 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverse Rendering for High-Genus 3D Surface Meshes from Multi-view Images with Persistent Homology Priors
Jan 17, 2026Reconstructing 3D objects from images is inherently an ill-posed problem due to ambiguities in geometry, appearance, and topology. This paper introduces collaborative inverse rendering with persistent homology priors, a novel strategy that leverages topological constraints to resolve these ambiguities. By incorporating priors that capture critical features such as tunnel loops and handle loops, our approach directly addresses the difficulty of reconstructing high-genus surfaces. The collaboration between photometric consistency from multi-view images and homology-based guidance enables recovery of complex high-genus geometry while circumventing catastrophic failures such as collapsing tunnels or losing high-genus structure. Instead of neural networks, our method relies on gradient-based optimization within a mesh-based inverse rendering framework to highlight the role of topological priors. Experimental results show that incorporating persistent homology priors leads to lower Chamfer Distance (CD) and higher Volume IoU compared to state-of-the-art mesh-based methods, demonstrating improved geometric accuracy and robustness against topological failure.
Learning Domain Agnostic Latent Embeddings of 3D Faces for Zero-shot Animal Expression Transfer
Jan 10, 2026We present a zero-shot framework for transferring human facial expressions to 3D animal face meshes. Our method combines intrinsic geometric descriptors (HKS/WKS) with a mesh-agnostic latent embedding that disentangles facial identity and expression. The ID latent space captures species-independent facial structure, while the expression latent space encodes deformation patterns that generalize across humans and animals. Trained only with human expression pairs, the model learns the embeddings, decoupling, and recoupling of cross-identity expressions, enabling expression transfer without requiring animal expression data. To enforce geometric consistency, we employ Jacobian loss together with vertex-position and Laplacian losses. Experiments show that our approach achieves plausible cross-species expression transfer, effectively narrowing the geometric gap between human and animal facial shapes.
SO-Pose: SO-Equivariance Learning for 6D Object Pose Estimation
Aug 17, 2022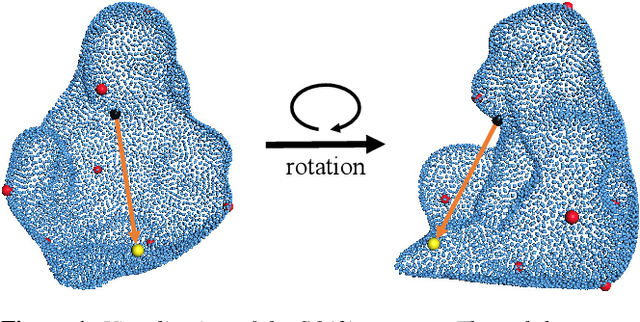
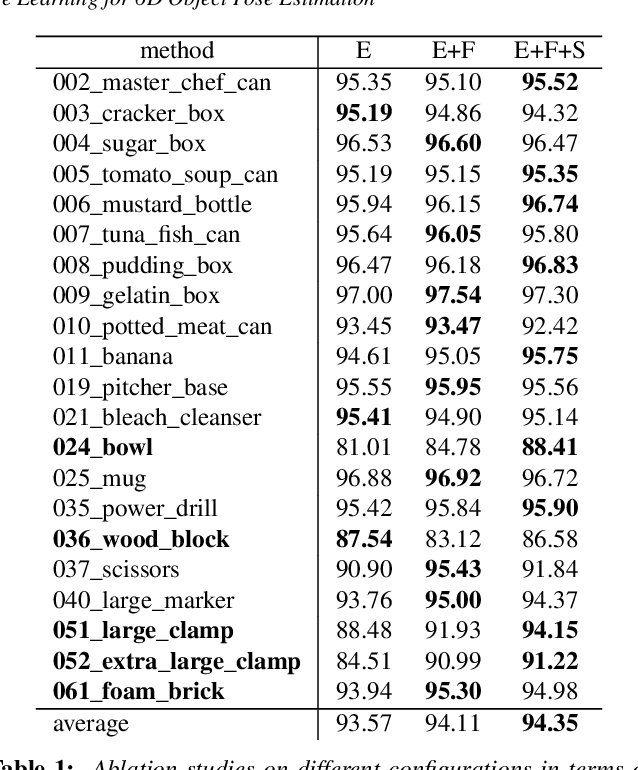

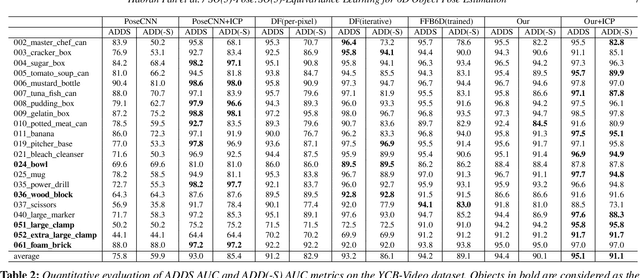
