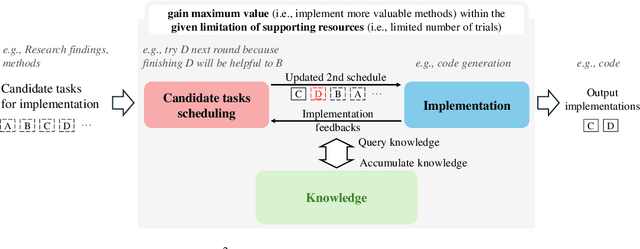

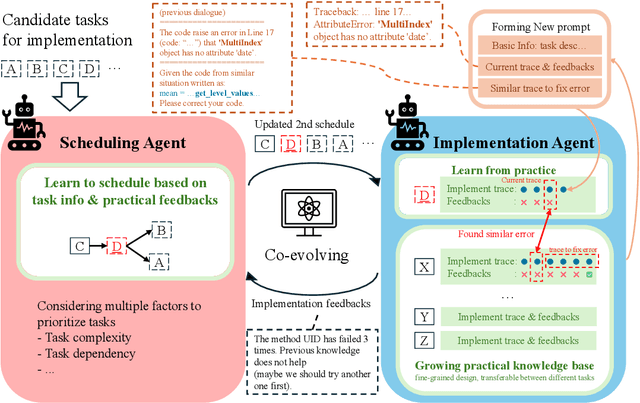
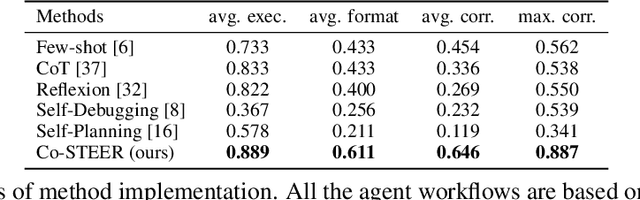
Artificial Intelligence (AI) significantly influences many fields, largely thanks to the vast amounts of high-quality data for machine learning models. The emphasis is now on a data-centric AI strategy, prioritizing data development over model design progress. Automating this process is crucial. In this paper, we serve as the first work to introduce the automatic data-centric development (AD^2) task and outline its core challenges, which require domain-experts-like task scheduling and implementation capability, largely unexplored by previous work. By leveraging the strong complex problem-solving capabilities of large language models (LLMs), we propose an LLM-based autonomous agent, equipped with a strategy named Collaborative Knowledge-STudying-Enhanced Evolution by Retrieval (Co-STEER), to simultaneously address all the challenges. Specifically, our proposed Co-STEER agent enriches its domain knowledge through our proposed evolving strategy and develops both its scheduling and implementation skills by accumulating and retrieving domain-specific practical experience. With an improved schedule, the capability for implementation accelerates. Simultaneously, as implementation feedback becomes more thorough, the scheduling accuracy increases. These two capabilities evolve together through practical feedback, enabling a collaborative evolution process. Extensive experimental results demonstrate that our Co-STEER agent breaks new ground in AD^2 research, possesses strong evolvable schedule and implementation ability, and demonstrates the significant effectiveness of its components. Our Co-STEER paves the way for AD^2 advancements.
RD2Bench: Toward Data-Centric Automatic R&D
Apr 17, 2024



The progress of humanity is driven by those successful discoveries accompanied by countless failed experiments. Researchers often seek the potential research directions by reading and then verifying them through experiments. The process imposes a significant burden on researchers. In the past decade, the data-driven black-box deep learning method demonstrates its effectiveness in a wide range of real-world scenarios, which exacerbates the experimental burden of researchers and thus renders the potential successful discoveries veiled. Therefore, automating such a research and development (R&D) process is an urgent need. In this paper, we serve as the first effort to formalize the goal by proposing a Real-world Data-centric automatic R&D Benchmark, namely RD2Bench. RD2Bench benchmarks all the operations in data-centric automatic R&D (D-CARD) as a whole to navigate future work toward our goal directly. We focuses on evaluating the interaction and synergistic effects of various model capabilities and aiding to select the well-performed trustworthy models. Although RD2Bench is very challenging to the state-of-the-art (SOTA) large language model (LLM) named GPT-4, indicating ample research opportunities and more research efforts, LLMs possess promising potential to bring more significant development to D-CARD: They are able to implement some simple methods without adopting any additional techniques. We appeal to future work to take developing techniques for tackling automatic R&D into consideration, thus bringing the opportunities of the potential revolutionary upgrade to human productivity.
