 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExoGS: A 4D Real-to-Sim-to-Real Framework for Scalable Manipulation Data Collection
Jan 26, 2026Real-to-Sim-to-Real technique is gaining increasing interest for robotic manipulation, as it can generate scalable data in simulation while having narrower sim-to-real gap. However, previous methods mainly focused on environment-level visual real-to-sim transfer, ignoring the transfer of interactions, which could be challenging and inefficient to obtain purely in simulation especially for contact-rich tasks. We propose ExoGS, a robot-free 4D Real-to-Sim-to-Real framework that captures both static environments and dynamic interactions in the real world and transfers them seamlessly to a simulated environment. It provides a new solution for scalable manipulation data collection and policy learning. ExoGS employs a self-designed robot-isomorphic passive exoskeleton AirExo-3 to capture kinematically consistent trajectories with millimeter-level accuracy and synchronized RGB observations during direct human demonstrations. The robot, objects, and environment are reconstructed as editable 3D Gaussian Splatting assets, enabling geometry-consistent replay and large-scale data augmentation. Additionally, a lightweight Mask Adapter injects instance-level semantics into the policy to enhance robustness under visual domain shifts. Real-world experiments demonstrate that ExoGS significantly improves data efficiency and policy generalization compared to teleoperation-based baselines. Code and hardware files have been released on https://github.com/zaixiabalala/ExoGS.
Dynamic Stream Network for Combinatorial Explosion Problem in Deformable Medical Image Registration
Dec 22, 2025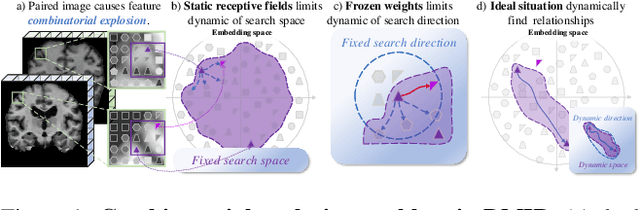
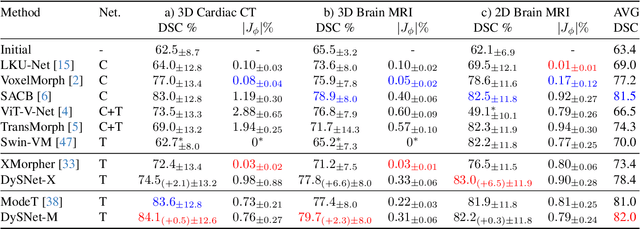
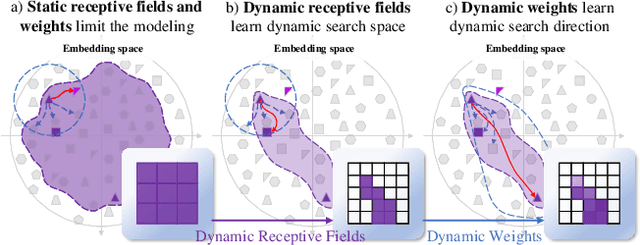
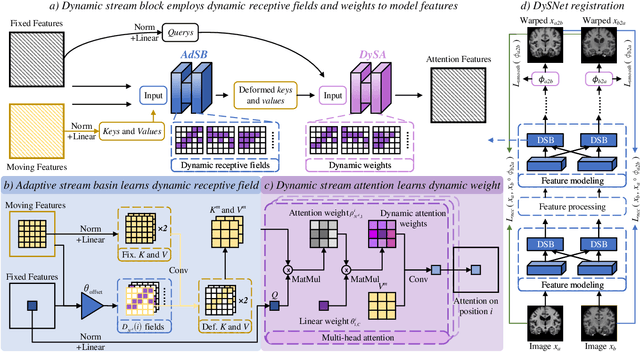
Combinatorial explosion problem caused by dual inputs presents a critical challenge in Deformable Medical Image Registration (DMIR). Since DMIR processes two images simultaneously as input, the combination relationships between features has grown exponentially, ultimately the model considers more interfering features during the feature modeling process. Introducing dynamics in the receptive fields and weights of the network enable the model to eliminate the interfering features combination and model the potential feature combination relationships. In this paper, we propose the Dynamic Stream Network (DySNet), which enables the receptive fields and weights to be dynamically adjusted. This ultimately enables the model to ignore interfering feature combinations and model the potential feature relationships. With two key innovations: 1) Adaptive Stream Basin (AdSB) module dynamically adjusts the shape of the receptive field, thereby enabling the model to focus on the feature relationships with greater correlation. 2) Dynamic Stream Attention (DySA) mechanism generates dynamic weights to search for more valuable feature relationships. Extensive experiments have shown that DySNet consistently outperforms the most advanced DMIR methods, highlighting its outstanding generalization ability. Our code will be released on the website: https://github.com/ShaochenBi/DySNet.