6D pose estimation of rigid objects from RGB-D images is crucial for object grasping and manipulation in robotics. Although RGB channels and the depth (D) channel are often complementary, providing respectively the appearance and geometry information, it is still non-trivial how to fully benefit from the two cross-modal data. From the simple yet new observation, when an object rotates, its semantic label is invariant to the pose while its keypoint offset direction is variant to the pose. To this end, we present SO(3)-Pose, a new representation learning network to explore SO(3)-equivariant and SO(3)-invariant features from the depth channel for pose estimation. The SO(3)-invariant features facilitate to learn more distinctive representations for segmenting objects with similar appearance from RGB channels. The SO(3)-equivariant features communicate with RGB features to deduce the (missed) geometry for detecting keypoints of an object with the reflective surface from the depth channel. Unlike most of existing pose estimation methods, our SO(3)-Pose not only implements the information communication between the RGB and depth channels, but also naturally absorbs the SO(3)-equivariance geometry knowledge from depth images, leading to better appearance and geometry representation learning. Comprehensive experiments show that our method achieves the state-of-the-art performance on three benchmarks.
Automatic CT Segmentation from Bounding Box Annotations using Convolutional Neural Networks
Jun 09, 2021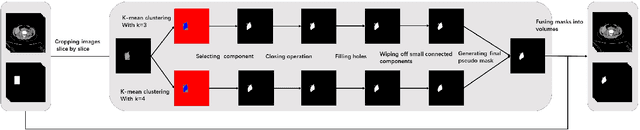
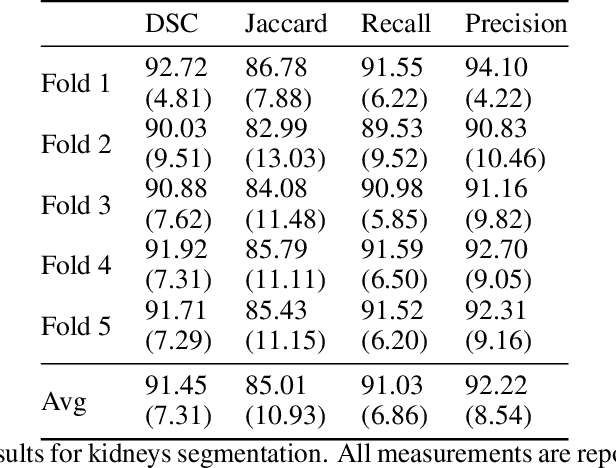
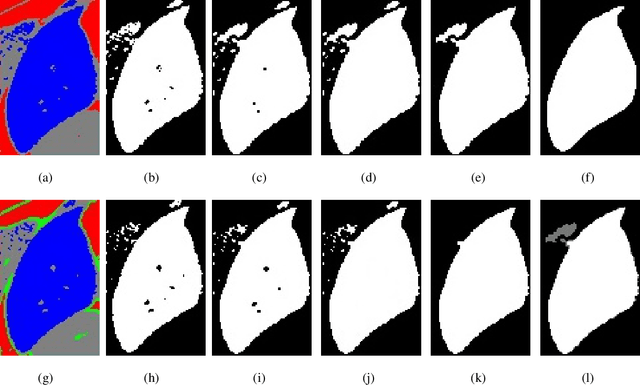
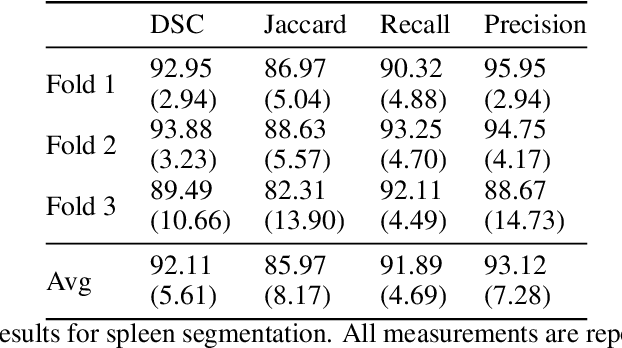
Accurate segmentation for medical images is important for clinical diagnosis. Existing automatic segmentation methods are mainly based on fully supervised learning and have an extremely high demand for precise annotations, which are very costly and time-consuming to obtain. To address this problem, we proposed an automatic CT segmentation method based on weakly supervised learning, by which one could train an accurate segmentation model only with weak annotations in the form of bounding boxes. The proposed method is composed of two steps: 1) generating pseudo masks with bounding box annotations by k-means clustering, and 2) iteratively training a 3D U-Net convolutional neural network as a segmentation model. Some data pre-processing methods are used to improve performance. The method was validated on four datasets containing three types of organs with a total of 627 CT volumes. For liver, spleen and kidney segmentation, it achieved an accuracy of 95.19%, 92.11%, and 91.45%, respectively. Experimental results demonstrate that our method is accurate, efficient, and suitable for clinical use.
