 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosmos-Drive-Dreams: Scalable Synthetic Driving Data Generation with World Foundation Models
Jun 11, 2025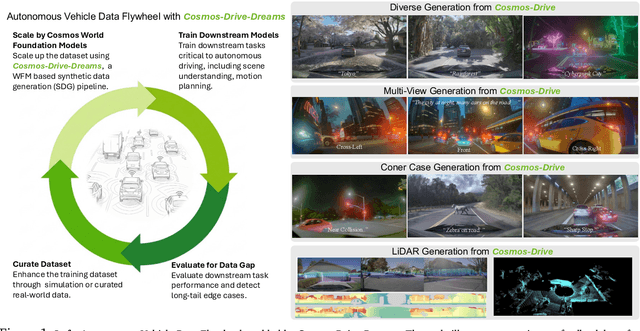
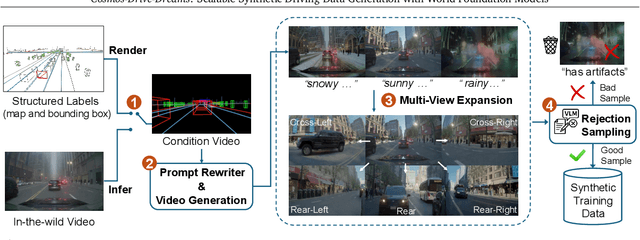
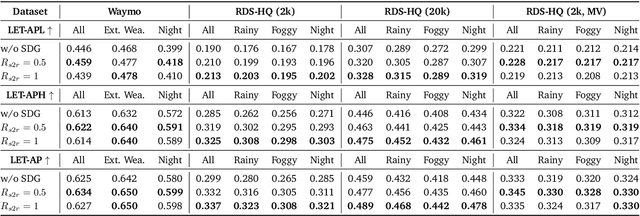
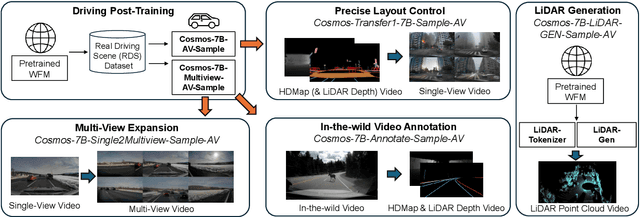
Collecting and annotating real-world data for safety-critical physical AI systems, such as Autonomous Vehicle (AV), is time-consuming and costly. It is especially challenging to capture rare edge cases, which play a critical role in training and testing of an AV system. To address this challenge, we introduce the Cosmos-Drive-Dreams - a synthetic data generation (SDG) pipeline that aims to generate challenging scenarios to facilitate downstream tasks such as perception and driving policy training. Powering this pipeline is Cosmos-Drive, a suite of models specialized from NVIDIA Cosmos world foundation model for the driving domain and are capable of controllable, high-fidelity, multi-view, and spatiotemporally consistent driving video generation. We showcase the utility of these models by applying Cosmos-Drive-Dreams to scale the quantity and diversity of driving datasets with high-fidelity and challenging scenarios. Experimentally, we demonstrate that our generated data helps in mitigating long-tail distribution problems and enhances generalization in downstream tasks such as 3D lane detection, 3D object detection and driving policy learning. We open source our pipeline toolkit, dataset and model weights through the NVIDIA's Cosmos platform. Project page: https://research.nvidia.com/labs/toronto-ai/cosmos_drive_dreams
JiSAM: Alleviate Labeling Burden and Corner Case Problems in Autonomous Driving via Minimal Real-World Data
Mar 13, 2025Deep-learning-based autonomous driving (AD) perception introduces a promising picture for safe and environment-friendly transportation. However, the over-reliance on real labeled data in LiDAR perception limits the scale of on-road attempts. 3D real world data is notoriously time-and-energy-consuming to annotate and lacks corner cases like rare traffic participants. On the contrary, in simulators like CARLA, generating labeled LiDAR point clouds with corner cases is a piece of cake. However, introducing synthetic point clouds to improve real perception is non-trivial. This stems from two challenges: 1) sample efficiency of simulation datasets 2) simulation-to-real gaps. To overcome both challenges, we propose a plug-and-play method called JiSAM , shorthand for Jittering augmentation, domain-aware backbone and memory-based Sectorized AlignMent. In extensive experiments conducted on the famous AD dataset NuScenes, we demonstrate that, with SOTA 3D object detector, JiSAM is able to utilize the simulation data and only labels on 2.5% available real data to achieve comparable performance to models trained on all real data. Additionally, JiSAM achieves more than 15 mAPs on the objects not labeled in the real training set. We will release models and codes.
Temporal Overlapping Prediction: A Self-supervised Pre-training Method for LiDAR Moving Object Segmentation
Mar 10, 2025