Neural Co-Optimization of Structural Topology, Manufacturable Layers, and Path Orientations for Fiber-Reinforced Composites
Apr 30, 2025We propose a neural network-based computational framework for the simultaneous optimization of structural topology, curved layers, and path orientations to achieve strong anisotropic strength in fiber-reinforced thermoplastic composites while ensuring manufacturability. Our framework employs three implicit neural fields to represent geometric shape, layer sequence, and fiber orientation. This enables the direct formulation of both design and manufacturability objectives - such as anisotropic strength, structural volume, machine motion control, layer curvature, and layer thickness - into an integrated and differentiable optimization process. By incorporating these objectives as loss functions, the framework ensures that the resultant composites exhibit optimized mechanical strength while remaining its manufacturability for filament-based multi-axis 3D printing across diverse hardware platforms. Physical experiments demonstrate that the composites generated by our co-optimization method can achieve an improvement of up to 33.1% in failure loads compared to composites with sequentially optimized structures and manufacturing sequences.
AirExo-2: Scaling up Generalizable Robotic Imitation Learning with Low-Cost Exoskeletons
Mar 05, 2025Scaling up imitation learning for real-world applications requires efficient and cost-effective demonstration collection methods. Current teleoperation approaches, though effective, are expensive and inefficient due to the dependency on physical robot platforms. Alternative data sources like in-the-wild demonstrations can eliminate the need for physical robots and offer more scalable solutions. However, existing in-the-wild data collection devices have limitations: handheld devices offer restricted in-hand camera observation, while whole-body devices often require fine-tuning with robot data due to action inaccuracies. In this paper, we propose AirExo-2, a low-cost exoskeleton system for large-scale in-the-wild demonstration collection. By introducing the demonstration adaptor to transform the collected in-the-wild demonstrations into pseudo-robot demonstrations, our system addresses key challenges in utilizing in-the-wild demonstrations for downstream imitation learning in real-world environments. Additionally, we present RISE-2, a generalizable policy that integrates 2D and 3D perceptions, outperforming previous imitation learning policies in both in-domain and out-of-domain tasks, even with limited demonstrations. By leveraging in-the-wild demonstrations collected and transformed by the AirExo-2 system, without the need for additional robot demonstrations, RISE-2 achieves comparable or superior performance to policies trained with teleoperated data, highlighting the potential of AirExo-2 for scalable and generalizable imitation learning. Project page: https://airexo.tech/airexo2
CrossTracker: Robust Multi-modal 3D Multi-Object Tracking via Cross Correction
Nov 28, 2024



The fusion of camera- and LiDAR-based detections offers a promising solution to mitigate tracking failures in 3D multi-object tracking (MOT). However, existing methods predominantly exploit camera detections to correct tracking failures caused by potential LiDAR detection problems, neglecting the reciprocal benefit of refining camera detections using LiDAR data. This limitation is rooted in their single-stage architecture, akin to single-stage object detectors, lacking a dedicated trajectory refinement module to fully exploit the complementary multi-modal information. To this end, we introduce CrossTracker, a novel two-stage paradigm for online multi-modal 3D MOT. CrossTracker operates in a coarse-to-fine manner, initially generating coarse trajectories and subsequently refining them through an independent refinement process. Specifically, CrossTracker incorporates three essential modules: i) a multi-modal modeling (M^3) module that, by fusing multi-modal information (images, point clouds, and even plane geometry extracted from images), provides a robust metric for subsequent trajectory generation. ii) a coarse trajectory generation (C-TG) module that generates initial coarse dual-stream trajectories, and iii) a trajectory refinement (TR) module that refines coarse trajectories through cross correction between camera and LiDAR streams. Comprehensive experiments demonstrate the superior performance of our CrossTracker over its eighteen competitors, underscoring its effectiveness in harnessing the synergistic benefits of camera and LiDAR sensors for robust multi-modal 3D MOT.