Deep learning for prediction of hepatocellular carcinoma recurrence after resection or liver transplantation: a discovery and validation study
May 31, 2021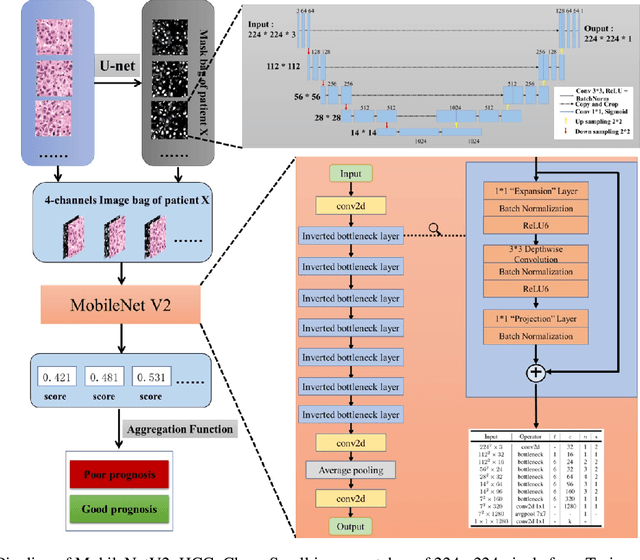
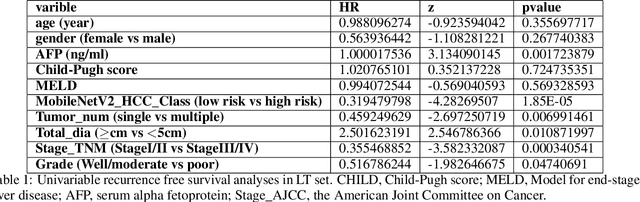
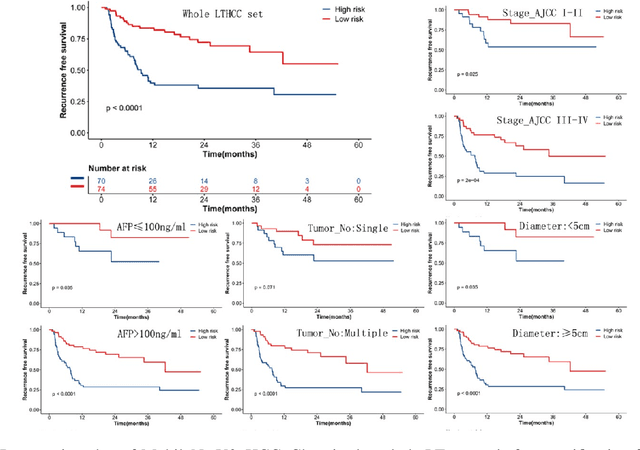
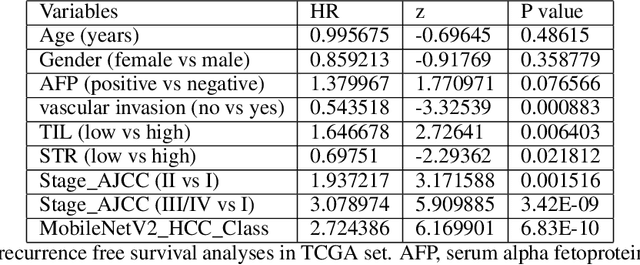
This study aimed to develop a classifier of prognosis after resection or liver transplantation (LT) for HCC by directly analysing the ubiquitously available histological images using deep learning based neural networks. Nucleus map set was used to train U-net to capture the nuclear architectural information. Train set included the patients with HCC treated by resection and has a distinct outcome. LT set contained patients with HCC treated by LT. Train set and its nuclear architectural information extracted by U-net were used to train MobileNet V2 based classifier (MobileNetV2_HCC_Class), purpose-built for classifying supersized heterogeneous images. The MobileNetV2_HCC_Class maintained relative higher discriminatory power than the other factors after HCC resection or LT in the independent validation set. Pathological review showed that the tumoral areas most predictive of recurrence were characterized by presence of stroma, high degree of cytological atypia, nuclear hyperchomasia, and a lack of immune infiltration. A clinically useful prognostic classifier was developed using deep learning allied to histological slides. The classifier has been extensively evaluated in independent patient populations with different treatment, and gives consistent excellent results across the classical clinical, biological and pathological features. The classifier assists in refining the prognostic prediction of HCC patients and identifying patients who would benefit from more intensive management.