Towards Efficient Information Fusion: Concentric Dual Fusion Attention Based Multiple Instance Learning for Whole Slide Images
Mar 21, 2024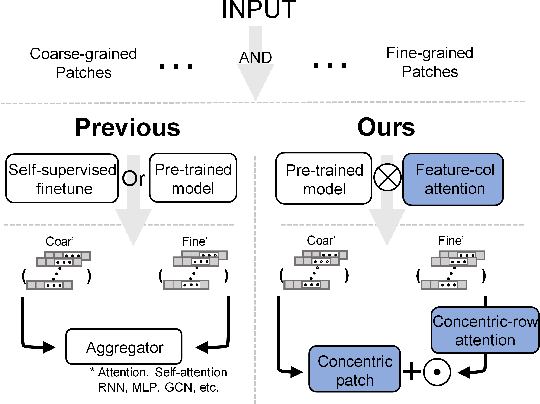
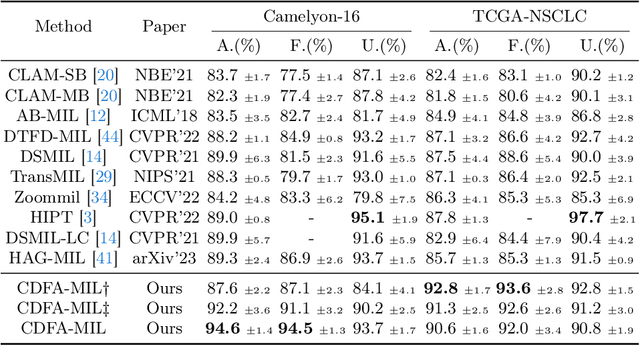
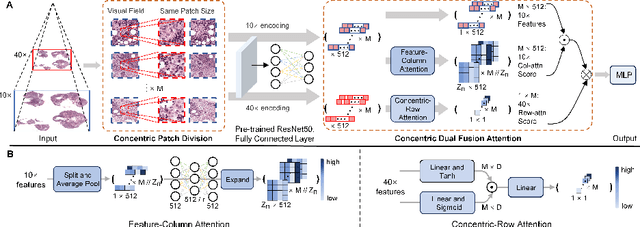

In the realm of digital pathology, multi-magnification Multiple Instance Learning (multi-mag MIL) has proven effective in leveraging the hierarchical structure of Whole Slide Images (WSIs) to reduce information loss and redundant data. However, current methods fall short in bridging the domain gap between pretrained models and medical imaging, and often fail to account for spatial relationships across different magnifications. Addressing these challenges, we introduce the Concentric Dual Fusion Attention-MIL (CDFA-MIL) framework,which innovatively combines point-to-area feature-colum attention and point-to-point concentric-row attention using concentric patch. This approach is designed to effectively fuse correlated information, enhancing feature representation and providing stronger correlation guidance for WSI analysis. CDFA-MIL distinguishes itself by offering a robust fusion strategy that leads to superior WSI recognition. Its application has demonstrated exceptional performance, significantly surpassing existing MIL methods in accuracy and F1 scores on prominent datasets like Camelyon16 and TCGA-NSCLC. Specifically, CDFA-MIL achieved an average accuracy and F1-score of 93.7\% and 94.1\% respectively on these datasets, marking a notable advancement over traditional MIL approaches.
