 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExoGS: A 4D Real-to-Sim-to-Real Framework for Scalable Manipulation Data Collection
Jan 26, 2026Real-to-Sim-to-Real technique is gaining increasing interest for robotic manipulation, as it can generate scalable data in simulation while having narrower sim-to-real gap. However, previous methods mainly focused on environment-level visual real-to-sim transfer, ignoring the transfer of interactions, which could be challenging and inefficient to obtain purely in simulation especially for contact-rich tasks. We propose ExoGS, a robot-free 4D Real-to-Sim-to-Real framework that captures both static environments and dynamic interactions in the real world and transfers them seamlessly to a simulated environment. It provides a new solution for scalable manipulation data collection and policy learning. ExoGS employs a self-designed robot-isomorphic passive exoskeleton AirExo-3 to capture kinematically consistent trajectories with millimeter-level accuracy and synchronized RGB observations during direct human demonstrations. The robot, objects, and environment are reconstructed as editable 3D Gaussian Splatting assets, enabling geometry-consistent replay and large-scale data augmentation. Additionally, a lightweight Mask Adapter injects instance-level semantics into the policy to enhance robustness under visual domain shifts. Real-world experiments demonstrate that ExoGS significantly improves data efficiency and policy generalization compared to teleoperation-based baselines. Code and hardware files have been released on https://github.com/zaixiabalala/ExoGS.
ForceMimic: Force-Centric Imitation Learning with Force-Motion Capture System for Contact-Rich Manipulation
Oct 11, 2024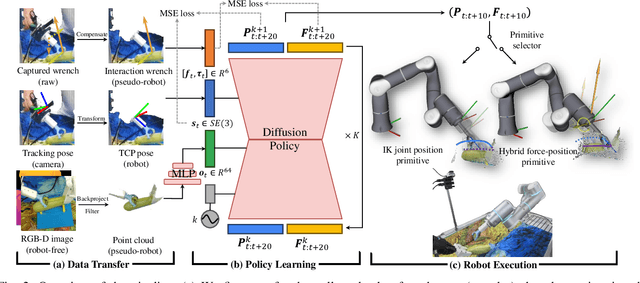
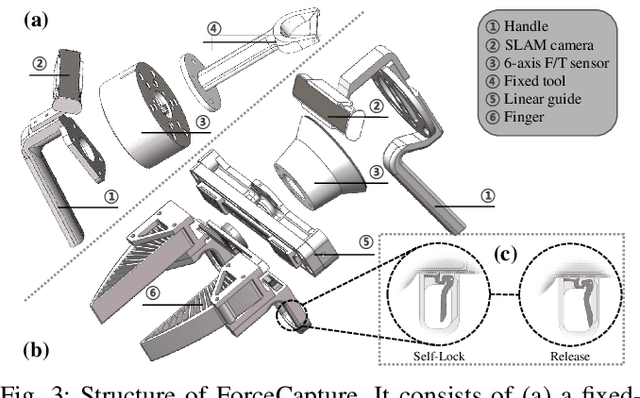
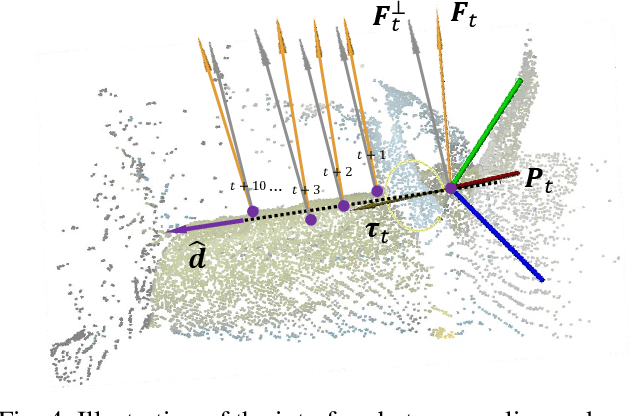
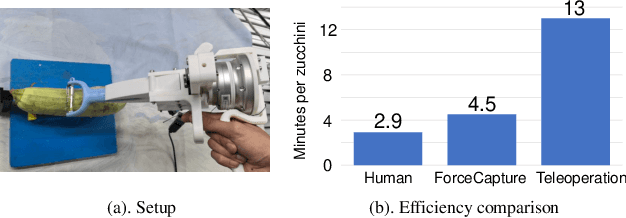
In most contact-rich manipulation tasks, humans apply time-varying forces to the target object, compensating for inaccuracies in the vision-guided hand trajectory. However, current robot learning algorithms primarily focus on trajectory-based policy, with limited attention given to learning force-related skills. To address this limitation, we introduce ForceMimic, a force-centric robot learning system, providing a natural, force-aware and robot-free robotic demonstration collection system, along with a hybrid force-motion imitation learning algorithm for robust contact-rich manipulation. Using the proposed ForceCapture system, an operator can peel a zucchini in 5 minutes, while force-feedback teleoperation takes over 13 minutes and struggles with task completion. With the collected data, we propose HybridIL to train a force-centric imitation learning model, equipped with hybrid force-position control primitive to fit the predicted wrench-position parameters during robot execution. Experiments demonstrate that our approach enables the model to learn a more robust policy under the contact-rich task of vegetable peeling, increasing the success rates by 54.5% relatively compared to state-of-the-art pure-vision-based imitation learning. Hardware, code, data and more results would be open-sourced on the project website at https://forcemimic.github.io.