Moving object segmentation (MOS) on LiDAR point clouds is crucial for autonomous systems like self-driving vehicles. Previous supervised approaches rely heavily on costly manual annotations, while LiDAR sequences naturally capture temporal motion cues that can be leveraged for self-supervised learning. In this paper, we propose \textbf{T}emporal \textbf{O}verlapping \textbf{P}rediction (\textbf{TOP}), a self-supervised pre-training method that alleviate the labeling burden for MOS. \textbf{TOP} explores the temporal overlapping points that commonly observed by current and adjacent scans, and learns spatiotemporal representations by predicting the occupancy states of temporal overlapping points. Moreover, we utilize current occupancy reconstruction as an auxiliary pre-training objective, which enhances the current structural awareness of the model. We conduct extensive experiments and observe that the conventional metric Intersection-over-Union (IoU) shows strong bias to objects with more scanned points, which might neglect small or distant objects. To compensate for this bias, we introduce an additional metric called $\text{mIoU}_{\text{obj}}$ to evaluate object-level performance. Experiments on nuScenes and SemanticKITTI show that \textbf{TOP} outperforms both supervised training-from-scratch baseline and other self-supervised pre-training baselines by up to 28.77\% relative improvement, demonstrating strong transferability across LiDAR setups and generalization to other tasks. Code and pre-trained models will be publicly available upon publication.
TREND: Unsupervised 3D Representation Learning via Temporal Forecasting for LiDAR Perception
Dec 04, 2024



Labeling LiDAR point clouds is notoriously time-and-energy-consuming, which spurs recent unsupervised 3D representation learning methods to alleviate the labeling burden in LiDAR perception via pretrained weights. Almost all existing work focus on a single frame of LiDAR point cloud and neglect the temporal LiDAR sequence, which naturally accounts for object motion (and their semantics). Instead, we propose TREND, namely Temporal REndering with Neural fielD, to learn 3D representation via forecasting the future observation in an unsupervised manner. Unlike existing work that follows conventional contrastive learning or masked auto encoding paradigms, TREND integrates forecasting for 3D pre-training through a Recurrent Embedding scheme to generate 3D embedding across time and a Temporal Neural Field to represent the 3D scene, through which we compute the loss using differentiable rendering. To our best knowledge, TREND is the first work on temporal forecasting for unsupervised 3D representation learning. We evaluate TREND on downstream 3D object detection tasks on popular datasets, including NuScenes, Once and Waymo. Experiment results show that TREND brings up to 90% more improvement as compared to previous SOTA unsupervised 3D pre-training methods and generally improve different downstream models across datasets, demonstrating that indeed temporal forecasting brings improvement for LiDAR perception. Codes and models will be released.
CLAP: Unsupervised 3D Representation Learning for Fusion 3D Perception via Curvature Sampling and Prototype Learning
Dec 04, 2024



Unsupervised 3D representation learning via masked-and-reconstruction with differentiable rendering is promising to reduce the labeling burden for fusion 3D perception. However, previous literature conduct pre-training for different modalities separately because of the hight GPU memory consumption. Consequently, the interaction between the two modalities (images and point clouds) is neglected during pre-training. In this paper, we explore joint unsupervised pre-training for fusion 3D perception via differentiable rendering and propose CLAP, short for Curvature sampLing and swApping Prototype assignment prediction. The contributions are three-fold. 1) To overcome the GPU memory consumption problem, we propose Curvature Sampling to sample the more informative points/pixels for pre-training. 2) We propose to use learnable prototypes to represent parts of the scenes in a common feature space and bring the idea of swapping prototype assignment prediction to learn the interaction between the two modalities. 3) To further optimize learnable prototypes, we propose an Expectation-Maximization training scheme to maximize the similarity between embeddings and prototypes, followed by a Gram Matrix Regularization Loss to avoid collapse. Experiment results on NuScenes show that CLAP achieves 300% more performance gain as compared to previous SOTA 3D pre-training method via differentiable rendering. Codes and models will be released.
MMT-Bench: A Comprehensive Multimodal Benchmark for Evaluating Large Vision-Language Models Towards Multitask AGI
Apr 24, 2024



