 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoFreeVLA: Collision-Free Dual-Arm Manipulation via Vision-Language-Action Model and Risk Estimation
Jan 29, 2026Vision Language Action (VLA) models enable instruction following manipulation, yet dualarm deployment remains unsafe due to under modeled selfcollisions between arms and grasped objects. We introduce CoFreeVLA, which augments an endtoend VLA with a short horizon selfcollision risk estimator that predicts collision likelihood from proprioception, visual embeddings, and planned actions. The estimator gates risky commands, recovers to safe states via risk-guided adjustments, and shapes policy refinement for safer rollouts. It is pre-trained with model-based collision labels and posttrained on real robot rollouts for calibration. On five bimanual tasks with the PiPER robot arm, CoFreeVLA reduces selfcollisions and improves success rates versus RDT and APEX.
InternVLA-A1: Unifying Understanding, Generation and Action for Robotic Manipulation
Jan 05, 2026Prevalent Vision-Language-Action (VLA) models are typically built upon Multimodal Large Language Models (MLLMs) and demonstrate exceptional proficiency in semantic understanding, but they inherently lack the capability to deduce physical world dynamics. Consequently, recent approaches have shifted toward World Models, typically formulated via video prediction; however, these methods often suffer from a lack of semantic grounding and exhibit brittleness when handling prediction errors. To synergize semantic understanding with dynamic predictive capabilities, we present InternVLA-A1. This model employs a unified Mixture-of-Transformers architecture, coordinating three experts for scene understanding, visual foresight generation, and action execution. These components interact seamlessly through a unified masked self-attention mechanism. Building upon InternVL3 and Qwen3-VL, we instantiate InternVLA-A1 at 2B and 3B parameter scales. We pre-train these models on hybrid synthetic-real datasets spanning InternData-A1 and Agibot-World, covering over 533M frames. This hybrid training strategy effectively harnesses the diversity of synthetic simulation data while minimizing the sim-to-real gap. We evaluated InternVLA-A1 across 12 real-world robotic tasks and simulation benchmark. It significantly outperforms leading models like pi0 and GR00T N1.5, achieving a 14.5\% improvement in daily tasks and a 40\%-73.3\% boost in dynamic settings, such as conveyor belt sorting.
Hybrid Consistency Policy: Decoupling Multi-Modal Diversity and Real-Time Efficiency in Robotic Manipulation
Oct 30, 2025In visuomotor policy learning, diffusion-based imitation learning has become widely adopted for its ability to capture diverse behaviors. However, approaches built on ordinary and stochastic denoising processes struggle to jointly achieve fast sampling and strong multi-modality. To address these challenges, we propose the Hybrid Consistency Policy (HCP). HCP runs a short stochastic prefix up to an adaptive switch time, and then applies a one-step consistency jump to produce the final action. To align this one-jump generation, HCP performs time-varying consistency distillation that combines a trajectory-consistency objective to keep neighboring predictions coherent and a denoising-matching objective to improve local fidelity. In both simulation and on a real robot, HCP with 25 SDE steps plus one jump approaches the 80-step DDPM teacher in accuracy and mode coverage while significantly reducing latency. These results show that multi-modality does not require slow inference, and a switch time decouples mode retention from speed. It yields a practical accuracy efficiency trade-off for robot policies.