Force-Centric Imitation Learning with Force-Motion Capture System for Contact-Rich Manipulation
Oct 10, 2024In most contact-rich manipulation tasks, humans apply time-varying forces to the target object, compensating for inaccuracies in the vision-guided hand trajectory. However, current robot learning algorithms primarily focus on trajectory-based policy, with limited attention given to learning force-related skills. To address this limitation, we introduce ForceMimic, a force-centric robot learning system, providing a natural, force-aware and robot-free robotic demonstration collection system, along with a hybrid force-motion imitation learning algorithm for robust contact-rich manipulation. Using the proposed ForceCapture system, an operator can peel a zucchini in 5 minutes, while force-feedback teleoperation takes over 13 minutes and struggles with task completion. With the collected data, we propose HybridIL to train a force-centric imitation learning model, equipped with hybrid force-position control primitive to fit the predicted wrench-position parameters during robot execution. Experiments demonstrate that our approach enables the model to learn a more robust policy under the contact-rich task of vegetable peeling, increasing the success rates by 54.5% relatively compared to state-of-the-art pure-vision-based imitation learning. Hardware, code, data and more results would be open-sourced on the project website at https://forcemimic.github.io.
RPMArt: Towards Robust Perception and Manipulation for Articulated Objects
Mar 24, 2024



Articulated objects are commonly found in daily life. It is essential that robots can exhibit robust perception and manipulation skills for articulated objects in real-world robotic applications. However, existing methods for articulated objects insufficiently address noise in point clouds and struggle to bridge the gap between simulation and reality, thus limiting the practical deployment in real-world scenarios. To tackle these challenges, we propose a framework towards Robust Perception and Manipulation for Articulated Objects (RPMArt), which learns to estimate the articulation parameters and manipulate the articulation part from the noisy point cloud. Our primary contribution is a Robust Articulation Network (RoArtNet) that is able to predict both joint parameters and affordable points robustly by local feature learning and point tuple voting. Moreover, we introduce an articulation-aware classification scheme to enhance its ability for sim-to-real transfer. Finally, with the estimated affordable point and articulation joint constraint, the robot can generate robust actions to manipulate articulated objects. After learning only from synthetic data, RPMArt is able to transfer zero-shot to real-world articulated objects. Experimental results confirm our approach's effectiveness, with our framework achieving state-of-the-art performance in both noise-added simulation and real-world environments. The code and data will be open-sourced for reproduction. More results are published on the project website at https://r-pmart.github.io .