Simple Multigraph Convolution Networks
Mar 08, 2024
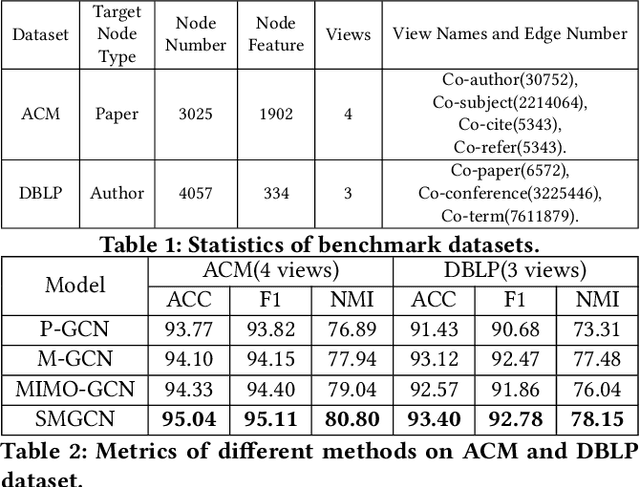


Existing multigraph convolution methods either ignore the cross-view interaction among multiple graphs, or induce extremely high computational cost due to standard cross-view polynomial operators. To alleviate this problem, this paper proposes a Simple MultiGraph Convolution Networks (SMGCN) which first extracts consistent cross-view topology from multigraphs including edge-level and subgraph-level topology, then performs polynomial expansion based on raw multigraphs and consistent topologies. In theory, SMGCN utilizes the consistent topologies in polynomial expansion rather than standard cross-view polynomial expansion, which performs credible cross-view spatial message-passing, follows the spectral convolution paradigm, and effectively reduces the complexity of standard polynomial expansion. In the simulations, experimental results demonstrate that SMGCN achieves state-of-the-art performance on ACM and DBLP multigraph benchmark datasets. Our codes are available at https://github.com/frinkleko/SMGCN.
FinReport: Explainable Stock Earnings Forecasting via News Factor Analyzing Model
Mar 05, 2024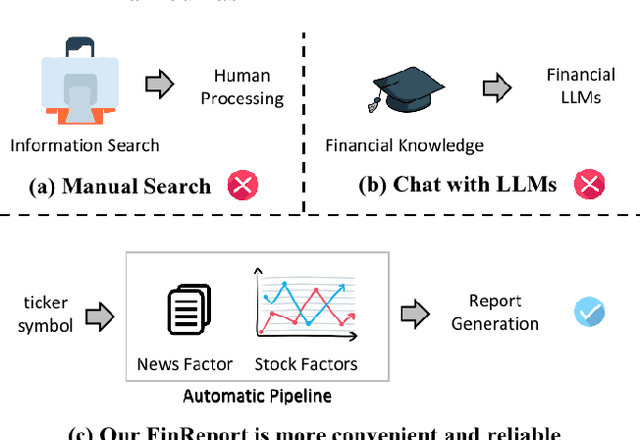

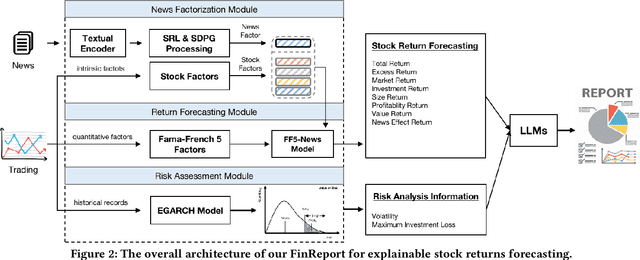

The task of stock earnings forecasting has received considerable attention due to the demand investors in real-world scenarios. However, compared with financial institutions, it is not easy for ordinary investors to mine factors and analyze news. On the other hand, although large language models in the financial field can serve users in the form of dialogue robots, it still requires users to have financial knowledge to ask reasonable questions. To serve the user experience, we aim to build an automatic system, FinReport, for ordinary investors to collect information, analyze it, and generate reports after summarizing. Specifically, our FinReport is based on financial news announcements and a multi-factor model to ensure the professionalism of the report. The FinReport consists of three modules: news factorization module, return forecasting module, risk assessment module. The news factorization module involves understanding news information and combining it with stock factors, the return forecasting module aim to analysis the impact of news on market sentiment, and the risk assessment module is adopted to control investment risk. Extensive experiments on real-world datasets have well verified the effectiveness and explainability of our proposed FinReport. Our codes and datasets are available at https://github.com/frinkleko/FinReport.
