 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning as Gradient: Scaling MLE Agents Beyond Tree Search
Mar 02, 2026LLM-based agents for machine learning engineering (MLE) predominantly rely on tree search, a form of gradient-free optimization that uses scalar validation scores to rank candidates. As LLM reasoning capabilities improve, exhaustive enumeration becomes increasingly inefficient compared to directed updates, analogous to how accurate gradients enable efficient descent over random search. We introduce \textsc{Gome}, an MLE agent that operationalizes gradient-based optimization. \textsc{Gome} maps structured diagnostic reasoning to gradient computation, success memory to momentum, and multi-trace execution to distributed optimization. Under a closed-world protocol that isolates architectural effects from external knowledge, \textsc{Gome} achieves a state-of-the-art 35.1\% any-medal rate on MLE-Bench with a restricted 12-hour budget on a single V100 GPU. Scaling experiments across 10 models reveal a critical crossover: with weaker models, tree search retains advantages by compensating for unreliable reasoning through exhaustive exploration; as reasoning capability strengthens, gradient-based optimization progressively outperforms, with the gap widening at frontier-tier models. Given the rapid advancement of reasoning-oriented LLMs, this positions gradient-based optimization as an increasingly favorable paradigm. We release our codebase and GPT-5 traces.
FT-Dojo: Towards Autonomous LLM Fine-Tuning with Language Agents
Mar 02, 2026Fine-tuning large language models for vertical domains remains a labor-intensive and expensive process, requiring domain experts to curate data, configure training, and iteratively diagnose model behavior. Despite growing interest in autonomous machine learning, no prior work has tackled end-to-end LLM fine-tuning with agents. Can LLM-based agents automate this complete process? We frame this as a substantially open problem: agents must navigate an open-ended search space spanning data curation from diverse data sources, processing with complex tools, building a training pipeline, and iteratively refining their approach based on evaluation outcomes in rapidly growing logs--an overall scenario far more intricate than existing benchmarks. To study this question, we introduce FT-Dojo, an interactive environment comprising 13 tasks across 5 domains. We further develop FT-Agent, an autonomous system that mirrors human experts by leveraging evaluation-driven feedback to iteratively diagnose failures and refine fine-tuning strategies. Experiments on FT-Dojo demonstrate that purpose-built fine-tuning agents significantly outperform general-purpose alternatives, with FT-Agent achieving the best performance on 10 out of 13 tasks across all five domains. Ablations show that the approach generalizes effectively to 3B models, with additional insights on data scaling trade-offs and backbone sensitivity. Case analyses reveal that agents can recover from failures through cumulative learning from historical experience, while also exposing fundamental limitations in causal reasoning--highlighting both the promise and current boundaries of autonomous LLM fine-tuning.
Less Is More: Generating Time Series with LLaMA-Style Autoregression in Simple Factorized Latent Spaces
Nov 07, 2025Generative models for multivariate time series are essential for data augmentation, simulation, and privacy preservation, yet current state-of-the-art diffusion-based approaches are slow and limited to fixed-length windows. We propose FAR-TS, a simple yet effective framework that combines disentangled factorization with an autoregressive Transformer over a discrete, quantized latent space to generate time series. Each time series is decomposed into a data-adaptive basis that captures static cross-channel correlations and temporal coefficients that are vector-quantized into discrete tokens. A LLaMA-style autoregressive Transformer then models these token sequences, enabling fast and controllable generation of sequences with arbitrary length. Owing to its streamlined design, FAR-TS achieves orders-of-magnitude faster generation than Diffusion-TS while preserving cross-channel correlations and an interpretable latent space, enabling high-quality and flexible time series synthesis.
R&D-Agent-Quant: A Multi-Agent Framework for Data-Centric Factors and Model Joint Optimization
May 21, 2025



Financial markets pose fundamental challenges for asset return prediction due to their high dimensionality, non-stationarity, and persistent volatility. Despite advances in large language models and multi-agent systems, current quantitative research pipelines suffer from limited automation, weak interpretability, and fragmented coordination across key components such as factor mining and model innovation. In this paper, we propose R&D-Agent for Quantitative Finance, in short RD-Agent(Q), the first data-centric multi-agent framework designed to automate the full-stack research and development of quantitative strategies via coordinated factor-model co-optimization. RD-Agent(Q) decomposes the quant process into two iterative stages: a Research stage that dynamically sets goal-aligned prompts, formulates hypotheses based on domain priors, and maps them to concrete tasks, and a Development stage that employs a code-generation agent, Co-STEER, to implement task-specific code, which is then executed in real-market backtests. The two stages are connected through a feedback stage that thoroughly evaluates experimental outcomes and informs subsequent iterations, with a multi-armed bandit scheduler for adaptive direction selection. Empirically, RD-Agent(Q) achieves up to 2X higher annualized returns than classical factor libraries using 70% fewer factors, and outperforms state-of-the-art deep time-series models on real markets. Its joint factor-model optimization delivers a strong balance between predictive accuracy and strategy robustness. Our code is available at: https://github.com/microsoft/RD-Agent.