Large Vision-Language Models (LVLMs) show significant strides in general-purpose multimodal applications such as visual dialogue and embodied navigation. However, existing multimodal evaluation benchmarks cover a limited number of multimodal tasks testing rudimentary capabilities, falling short in tracking LVLM development. In this study, we present MMT-Bench, a comprehensive benchmark designed to assess LVLMs across massive multimodal tasks requiring expert knowledge and deliberate visual recognition, localization, reasoning, and planning. MMT-Bench comprises $31,325$ meticulously curated multi-choice visual questions from various multimodal scenarios such as vehicle driving and embodied navigation, covering $32$ core meta-tasks and $162$ subtasks in multimodal understanding. Due to its extensive task coverage, MMT-Bench enables the evaluation of LVLMs using a task map, facilitating the discovery of in- and out-of-domain tasks. Evaluation results involving $30$ LVLMs such as the proprietary GPT-4V, GeminiProVision, and open-sourced InternVL-Chat, underscore the significant challenges posed by MMT-Bench. We anticipate that MMT-Bench will inspire the community to develop next-generation multimodal foundation models aimed at achieving general-purpose multimodal intelligence.
Towards Implicit Prompt For Text-To-Image Models
Mar 08, 2024



Recent text-to-image (T2I) models have had great success, and many benchmarks have been proposed to evaluate their performance and safety. However, they only consider explicit prompts while neglecting implicit prompts (hint at a target without explicitly mentioning it). These prompts may get rid of safety constraints and pose potential threats to the applications of these models. This position paper highlights the current state of T2I models toward implicit prompts. We present a benchmark named ImplicitBench and conduct an investigation on the performance and impacts of implicit prompts with popular T2I models. Specifically, we design and collect more than 2,000 implicit prompts of three aspects: General Symbols, Celebrity Privacy, and Not-Safe-For-Work (NSFW) Issues, and evaluate six well-known T2I models' capabilities under these implicit prompts. Experiment results show that (1) T2I models are able to accurately create various target symbols indicated by implicit prompts; (2) Implicit prompts bring potential risks of privacy leakage for T2I models. (3) Constraints of NSFW in most of the evaluated T2I models can be bypassed with implicit prompts. We call for increased attention to the potential and risks of implicit prompts in the T2I community and further investigation into the capabilities and impacts of implicit prompts, advocating for a balanced approach that harnesses their benefits while mitigating their risks.
RoboCodeX: Multimodal Code Generation for Robotic Behavior Synthesis
Feb 25, 2024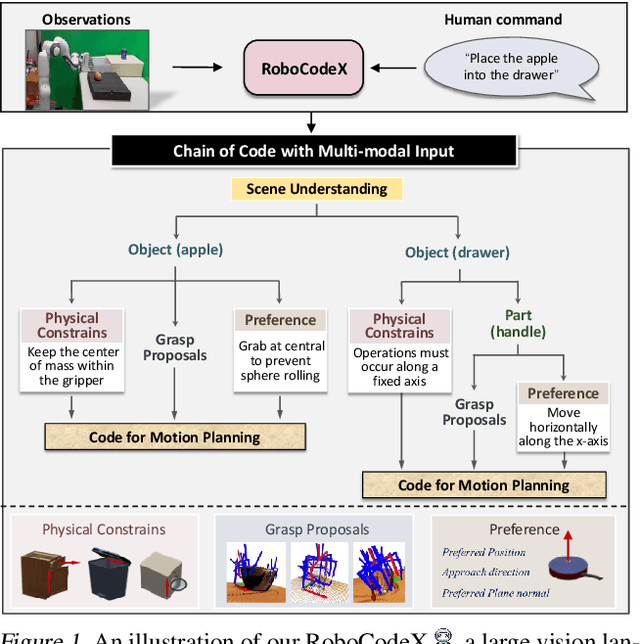
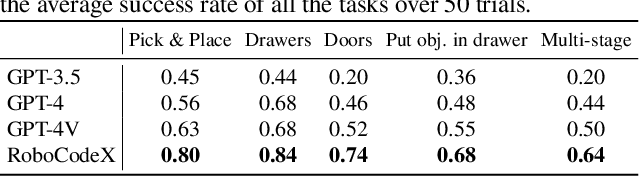
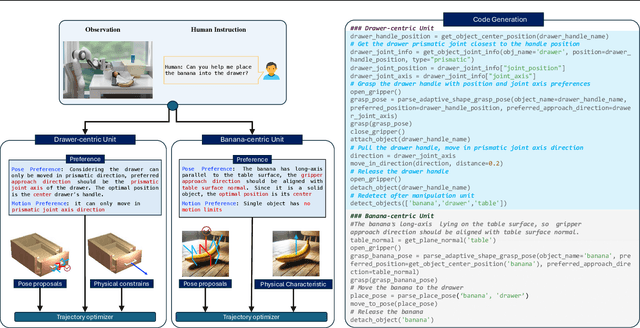