ForceMimic: Force-Centric Imitation Learning with Force-Motion Capture System for Contact-Rich Manipulation
Oct 11, 2024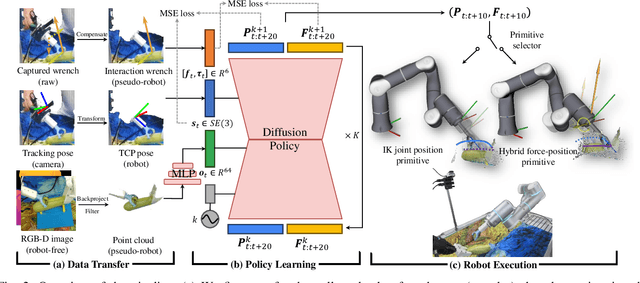
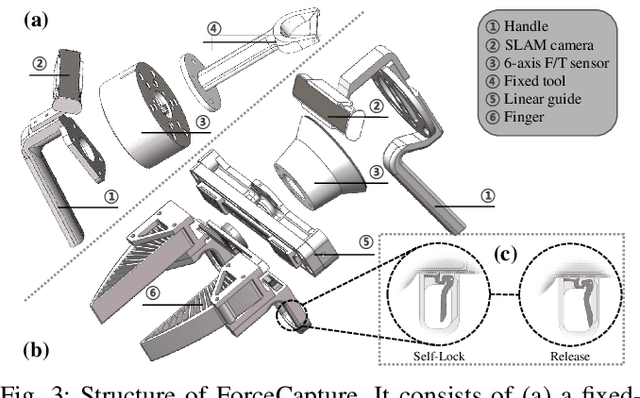
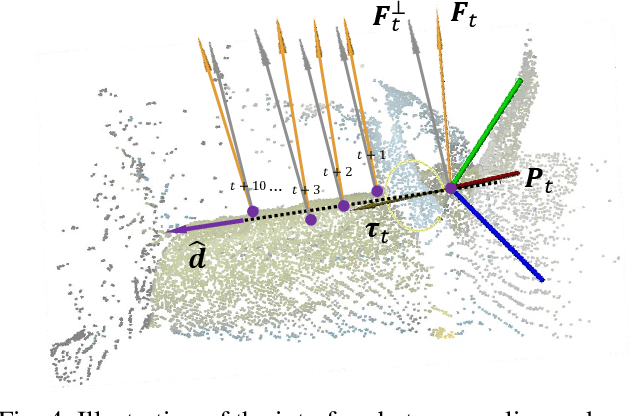
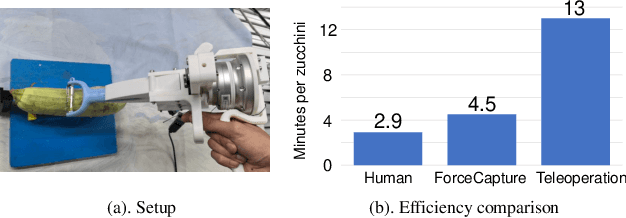
In most contact-rich manipulation tasks, humans apply time-varying forces to the target object, compensating for inaccuracies in the vision-guided hand trajectory. However, current robot learning algorithms primarily focus on trajectory-based policy, with limited attention given to learning force-related skills. To address this limitation, we introduce ForceMimic, a force-centric robot learning system, providing a natural, force-aware and robot-free robotic demonstration collection system, along with a hybrid force-motion imitation learning algorithm for robust contact-rich manipulation. Using the proposed ForceCapture system, an operator can peel a zucchini in 5 minutes, while force-feedback teleoperation takes over 13 minutes and struggles with task completion. With the collected data, we propose HybridIL to train a force-centric imitation learning model, equipped with hybrid force-position control primitive to fit the predicted wrench-position parameters during robot execution. Experiments demonstrate that our approach enables the model to learn a more robust policy under the contact-rich task of vegetable peeling, increasing the success rates by 54.5% relatively compared to state-of-the-art pure-vision-based imitation learning. Hardware, code, data and more results would be open-sourced on the project website at https://forcemimic.github.io.
Force-Centric Imitation Learning with Force-Motion Capture System for Contact-Rich Manipulation
Oct 10, 2024In most contact-rich manipulation tasks, humans apply time-varying forces to the target object, compensating for inaccuracies in the vision-guided hand trajectory. However, current robot learning algorithms primarily focus on trajectory-based policy, with limited attention given to learning force-related skills. To address this limitation, we introduce ForceMimic, a force-centric robot learning system, providing a natural, force-aware and robot-free robotic demonstration collection system, along with a hybrid force-motion imitation learning algorithm for robust contact-rich manipulation. Using the proposed ForceCapture system, an operator can peel a zucchini in 5 minutes, while force-feedback teleoperation takes over 13 minutes and struggles with task completion. With the collected data, we propose HybridIL to train a force-centric imitation learning model, equipped with hybrid force-position control primitive to fit the predicted wrench-position parameters during robot execution. Experiments demonstrate that our approach enables the model to learn a more robust policy under the contact-rich task of vegetable peeling, increasing the success rates by 54.5% relatively compared to state-of-the-art pure-vision-based imitation learning. Hardware, code, data and more results would be open-sourced on the project website at https://forcemimic.github.io.