ArtGS:3D Gaussian Splatting for Interactive Visual-Physical Modeling and Manipulation of Articulated Objects
Jul 03, 2025Articulated object manipulation remains a critical challenge in robotics due to the complex kinematic constraints and the limited physical reasoning of existing methods. In this work, we introduce ArtGS, a novel framework that extends 3D Gaussian Splatting (3DGS) by integrating visual-physical modeling for articulated object understanding and interaction. ArtGS begins with multi-view RGB-D reconstruction, followed by reasoning with a vision-language model (VLM) to extract semantic and structural information, particularly the articulated bones. Through dynamic, differentiable 3DGS-based rendering, ArtGS optimizes the parameters of the articulated bones, ensuring physically consistent motion constraints and enhancing the manipulation policy. By leveraging dynamic Gaussian splatting, cross-embodiment adaptability, and closed-loop optimization, ArtGS establishes a new framework for efficient, scalable, and generalizable articulated object modeling and manipulation. Experiments conducted in both simulation and real-world environments demonstrate that ArtGS significantly outperforms previous methods in joint estimation accuracy and manipulation success rates across a variety of articulated objects. Additional images and videos are available on the project website: https://sites.google.com/view/artgs/home
ForceVLA: Enhancing VLA Models with a Force-aware MoE for Contact-rich Manipulation
May 28, 2025Vision-Language-Action (VLA) models have advanced general-purpose robotic manipulation by leveraging pretrained visual and linguistic representations. However, they struggle with contact-rich tasks that require fine-grained control involving force, especially under visual occlusion or dynamic uncertainty. To address these limitations, we propose \textbf{ForceVLA}, a novel end-to-end manipulation framework that treats external force sensing as a first-class modality within VLA systems. ForceVLA introduces \textbf{FVLMoE}, a force-aware Mixture-of-Experts fusion module that dynamically integrates pretrained visual-language embeddings with real-time 6-axis force feedback during action decoding. This enables context-aware routing across modality-specific experts, enhancing the robot's ability to adapt to subtle contact dynamics. We also introduce \textbf{ForceVLA-Data}, a new dataset comprising synchronized vision, proprioception, and force-torque signals across five contact-rich manipulation tasks. ForceVLA improves average task success by 23.2\% over strong $\pi_0$-based baselines, achieving up to 80\% success in tasks such as plug insertion. Our approach highlights the importance of multimodal integration for dexterous manipulation and sets a new benchmark for physically intelligent robotic control. Code and data will be released at https://sites.google.com/view/forcevla2025.
REArtGS: Reconstructing and Generating Articulated Objects via 3D Gaussian Splatting with Geometric and Motion Constraints
Mar 09, 2025Articulated objects, as prevalent entities in human life, their 3D representations play crucial roles across various applications. However, achieving both high-fidelity textured surface reconstruction and dynamic generation for articulated objects remains challenging for existing methods. In this paper, we present REArtGS, a novel framework that introduces additional geometric and motion constraints to 3D Gaussian primitives, enabling high-quality textured surface reconstruction and generation for articulated objects. Specifically, given multi-view RGB images of arbitrary two states of articulated objects, we first introduce an unbiased Signed Distance Field (SDF) guidance to regularize Gaussian opacity fields, enhancing geometry constraints and improving surface reconstruction quality. Then we establish deformable fields for 3D Gaussians constrained by the kinematic structures of articulated objects, achieving unsupervised generation of surface meshes in unseen states. Extensive experiments on both synthetic and real datasets demonstrate our approach achieves high-quality textured surface reconstruction for given states, and enables high-fidelity surface generation for unseen states. Codes will be released within the next four months.
Generalizable Articulated Object Perception with Superpoints
Dec 21, 2024

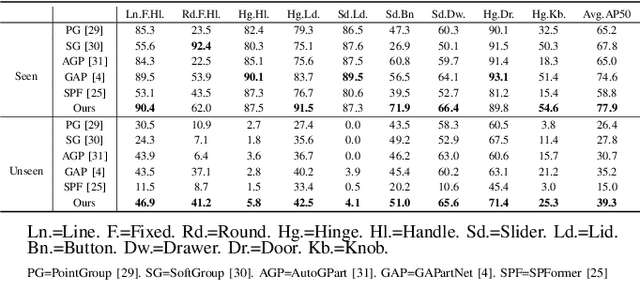
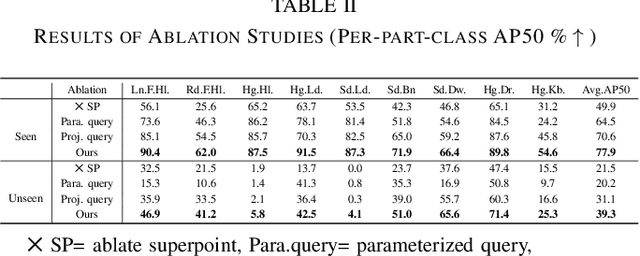
Manipulating articulated objects with robotic arms is challenging due to the complex kinematic structure, which requires precise part segmentation for efficient manipulation. In this work, we introduce a novel superpoint-based perception method designed to improve part segmentation in 3D point clouds of articulated objects. We propose a learnable, part-aware superpoint generation technique that efficiently groups points based on their geometric and semantic similarities, resulting in clearer part boundaries. Furthermore, by leveraging the segmentation capabilities of the 2D foundation model SAM, we identify the centers of pixel regions and select corresponding superpoints as candidate query points. Integrating a query-based transformer decoder further enhances our method's ability to achieve precise part segmentation. Experimental results on the GAPartNet dataset show that our method outperforms existing state-of-the-art approaches in cross-category part segmentation, achieving AP50 scores of 77.9% for seen categories (4.4% improvement) and $39.3\%$ for unseen categories (11.6% improvement), with superior results in 5 out of 9 part categories for seen objects and outperforming all previous methods across all part categories for unseen objects.
