 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Free Adaptation of Diffusion Models via Doob's $h$-Transform
Feb 18, 2026Adaptation methods have been a workhorse for unlocking the transformative power of pre-trained diffusion models in diverse applications. Existing approaches often abstract adaptation objectives as a reward function and steer diffusion models to generate high-reward samples. However, these approaches can incur high computational overhead due to additional training, or rely on stringent assumptions on the reward such as differentiability. Moreover, despite their empirical success, theoretical justification and guarantees are seldom established. In this paper, we propose DOIT (Doob-Oriented Inference-time Transformation), a training-free and computationally efficient adaptation method that applies to generic, non-differentiable rewards. The key framework underlying our method is a measure transport formulation that seeks to transport the pre-trained generative distribution to a high-reward target distribution. We leverage Doob's $h$-transform to realize this transport, which induces a dynamic correction to the diffusion sampling process and enables efficient simulation-based computation without modifying the pre-trained model. Theoretically, we establish a high probability convergence guarantee to the target high-reward distribution via characterizing the approximation error in the dynamic Doob's correction. Empirically, on D4RL offline RL benchmarks, our method consistently outperforms state-of-the-art baselines while preserving sampling efficiency.
Diffusion Transformers for Imputation: Statistical Efficiency and Uncertainty Quantification
Oct 02, 2025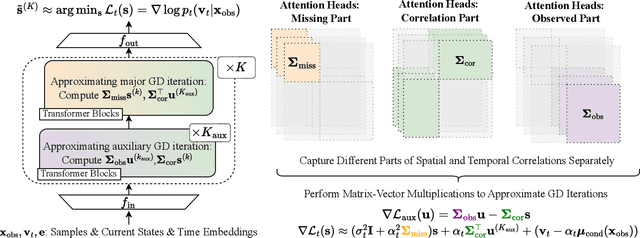

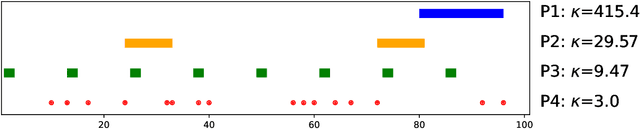
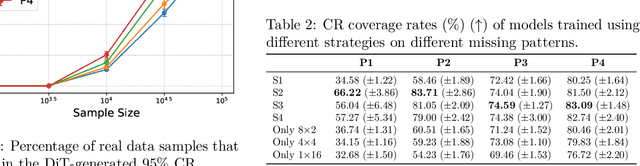
Imputation methods play a critical role in enhancing the quality of practical time-series data, which often suffer from pervasive missing values. Recently, diffusion-based generative imputation methods have demonstrated remarkable success compared to autoregressive and conventional statistical approaches. Despite their empirical success, the theoretical understanding of how well diffusion-based models capture complex spatial and temporal dependencies between the missing values and observed ones remains limited. Our work addresses this gap by investigating the statistical efficiency of conditional diffusion transformers for imputation and quantifying the uncertainty in missing values. Specifically, we derive statistical sample complexity bounds based on a novel approximation theory for conditional score functions using transformers, and, through this, construct tight confidence regions for missing values. Our findings also reveal that the efficiency and accuracy of imputation are significantly influenced by the missing patterns. Furthermore, we validate these theoretical insights through simulation and propose a mixed-masking training strategy to enhance the imputation performance.
BPQP: A Differentiable Convex Optimization Framework for Efficient End-to-End Learning
Nov 28, 2024Data-driven decision-making processes increasingly utilize end-to-end learnable deep neural networks to render final decisions. Sometimes, the output of the forward functions in certain layers is determined by the solutions to mathematical optimization problems, leading to the emergence of differentiable optimization layers that permit gradient back-propagation. However, real-world scenarios often involve large-scale datasets and numerous constraints, presenting significant challenges. Current methods for differentiating optimization problems typically rely on implicit differentiation, which necessitates costly computations on the Jacobian matrices, resulting in low efficiency. In this paper, we introduce BPQP, a differentiable convex optimization framework designed for efficient end-to-end learning. To enhance efficiency, we reformulate the backward pass as a simplified and decoupled quadratic programming problem by leveraging the structural properties of the KKT matrix. This reformulation enables the use of first-order optimization algorithms in calculating the backward pass gradients, allowing our framework to potentially utilize any state-of-the-art solver. As solver technologies evolve, BPQP can continuously adapt and improve its efficiency. Extensive experiments on both simulated and real-world datasets demonstrate that BPQP achieves a significant improvement in efficiency--typically an order of magnitude faster in overall execution time compared to other differentiable optimization layers. Our results not only highlight the efficiency gains of BPQP but also underscore its superiority over differentiable optimization layer baselines.
Collaborative Evolving Strategy for Automatic Data-Centric Development
Jul 26, 2024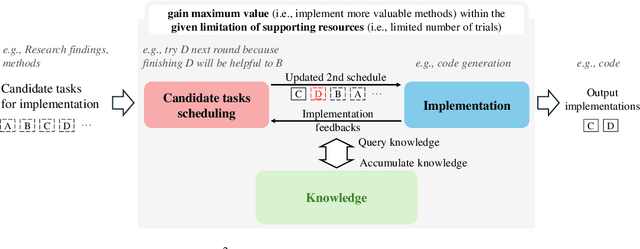