3DPVNet: Patch-level 3D Hough Voting Network for 6D Pose Estimation
Sep 15, 2020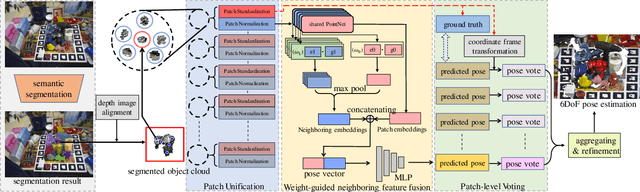

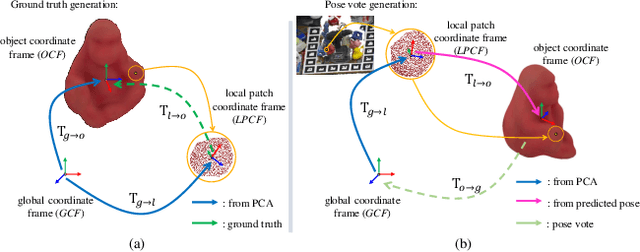
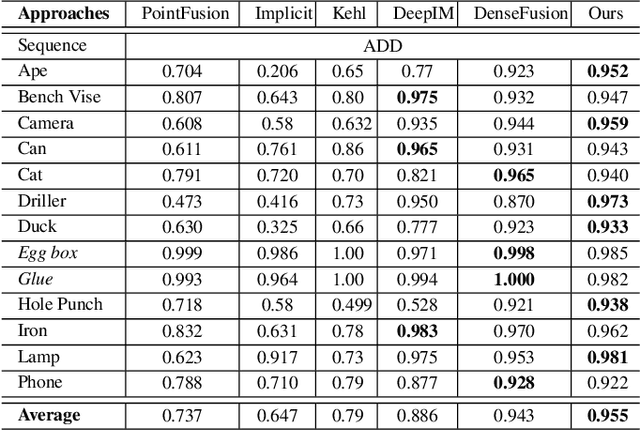
In this paper, we focus on estimating the 6D pose of objects in point clouds. Although the topic has been widely studied, pose estimation in point clouds remains a challenging problem due to the noise and occlusion. To address the problem, a novel 3DPVNet is presented in this work, which utilizes 3D local patches to vote for the object 6D poses. 3DPVNet is comprised of three modules. In particular, a Patch Unification (\textbf{PU}) module is first introduced to normalize the input patch, and also create a standard local coordinate frame on it to generate a reliable vote. We then devise a Weight-guided Neighboring Feature Fusion (\textbf{WNFF}) module in the network, which fuses the neighboring features to yield a semi-global feature for the center patch. WNFF module mines the neighboring information of a local patch, such that the representation capability to local geometric characteristics is significantly enhanced, making the method robust to a certain level of noise. Moreover, we present a Patch-level Voting (\textbf{PV}) module to regress transformations and generates pose votes. After the aggregation of all votes from patches and a refinement step, the final pose of the object can be obtained. Compared to recent voting-based methods, 3DPVNet is patch-level, and directly carried out on point clouds. Therefore, 3DPVNet achieves less computation than point/pixel-level voting scheme, and has robustness to partial data. Experiments on several datasets demonstrate that 3DPVNet achieves the state-of-the-art performance, and is also robust against noise and occlusions.