Learning Based Toolpath Planner on Diverse Graphs for 3D Printing
Aug 17, 2024



This paper presents a learning based planner for computing optimized 3D printing toolpaths on prescribed graphs, the challenges of which include the varying graph structures on different models and the large scale of nodes & edges on a graph. We adopt an on-the-fly strategy to tackle these challenges, formulating the planner as a Deep Q-Network (DQN) based optimizer to decide the next `best' node to visit. We construct the state spaces by the Local Search Graph (LSG) centered at different nodes on a graph, which is encoded by a carefully designed algorithm so that LSGs in similar configurations can be identified to re-use the earlier learned DQN priors for accelerating the computation of toolpath planning. Our method can cover different 3D printing applications by defining their corresponding reward functions. Toolpath planning problems in wire-frame printing, continuous fiber printing, and metallic printing are selected to demonstrate its generality. The performance of our planner has been verified by testing the resultant toolpaths in physical experiments. By using our planner, wire-frame models with up to 4.2k struts can be successfully printed, up to 93.3% of sharp turns on continuous fiber toolpaths can be avoided, and the thermal distortion in metallic printing can be reduced by 24.9%.
RainMamba: Enhanced Locality Learning with State Space Models for Video Deraining
Jul 31, 2024



The outdoor vision systems are frequently contaminated by rain streaks and raindrops, which significantly degenerate the performance of visual tasks and multimedia applications. The nature of videos exhibits redundant temporal cues for rain removal with higher stability. Traditional video deraining methods heavily rely on optical flow estimation and kernel-based manners, which have a limited receptive field. Yet, transformer architectures, while enabling long-term dependencies, bring about a significant increase in computational complexity. Recently, the linear-complexity operator of the state space models (SSMs) has contrarily facilitated efficient long-term temporal modeling, which is crucial for rain streaks and raindrops removal in videos. Unexpectedly, its uni-dimensional sequential process on videos destroys the local correlations across the spatio-temporal dimension by distancing adjacent pixels. To address this, we present an improved SSMs-based video deraining network (RainMamba) with a novel Hilbert scanning mechanism to better capture sequence-level local information. We also introduce a difference-guided dynamic contrastive locality learning strategy to enhance the patch-level self-similarity learning ability of the proposed network. Extensive experiments on four synthesized video deraining datasets and real-world rainy videos demonstrate the superiority of our network in the removal of rain streaks and raindrops.
Lost in UNet: Improving Infrared Small Target Detection by Underappreciated Local Features
Jun 19, 2024
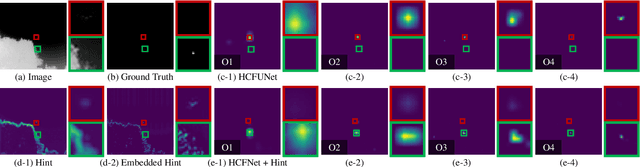


Many targets are often very small in infrared images due to the long-distance imaging meachnism. UNet and its variants, as popular detection backbone networks, downsample the local features early and cause the irreversible loss of these local features, leading to both the missed and false detection of small targets in infrared images. We propose HintU, a novel network to recover the local features lost by various UNet-based methods for effective infrared small target detection. HintU has two key contributions. First, it introduces the "Hint" mechanism for the first time, i.e., leveraging the prior knowledge of target locations to highlight critical local features. Second, it improves the mainstream UNet-based architecture to preserve target pixels even after downsampling. HintU can shift the focus of various networks (e.g., vanilla UNet, UNet++, UIUNet, MiM+, and HCFNet) from the irrelevant background pixels to a more restricted area from the beginning. Experimental results on three datasets NUDT-SIRST, SIRSTv2 and IRSTD1K demonstrate that HintU enhances the performance of existing methods with only an additional 1.88 ms cost (on RTX Titan). Additionally, the explicit constraints of HintU enhance the generalization ability of UNet-based methods. Code is available at https://github.com/Wuzhou-Quan/HintU.