 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR&D-Agent: Automating Data-Driven AI Solution Building Through LLM-Powered Automated Research, Development, and Evolution
May 20, 2025Recent advances in AI and ML have transformed data science, yet increasing complexity and expertise requirements continue to hinder progress. While crowdsourcing platforms alleviate some challenges, high-level data science tasks remain labor-intensive and iterative. To overcome these limitations, we introduce R&D-Agent, a dual-agent framework for iterative exploration. The Researcher agent uses performance feedback to generate ideas, while the Developer agent refines code based on error feedback. By enabling multiple parallel exploration traces that merge and enhance one another, R&D-Agent narrows the gap between automated solutions and expert-level performance. Evaluated on MLE-Bench, R&D-Agent emerges as the top-performing machine learning engineering agent, demonstrating its potential to accelerate innovation and improve precision across diverse data science applications. We have open-sourced R&D-Agent on GitHub: https://github.com/microsoft/RD-Agent.
SO-Pose: SO-Equivariance Learning for 6D Object Pose Estimation
Aug 17, 2022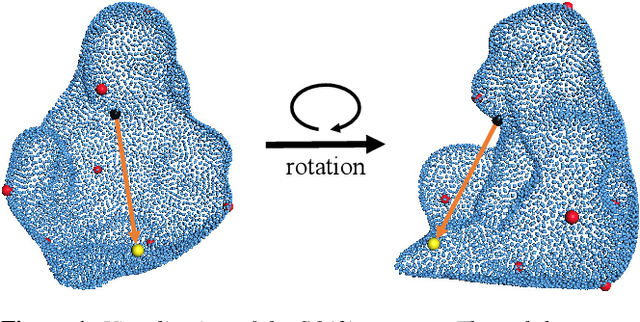
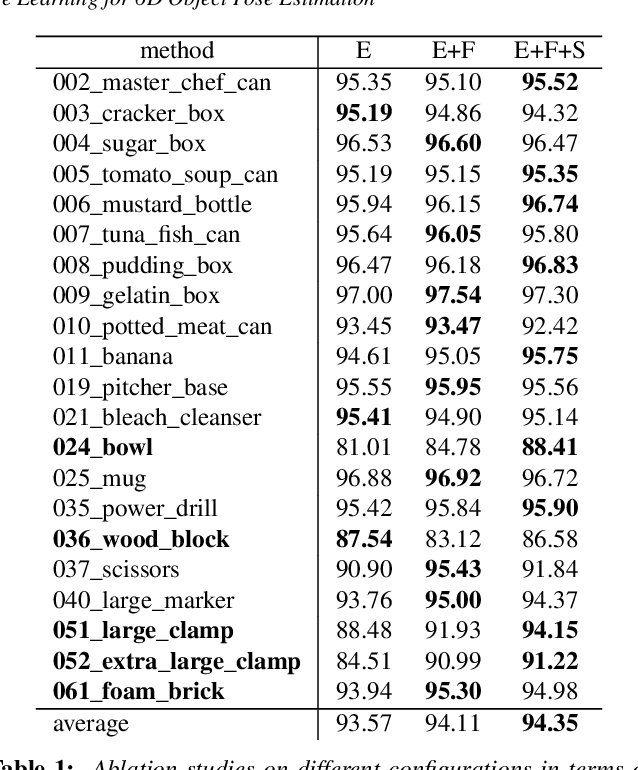

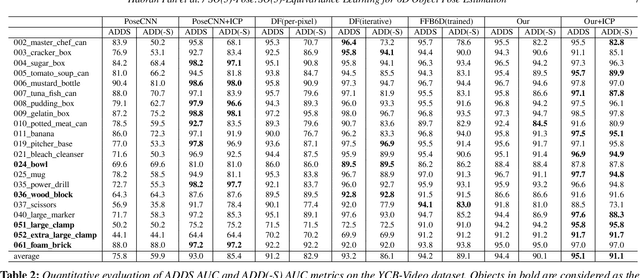
6D pose estimation of rigid objects from RGB-D images is crucial for object grasping and manipulation in robotics. Although RGB channels and the depth (D) channel are often complementary, providing respectively the appearance and geometry information, it is still non-trivial how to fully benefit from the two cross-modal data. From the simple yet new observation, when an object rotates, its semantic label is invariant to the pose while its keypoint offset direction is variant to the pose. To this end, we present SO(3)-Pose, a new representation learning network to explore SO(3)-equivariant and SO(3)-invariant features from the depth channel for pose estimation. The SO(3)-invariant features facilitate to learn more distinctive representations for segmenting objects with similar appearance from RGB channels. The SO(3)-equivariant features communicate with RGB features to deduce the (missed) geometry for detecting keypoints of an object with the reflective surface from the depth channel. Unlike most of existing pose estimation methods, our SO(3)-Pose not only implements the information communication between the RGB and depth channels, but also naturally absorbs the SO(3)-equivariance geometry knowledge from depth images, leading to better appearance and geometry representation learning. Comprehensive experiments show that our method achieves the state-of-the-art performance on three benchmarks.