 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWBench: A Comprehensive Multi-turn Benchmark for Interactive Video World Model Evaluation
May 25, 2026Interactive world models are advancing rapidly, yet existing benchmarks cover only part of the required competencies, leaving no unified standard for systematic evaluation. To fill this gap, we introduce WBench, a comprehensive multi-turn benchmark for interactive world model evaluation along five dimensions, namely video quality, setting adherence, interaction adherence, consistency, and physics compliance. WBench contains 289 test cases and 1,058 interaction turns, where each case specifies a world setting and a multi-turn interaction sequence, covering diverse scenes, styles, subjects, and both first- and third-person perspectives, together with four interaction types, including navigation, subject action, event editing, and perspective switching. For navigation, WBench unifies text, 6-DoF pose, and discrete-action control, enabling evaluation of models with different native input interfaces. Evaluation uses 22 automatic sub-metrics that combine specialist vision models with large multimodal models, and all metrics are validated against human judgments. Across 20 state-of-the-art models, we find that no single model performs strongly across all dimensions. We provide detailed diagnostic insights into the characteristic strengths, weaknesses, and open challenges of each model. Code and data are available at https://github.com/meituan-longcat/WBench.
PackForcing: Short Video Training Suffices for Long Video Sampling and Long Context Inference
Mar 26, 2026Autoregressive video diffusion models have demonstrated remarkable progress, yet they remain bottlenecked by intractable linear KV-cache growth, temporal repetition, and compounding errors during long-video generation. To address these challenges, we present PackForcing, a unified framework that efficiently manages the generation history through a novel three-partition KV-cache strategy. Specifically, we categorize the historical context into three distinct types: (1) Sink tokens, which preserve early anchor frames at full resolution to maintain global semantics; (2) Mid tokens, which achieve a massive spatiotemporal compression (32x token reduction) via a dual-branch network fusing progressive 3D convolutions with low-resolution VAE re-encoding; and (3) Recent tokens, kept at full resolution to ensure local temporal coherence. To strictly bound the memory footprint without sacrificing quality, we introduce a dynamic top-$k$ context selection mechanism for the mid tokens, coupled with a continuous Temporal RoPE Adjustment that seamlessly re-aligns position gaps caused by dropped tokens with negligible overhead. Empowered by this principled hierarchical context compression, PackForcing can generate coherent 2-minute, 832x480 videos at 16 FPS on a single H200 GPU. It achieves a bounded KV cache of just 4 GB and enables a remarkable 24x temporal extrapolation (5s to 120s), operating effectively either zero-shot or trained on merely 5-second clips. Extensive results on VBench demonstrate state-of-the-art temporal consistency (26.07) and dynamic degree (56.25), proving that short-video supervision is sufficient for high-quality, long-video synthesis. https://github.com/ShandaAI/PackForcing
Yume-1.5: A Text-Controlled Interactive World Generation Model
Dec 26, 2025Recent approaches have demonstrated the promise of using diffusion models to generate interactive and explorable worlds. However, most of these methods face critical challenges such as excessively large parameter sizes, reliance on lengthy inference steps, and rapidly growing historical context, which severely limit real-time performance and lack text-controlled generation capabilities. To address these challenges, we propose \method, a novel framework designed to generate realistic, interactive, and continuous worlds from a single image or text prompt. \method achieves this through a carefully designed framework that supports keyboard-based exploration of the generated worlds. The framework comprises three core components: (1) a long-video generation framework integrating unified context compression with linear attention; (2) a real-time streaming acceleration strategy powered by bidirectional attention distillation and an enhanced text embedding scheme; (3) a text-controlled method for generating world events. We have provided the codebase in the supplementary material.