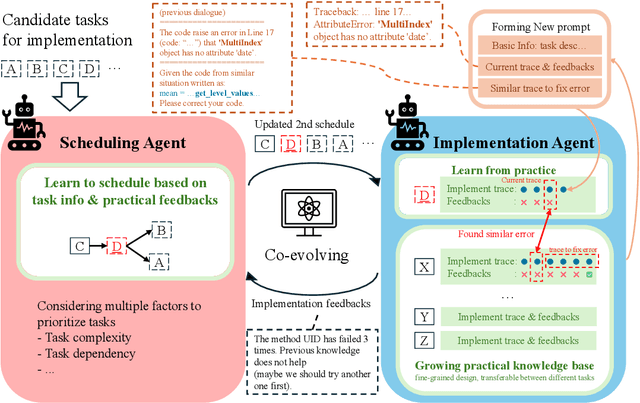
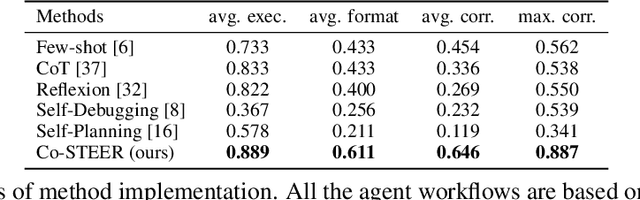
Artificial Intelligence (AI) significantly influences many fields, largely thanks to the vast amounts of high-quality data for machine learning models. The emphasis is now on a data-centric AI strategy, prioritizing data development over model design progress. Automating this process is crucial. In this paper, we serve as the first work to introduce the automatic data-centric development (AD^2) task and outline its core challenges, which require domain-experts-like task scheduling and implementation capability, largely unexplored by previous work. By leveraging the strong complex problem-solving capabilities of large language models (LLMs), we propose an LLM-based autonomous agent, equipped with a strategy named Collaborative Knowledge-STudying-Enhanced Evolution by Retrieval (Co-STEER), to simultaneously address all the challenges. Specifically, our proposed Co-STEER agent enriches its domain knowledge through our proposed evolving strategy and develops both its scheduling and implementation skills by accumulating and retrieving domain-specific practical experience. With an improved schedule, the capability for implementation accelerates. Simultaneously, as implementation feedback becomes more thorough, the scheduling accuracy increases. These two capabilities evolve together through practical feedback, enabling a collaborative evolution process. Extensive experimental results demonstrate that our Co-STEER agent breaks new ground in AD^2 research, possesses strong evolvable schedule and implementation ability, and demonstrates the significant effectiveness of its components. Our Co-STEER paves the way for AD^2 advancements.
RD2Bench: Toward Data-Centric Automatic R&D
Apr 17, 2024



The progress of humanity is driven by those successful discoveries accompanied by countless failed experiments. Researchers often seek the potential research directions by reading and then verifying them through experiments. The process imposes a significant burden on researchers. In the past decade, the data-driven black-box deep learning method demonstrates its effectiveness in a wide range of real-world scenarios, which exacerbates the experimental burden of researchers and thus renders the potential successful discoveries veiled. Therefore, automating such a research and development (R&D) process is an urgent need. In this paper, we serve as the first effort to formalize the goal by proposing a Real-world Data-centric automatic R&D Benchmark, namely RD2Bench. RD2Bench benchmarks all the operations in data-centric automatic R&D (D-CARD) as a whole to navigate future work toward our goal directly. We focuses on evaluating the interaction and synergistic effects of various model capabilities and aiding to select the well-performed trustworthy models. Although RD2Bench is very challenging to the state-of-the-art (SOTA) large language model (LLM) named GPT-4, indicating ample research opportunities and more research efforts, LLMs possess promising potential to bring more significant development to D-CARD: They are able to implement some simple methods without adopting any additional techniques. We appeal to future work to take developing techniques for tackling automatic R&D into consideration, thus bringing the opportunities of the potential revolutionary upgrade to human productivity.
Leveraging Large Language Model for Automatic Evolving of Industrial Data-Centric R&D Cycle
Oct 17, 2023



In the wake of relentless digital transformation, data-driven solutions are emerging as powerful tools to address multifarious industrial tasks such as forecasting, anomaly detection, planning, and even complex decision-making. Although data-centric R&D has been pivotal in harnessing these solutions, it often comes with significant costs in terms of human, computational, and time resources. This paper delves into the potential of large language models (LLMs) to expedite the evolution cycle of data-centric R&D. Assessing the foundational elements of data-centric R&D, including heterogeneous task-related data, multi-facet domain knowledge, and diverse computing-functional tools, we explore how well LLMs can understand domain-specific requirements, generate professional ideas, utilize domain-specific tools to conduct experiments, interpret results, and incorporate knowledge from past endeavors to tackle new challenges. We take quantitative investment research as a typical example of industrial data-centric R&D scenario and verified our proposed framework upon our full-stack open-sourced quantitative research platform Qlib and obtained promising results which shed light on our vision of automatic evolving of industrial data-centric R&D cycle.
Smootheness-Adaptive Dynamic Pricing with Nonparametric Demand Learning
Oct 11, 2023We study the dynamic pricing problem where the demand function is nonparametric and H\"older smooth, and we focus on adaptivity to the unknown H\"older smoothness parameter $\beta$ of the demand function. Traditionally the optimal dynamic pricing algorithm heavily relies on the knowledge of $\beta$ to achieve a minimax optimal regret of $\widetilde{O}(T^{\frac{\beta+1}{2\beta+1}})$. However, we highlight the challenge of adaptivity in this dynamic pricing problem by proving that no pricing policy can adaptively achieve this minimax optimal regret without knowledge of $\beta$. Motivated by the impossibility result, we propose a self-similarity condition to enable adaptivity. Importantly, we show that the self-similarity condition does not compromise the problem's inherent complexity since it preserves the regret lower bound $\Omega(T^{\frac{\beta+1}{2\beta+1}})$. Furthermore, we develop a smoothness-adaptive dynamic pricing algorithm and theoretically prove that the algorithm achieves this minimax optimal regret bound without the prior knowledge $\beta$.