ManiPose: A Comprehensive Benchmark for Pose-aware Object Manipulation in Robotics
Mar 20, 2024Robotic manipulation in everyday scenarios, especially in unstructured environments, requires skills in pose-aware object manipulation (POM), which adapts robots' grasping and handling according to an object's 6D pose. Recognizing an object's position and orientation is crucial for effective manipulation. For example, if a mug is lying on its side, it's more effective to grasp it by the rim rather than the handle. Despite its importance, research in POM skills remains limited, because learning manipulation skills requires pose-varying simulation environments and datasets. This paper introduces ManiPose, a pioneering benchmark designed to advance the study of pose-varying manipulation tasks. ManiPose encompasses: 1) Simulation environments for POM feature tasks ranging from 6D pose-specific pick-and-place of single objects to cluttered scenes, further including interactions with articulated objects. 2) A comprehensive dataset featuring geometrically consistent and manipulation-oriented 6D pose labels for 2936 real-world scanned rigid objects and 100 articulated objects across 59 categories. 3) A baseline for POM, leveraging the inferencing abilities of LLM (e.g., ChatGPT) to analyze the relationship between 6D pose and task-specific requirements, offers enhanced pose-aware grasp prediction and motion planning capabilities. Our benchmark demonstrates notable advancements in pose estimation, pose-aware manipulation, and real-robot skill transfer, setting new standards for POM research. We will open-source the ManiPose benchmark with the final version paper, inviting the community to engage with our resources, available at our website:https://sites.google.com/view/manipose.
GAMMA: Generalizable Articulation Modeling and Manipulation for Articulated Objects
Oct 04, 2023Articulated objects like cabinets and doors are widespread in daily life. However, directly manipulating 3D articulated objects is challenging because they have diverse geometrical shapes, semantic categories, and kinetic constraints. Prior works mostly focused on recognizing and manipulating articulated objects with specific joint types. They can either estimate the joint parameters or distinguish suitable grasp poses to facilitate trajectory planning. Although these approaches have succeeded in certain types of articulated objects, they