NP$^2$L: Negative Pseudo Partial Labels Extraction for Graph Neural Networks
Oct 02, 2023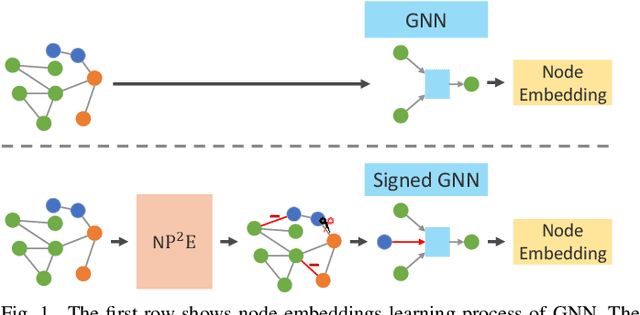
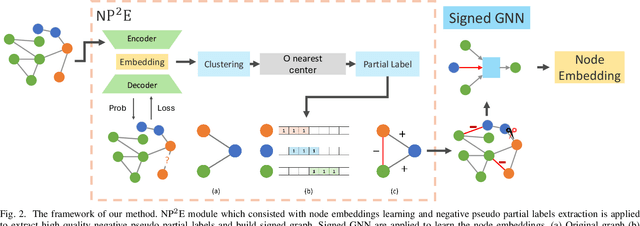
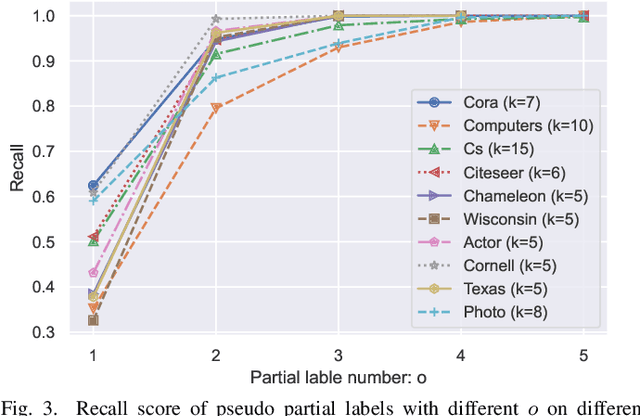
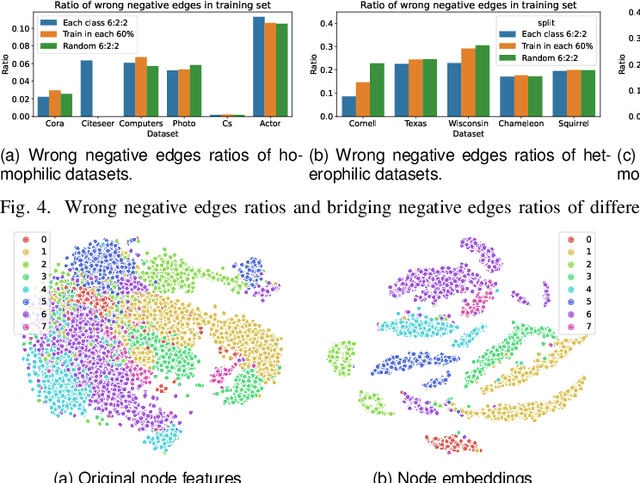
How to utilize the pseudo labels has always been a research hotspot in machine learning. However, most methods use pseudo labels as supervised training, and lack of valid assessing for their accuracy. Moreover, applications of pseudo labels in graph neural networks (GNNs) oversee the difference between graph learning and other machine learning tasks such as message passing mechanism. Aiming to address the first issue, we found through a large number of experiments that the pseudo labels are more accurate if they are selected by not overlapping partial labels and defined as negative node pairs relations. Therefore, considering the extraction based on pseudo and partial labels, negative edges are constructed between two nodes by the negative pseudo partial labels extraction (NP$^2$E) module. With that, a signed graph are built containing highly accurate pseudo labels information from the original graph, which effectively assists GNN in learning at the message-passing level, provide one solution to the second issue. Empirical results about link prediction and node classification tasks on several benchmark datasets demonstrate the effectiveness of our method. State-of-the-art performance is achieved on the both tasks.