R&D-Agent: Automating Data-Driven AI Solution Building Through LLM-Powered Automated Research, Development, and Evolution
May 20, 2025Recent advances in AI and ML have transformed data science, yet increasing complexity and expertise requirements continue to hinder progress. While crowdsourcing platforms alleviate some challenges, high-level data science tasks remain labor-intensive and iterative. To overcome these limitations, we introduce R&D-Agent, a dual-agent framework for iterative exploration. The Researcher agent uses performance feedback to generate ideas, while the Developer agent refines code based on error feedback. By enabling multiple parallel exploration traces that merge and enhance one another, R&D-Agent narrows the gap between automated solutions and expert-level performance. Evaluated on MLE-Bench, R&D-Agent emerges as the top-performing machine learning engineering agent, demonstrating its potential to accelerate innovation and improve precision across diverse data science applications. We have open-sourced R&D-Agent on GitHub: https://github.com/microsoft/RD-Agent.
Generating Full-field Evolution of Physical Dynamics from Irregular Sparse Observations
May 14, 2025Modeling and reconstructing multidimensional physical dynamics from sparse and off-grid observations presents a fundamental challenge in scientific research. Recently, diffusion-based generative modeling shows promising potential for physical simulation. However, current approaches typically operate on on-grid data with preset spatiotemporal resolution, but struggle with the sparsely observed and continuous nature of real-world physical dynamics. To fill the gaps, we present SDIFT, Sequential DIffusion in Functional Tucker space, a novel framework that generates full-field evolution of physical dynamics from irregular sparse observations. SDIFT leverages the functional Tucker model as the latent space representer with proven universal approximation property, and represents observations as latent functions and Tucker core sequences. We then construct a sequential diffusion model with temporally augmented UNet in the functional Tucker space, denoising noise drawn from a Gaussian process to generate the sequence of core tensors. At the posterior sampling stage, we propose a Message-Passing Posterior Sampling mechanism, enabling conditional generation of the entire sequence guided by observations at limited time steps. We validate SDIFT on three physical systems spanning astronomical (supernova explosions, light-year scale), environmental (ocean sound speed fields, kilometer scale), and molecular (organic liquid, millimeter scale) domains, demonstrating significant improvements in both reconstruction accuracy and computational efficiency compared to state-of-the-art approaches.
Generalized Temporal Tensor Decomposition with Rank-revealing Latent-ODE
Feb 10, 2025Tensor decomposition is a fundamental tool for analyzing multi-dimensional data by learning low-rank factors to represent high-order interactions. While recent works on temporal tensor decomposition have made significant progress by incorporating continuous timestamps in latent factors, they still struggle with general tensor data with continuous indexes not only in the temporal mode but also in other modes, such as spatial coordinates in climate data. Additionally, the problem of determining the tensor rank remains largely unexplored in temporal tensor models. To address these limitations, we propose \underline{G}eneralized temporal tensor decomposition with \underline{R}ank-r\underline{E}vealing laten\underline{T}-ODE (GRET). Our approach encodes continuous spatial indexes as learnable Fourier features and employs neural ODEs in latent space to learn the temporal trajectories of factors. To automatically reveal the rank of temporal tensors, we introduce a rank-revealing Gaussian-Gamma prior over the factor trajectories. We develop an efficient variational inference scheme with an analytical evidence lower bound, enabling sampling-free optimization. Through extensive experiments on both synthetic and real-world datasets, we demonstrate that GRET not only reveals the underlying ranks of temporal tensors but also significantly outperforms existing methods in prediction performance and robustness against noise.
BPQP: A Differentiable Convex Optimization Framework for Efficient End-to-End Learning
Nov 28, 2024Data-driven decision-making processes increasingly utilize end-to-end learnable deep neural networks to render final decisions. Sometimes, the output of the forward functions in certain layers is determined by the solutions to mathematical optimization problems, leading to the emergence of differentiable optimization layers that permit gradient back-propagation. However, real-world scenarios often involve large-scale datasets and numerous constraints, presenting significant challenges. Current methods for differentiating optimization problems typically rely on implicit differentiation, which necessitates costly computations on the Jacobian matrices, resulting in low efficiency. In this paper, we introduce BPQP, a differentiable convex optimization framework designed for efficient end-to-end learning. To enhance efficiency, we reformulate the backward pass as a simplified and decoupled quadratic programming problem by leveraging the structural properties of the KKT matrix. This reformulation enables the use of first-order optimization algorithms in calculating the backward pass gradients, allowing our framework to potentially utilize any state-of-the-art solver. As solver technologies evolve, BPQP can continuously adapt and improve its efficiency. Extensive experiments on both simulated and real-world datasets demonstrate that BPQP achieves a significant improvement in efficiency--typically an order of magnitude faster in overall execution time compared to other differentiable optimization layers. Our results not only highlight the efficiency gains of BPQP but also underscore its superiority over differentiable optimization layer baselines.