lack generalizability to unseen objects, which significantly impedes their application in broader scenarios. In this paper, we propose a novel framework of Generalizable Articulation Modeling and Manipulating for Articulated Objects (GAMMA), which learns both articulation modeling and grasp pose affordance from diverse articulated objects with different categories. In addition, GAMMA adopts adaptive manipulation to iteratively reduce the modeling errors and enhance manipulation performance. We train GAMMA with the PartNet-Mobility dataset and evaluate with comprehensive experiments in SAPIEN simulation and real-world Franka robot. Results show that GAMMA significantly outperforms SOTA articulation modeling and manipulation algorithms in unseen and cross-category articulated objects. We will open-source all codes and datasets in both simulation and real robots for reproduction in the final version. Images and videos are published on the project website at: http://sites.google.com/view/gamma-articulation
AnyGrasp: Robust and Efficient Grasp Perception in Spatial and Temporal Domains
Dec 16, 2022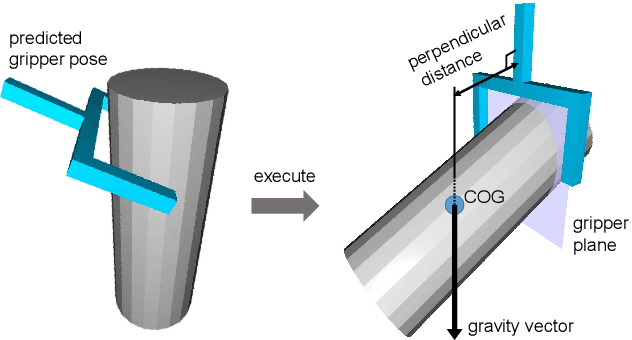
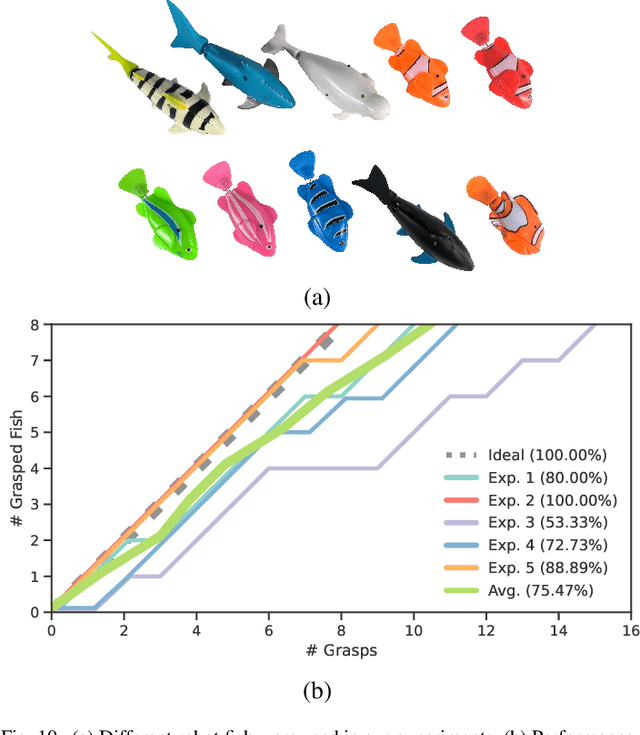

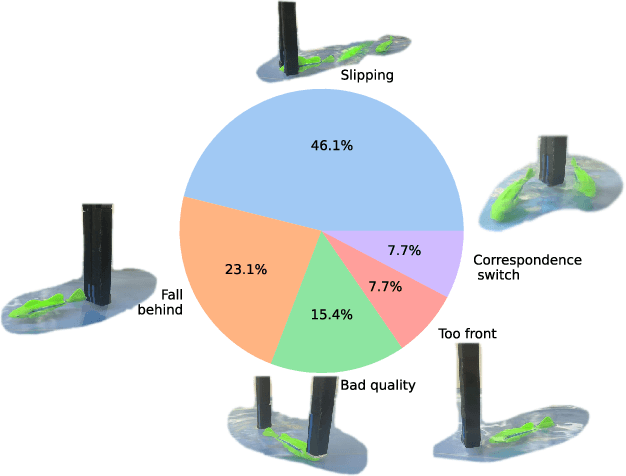
As the basis for prehensile manipulation, it is vital to enable robots to grasp as robustly as humans. In daily manipulation, our grasping system is prompt, accurate, flexible and continuous across spatial and temporal domains. Few existing methods cover all these properties for robot grasping. In this paper, we propose a new methodology for grasp perception to enable robots these abilities. Specifically, we develop a dense supervision strategy with real perception and analytic labels in the spatial-temporal domain. Additional awareness of objects' center-of-mass is incorporated into the learning process to help improve grasping stability. Utilization of grasp correspondence across observations enables dynamic grasp tracking. Our model, AnyGrasp, can generate accurate, full-DoF, dense and temporally-smooth grasp poses efficiently, and works robustly against large depth sensing noise. Embedded with AnyGrasp, we achieve a 93.3% success rate when clearing bins with over 300 unseen objects, which is comparable with human subjects under controlled conditions. Over 900 MPPH is reported on a single-arm system. For dynamic grasping, we demonstrate catching swimming robot fish in the water.