Robotic behavior synthesis, the problem of understanding multimodal inputs and generating precise physical control for robots, is an important part of Embodied AI. Despite successes in applying multimodal large language models for high-level understanding, it remains challenging to translate these conceptual understandings into detailed robotic actions while achieving generalization across various scenarios. In this paper, we propose a tree-structured multimodal code generation framework for generalized robotic behavior synthesis, termed RoboCodeX. RoboCodeX decomposes high-level human instructions into multiple object-centric manipulation units consisting of physical preferences such as affordance and safety constraints, and applies code generation to introduce generalization ability across various robotics platforms. To further enhance the capability to map conceptual and perceptual understanding into control commands, a specialized multimodal reasoning dataset is collected for pre-training and an iterative self-updating methodology is introduced for supervised fine-tuning. Extensive experiments demonstrate that RoboCodeX achieves state-of-the-art performance in both simulators and real robots on four different kinds of manipulation tasks and one navigation task.
CurriculumLoc: Enhancing Cross-Domain Geolocalization through Multi-Stage Refinement
Nov 20, 2023



Visual geolocalization is a cost-effective and scalable task that involves matching one or more query images, taken at some unknown location, to a set of geo-tagged reference images. Existing methods, devoted to semantic features representation, evolving towards robustness to a wide variety between query and reference, including illumination and viewpoint changes, as well as scale and seasonal variations. However, practical visual geolocalization approaches need to be robust in appearance changing and extreme viewpoint variation conditions, while providing accurate global location estimates. Therefore, inspired by curriculum design, human learn general knowledge first and then delve into professional expertise. We first recognize semantic scene and then measure geometric structure. Our approach, termed CurriculumLoc, involves a delicate design of multi-stage refinement pipeline and a novel keypoint detection and description with global semantic awareness and local geometric verification. We rerank candidates and solve a particular cross-domain perspective-n-point (PnP) problem based on these keypoints and corresponding descriptors, position refinement occurs incrementally. The extensive experimental results on our collected dataset, TerraTrack and a benchmark dataset, ALTO, demonstrate that our approach results in the aforementioned desirable characteristics of a practical visual geolocalization solution. Additionally, we achieve new high recall@1 scores of 62.6% and 94.5% on ALTO, with two different distances metrics, respectively. Dataset, code and trained models are publicly available on https://github.com/npupilab/CurriculumLoc.
SPOT: Scalable 3D Pre-training via Occupancy Prediction for Autonomous Driving
Sep 25, 2023



Annotating 3D LiDAR point clouds for perception tasks including 3D object detection and LiDAR semantic segmentation is notoriously time-and-energy-consuming. To alleviate the burden from labeling, it is promising to perform large-scale pre-training and fine-tune the pre-trained backbone on different downstream datasets as well as tasks. In this paper, we propose SPOT, namely Scalable Pre-training via Occupancy prediction for learning Transferable 3D representations, and demonstrate its effectiveness on various public datasets with different downstream tasks under the label-efficiency setting. Our contributions are threefold: (1) Occupancy prediction is shown to be promising for learning general representations, which is demonstrated by extensive experiments on plenty of datasets and tasks. (2) SPOT uses beam re-sampling technique for point cloud augmentation and applies class-balancing strategies to overcome the domain gap brought by various LiDAR sensors and annotation strategies in different datasets. (3) Scalable pre-training is observed, that is, the downstream performance across all the experiments gets better with more pre-training data. We believe that our findings can facilitate understanding of LiDAR point clouds and pave the way for future exploration in LiDAR pre-training. Codes and models will be released.