UniAff: A Unified Representation of Affordances for Tool Usage and Articulation with Vision-Language Models
Sep 30, 2024



Previous studies on robotic manipulation are based on a limited understanding of the underlying 3D motion constraints and affordances. To address these challenges, we propose a comprehensive paradigm, termed UniAff, that integrates 3D object-centric manipulation and task understanding in a unified formulation. Specifically, we constructed a dataset labeled with manipulation-related key attributes, comprising 900 articulated objects from 19 categories and 600 tools from 12 categories. Furthermore, we leverage MLLMs to infer object-centric representations for manipulation tasks, including affordance recognition and reasoning about 3D motion constraints. Comprehensive experiments in both simulation and real-world settings indicate that UniAff significantly improves the generalization of robotic manipulation for tools and articulated objects. We hope that UniAff will serve as a general baseline for unified robotic manipulation tasks in the future. Images, videos, dataset, and code are published on the project website at:https://sites.google.com/view/uni-aff/home
SKT: Integrating State-Aware Keypoint Trajectories with Vision-Language Models for Robotic Garment Manipulation
Sep 26, 2024



Automating garment manipulation poses a significant challenge for assistive robotics due to the diverse and deformable nature of garments. Traditional approaches typically require separate models for each garment type, which limits scalability and adaptability. In contrast, this paper presents a unified approach using vision-language models (VLMs) to improve keypoint prediction across various garment categories. By interpreting both visual and semantic information, our model enables robots to manage different garment states with a single model. We created a large-scale synthetic dataset using advanced simulation techniques, allowing scalable training without extensive real-world data. Experimental results indicate that the VLM-based method significantly enhances keypoint detection accuracy and task success rates, providing a more flexible and general solution for robotic garment manipulation. In addition, this research also underscores the potential of VLMs to unify various garment manipulation tasks within a single framework, paving the way for broader applications in home automation and assistive robotics for future.
Articulated Object Manipulation using Online Axis Estimation with SAM2-Based Tracking
Sep 24, 2024Articulated object manipulation requires precise object interaction, where the object's axis must be carefully considered. Previous research employed interactive perception for manipulating articulated objects, but typically, open-loop approaches often suffer from overlooking the interaction dynamics. To address this limitation, we present a closed-loop pipeline integrating interactive perception with online axis estimation from segmented 3D point clouds. Our method leverages any interactive perception technique as a foundation for interactive perception, inducing slight object movement to generate point cloud frames of the evolving dynamic scene. These point clouds are then segmented using Segment Anything Model 2 (SAM2), after which the moving part of the object is masked for accurate motion online axis estimation, guiding subsequent robotic actions. Our approach significantly enhances the precision and efficiency of manipulation tasks involving articulated objects. Experiments in simulated environments demonstrate that our method outperforms baseline approaches, especially in tasks that demand precise axis-based control. Project Page: https://hytidel.github.io/video-tracking-for-axis-estimation/.