SAGCI-System: Towards Sample-Efficient, Generalizable, Compositional, and Incremental Robot Learning
Nov 30, 2021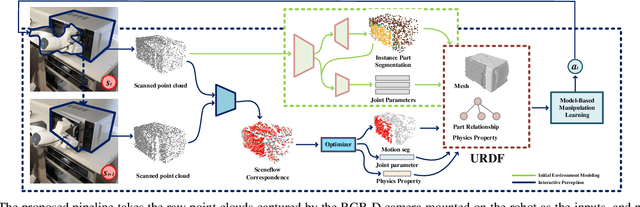
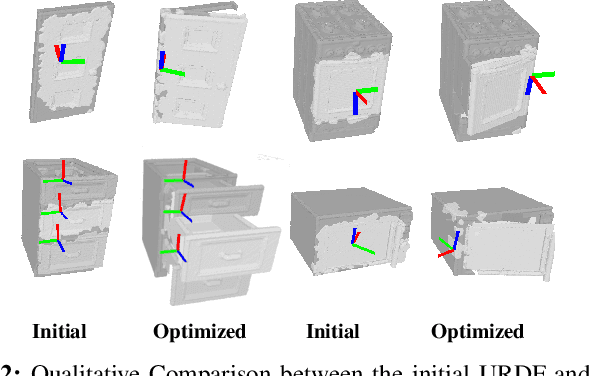
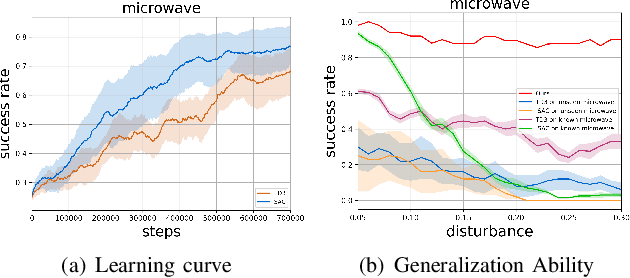

Building general-purpose robots to perform an enormous amount of tasks in a large variety of environments at the human level is notoriously complicated. It requires the robot learning to be sample-efficient, generalizable, compositional, and incremental. In this work, we introduce a systematic learning framework called SAGCI-system towards achieving these above four requirements. Our system first takes the raw point clouds gathered by the camera mounted on the robot's wrist as the inputs and produces initial modeling of the surrounding environment represented as a URDF. Our system adopts a learning-augmented differentiable simulation that loads the URDF. The robot then utilizes the interactive perception to interact with the environments to online verify and modify the URDF. Leveraging the simulation, we propose a new model-based RL algorithm combining object-centric and robot-centric approaches to efficiently produce policies to accomplish manipulation tasks. We apply our system to perform articulated object manipulation, both in the simulation and the real world. Extensive experiments demonstrate the effectiveness of our proposed learning framework. Supplemental materials and videos are available on https://sites.google.com/view/egci.
SuctionNet-1Billion: A Large-Scale Benchmark for Suction Grasping
Mar 23, 2021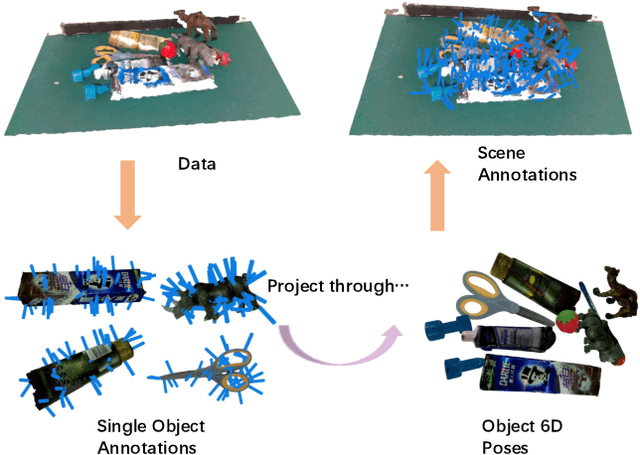
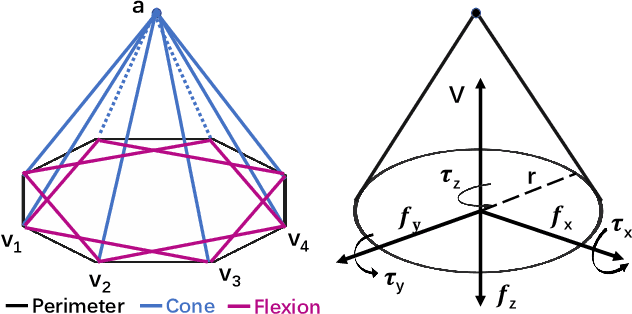
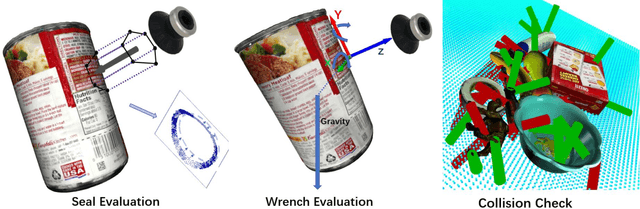
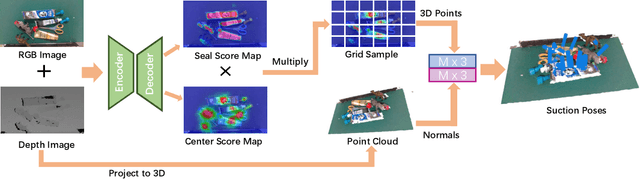
Suction is an important solution for the longstanding robotic grasping problem. Compared with other kinds of grasping, suction grasping is easier to represent and often more reliable in practice. Though preferred in many scenarios, it is not fully investigated and lacks sufficient training data and evaluation benchmarks. To address that, firstly, we propose a new