Collaborative Evolving Strategy for Automatic Data-Centric Development
Jul 26, 2024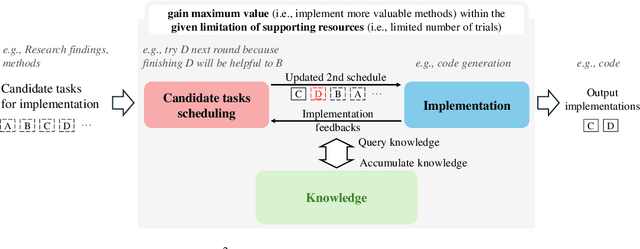

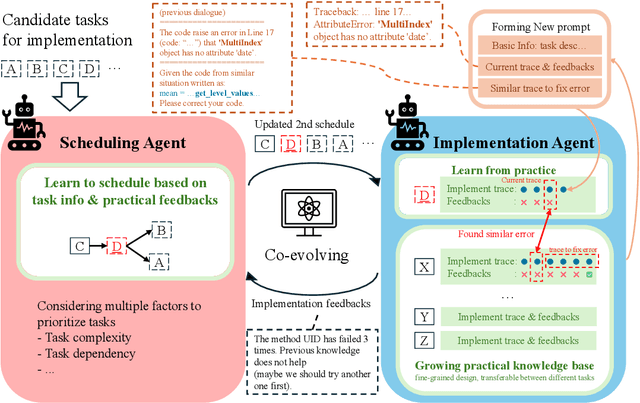
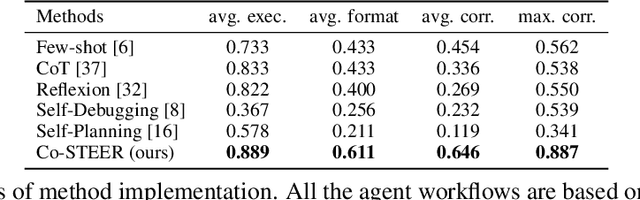
Artificial Intelligence (AI) significantly influences many fields, largely thanks to the vast amounts of high-quality data for machine learning models. The emphasis is now on a data-centric AI strategy, prioritizing data development over model design progress. Automating this process is crucial. In this paper, we serve as the first work to introduce the automatic data-centric development (AD^2) task and outline its core challenges, which require domain-experts-like task scheduling and implementation capability, largely unexplored by previous work. By leveraging the strong complex problem-solving capabilities of large language models (LLMs), we propose an LLM-based autonomous agent, equipped with a strategy named Collaborative Knowledge-STudying-Enhanced Evolution by Retrieval (Co-STEER), to simultaneously address all the challenges. Specifically, our proposed Co-STEER agent enriches its domain knowledge through our proposed evolving strategy and develops both its scheduling and implementation skills by accumulating and retrieving domain-specific practical experience. With an improved schedule, the capability for implementation accelerates. Simultaneously, as implementation feedback becomes more thorough, the scheduling accuracy increases. These two capabilities evolve together through practical feedback, enabling a collaborative evolution process. Extensive experimental results demonstrate that our Co-STEER agent breaks new ground in AD^2 research, possesses strong evolvable schedule and implementation ability, and demonstrates the significant effectiveness of its components. Our Co-STEER paves the way for AD^2 advancements.
RD2Bench: Toward Data-Centric Automatic R&D
Apr 17, 2024



The progress of humanity is driven by those successful discoveries accompanied by countless failed experiments. Researchers often seek the potential research directions by reading and then verifying them through experiments. The process imposes a significant burden on researchers. In the past decade, the data-driven black-box deep learning method demonstrates its effectiveness in a wide range of real-world scenarios, which exacerbates the experimental burden of researchers and thus renders the potential successful discoveries veiled. Therefore, automating such a research and development (R&D) process is an urgent need. In this paper, we serve as the first effort to formalize the goal by proposing a Real-world Data-centric automatic R&D Benchmark, namely RD2Bench. RD2Bench benchmarks all the operations in data-centric automatic R&D (D-CARD) as a whole to navigate future work toward our goal directly. We focuses on evaluating the interaction and synergistic effects of various model capabilities and aiding to select the well-performed trustworthy models. Although RD2Bench is very challenging to the state-of-the-art (SOTA) large language model (LLM) named GPT-4, indicating ample research opportunities and more research efforts, LLMs possess promising potential to bring more significant development to D-CARD: They are able to implement some simple methods without adopting any additional techniques. We appeal to future work to take developing techniques for tackling automatic R&D into consideration, thus bringing the opportunities of the potential revolutionary upgrade to human productivity.