physical model to analytically evaluate seal formation and wrench resistance of a suction grasping, which are two key aspects of grasp success. Secondly, a two-step methodology is adopted to generate annotations on a large-scale dataset collected in real-world cluttered scenarios. Thirdly, a standard online evaluation system is proposed to evaluate suction poses in continuous operation space, which can benchmark different algorithms fairly without the need of exhaustive labeling. Real-robot experiments are conducted to show that our annotations align well with real world. Meanwhile, we propose a method to predict numerous suction poses from an RGB-D image of a cluttered scene and demonstrate our superiority against several previous methods. Result analyses are further provided to help readers better understand the challenges in this area. Data and source code are publicly available at www.graspnet.net.
UKPGAN: Unsupervised KeyPoint GANeration
Nov 24, 2020
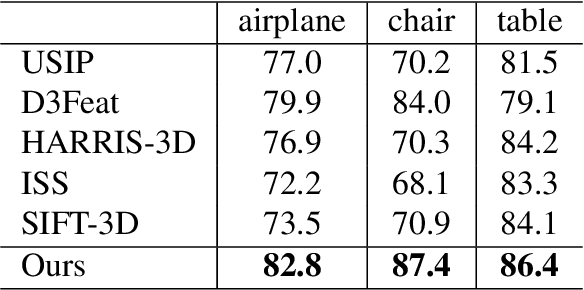


Keypoint detection is an essential component for the object registration and alignment. However, previous works mainly focused on how to register keypoints under arbitrary rigid transformations. Differently, in this work, we reckon keypoints under an information compression scheme to represent the whole object. Based on this, we propose UKPGAN, an unsupervised 3D keypoint detector where keypoints are detected so that they could reconstruct the original object shape. Two modules: GAN-based keypoint sparsity control and salient information distillation modules are proposed to locate those important keypoints. Extensive experiments show that our keypoints preserve the semantic information of objects and align well with human annotated part and keypoint labels. Furthermore, we show that UKPGAN can be applied to either rigid objects or non-rigid SMPL human bodies under arbitrary pose deformations. As a keypoint detector, our model is stable under both rigid and non-rigid transformations, with local reference frame estimation. Our code is available on https://github.com/qq456cvb/UKPGAN.