MeViS: A Multi-Modal Dataset for Referring Motion Expression Video Segmentation
Dec 11, 2025



This paper proposes a large-scale multi-modal dataset for referring motion expression video segmentation, focusing on segmenting and tracking target objects in videos based on language description of objects' motions. Existing referring video segmentation datasets often focus on salient objects and use language expressions rich in static attributes, potentially allowing the target object to be identified in a single frame. Such datasets underemphasize the role of motion in both videos and languages. To explore the feasibility of using motion expressions and motion reasoning clues for pixel-level video understanding, we introduce MeViS, a dataset containing 33,072 human-annotated motion expressions in both text and audio, covering 8,171 objects in 2,006 videos of complex scenarios. We benchmark 15 existing methods across 4 tasks supported by MeViS, including 6 referring video object segmentation (RVOS) methods, 3 audio-guided video object segmentation (AVOS) methods, 2 referring multi-object tracking (RMOT) methods, and 4 video captioning methods for the newly introduced referring motion expression generation (RMEG) task. The results demonstrate weaknesses and limitations of existing methods in addressing motion expression-guided video understanding. We further analyze the challenges and propose an approach LMPM++ for RVOS/AVOS/RMOT that achieves new state-of-the-art results. Our dataset provides a platform that facilitates the development of motion expression-guided video understanding algorithms in complex video scenes. The proposed MeViS dataset and the method's source code are publicly available at https://henghuiding.com/MeViS/
* IEEE TPAMI, Project Page: https://henghuiding.com/MeViS/
Segment Anything Across Shots: A Method and Benchmark
Nov 17, 2025This work focuses on multi-shot semi-supervised video object segmentation (MVOS), which aims at segmenting the target object indicated by an initial mask throughout a video with multiple shots. The existing VOS methods mainly focus on single-shot videos and struggle with shot discontinuities, thereby limiting their real-world applicability. We propose a transition mimicking data augmentation strategy (TMA) which enables cross-shot generalization with single-shot data to alleviate the severe annotated multi-shot data sparsity, and the Segment Anything Across Shots (SAAS) model, which can detect and comprehend shot transitions effectively. To support evaluation and future study in MVOS, we introduce Cut-VOS, a new MVOS benchmark with dense mask annotations, diverse object categories, and high-frequency transitions. Extensive experiments on YouMVOS and Cut-VOS demonstrate that the proposed SAAS achieves state-of-the-art performance by effectively mimicking, understanding, and segmenting across complex transitions. The code and datasets are released at https://henghuiding.com/SAAS/.
MOSEv2: A More Challenging Dataset for Video Object Segmentation in Complex Scenes
Aug 07, 2025Video object segmentation (VOS) aims to segment specified target objects throughout a video. Although state-of-the-art methods have achieved impressive performance (e.g., 90+% J&F) on existing benchmarks such as DAVIS and YouTube-VOS, these datasets primarily contain salient, dominant, and isolated objects, limiting their generalization to real-world scenarios. To advance VOS toward more realistic environments, coMplex video Object SEgmentation (MOSEv1) was introduced to facilitate VOS research in complex scenes. Building on the strengths and limitations of MOSEv1, we present MOSEv2, a significantly more challenging dataset designed to further advance VOS methods under real-world conditions. MOSEv2 consists of 5,024 videos and over 701,976 high-quality masks for 10,074 objects across 200 categories. Compared to its predecessor, MOSEv2 introduces significantly greater scene complexity, including more frequent object disappearance and reappearance, severe occlusions and crowding, smaller objects, as well as a range of new challenges such as adverse weather (e.g., rain, snow, fog), low-light scenes (e.g., nighttime, underwater), multi-shot sequences, camouflaged objects, non-physical targets (e.g., shadows, reflections), scenarios requiring external knowledge, etc. We benchmark 20 representative VOS methods under 5 different settings and observe consistent performance drops. For example, SAM2 drops from 76.4% on MOSEv1 to only 50.9% on MOSEv2. We further evaluate 9 video object tracking methods and find similar declines, demonstrating that MOSEv2 presents challenges across tasks. These results highlight that despite high accuracy on existing datasets, current VOS methods still struggle under real-world complexities. MOSEv2 is publicly available at https://MOSE.video.
Towards Omnimodal Expressions and Reasoning in Referring Audio-Visual Segmentation
Jul 30, 2025Referring audio-visual segmentation (RAVS) has recently seen significant advancements, yet challenges remain in integrating multimodal information and deeply understanding and reasoning about audiovisual content. To extend the boundaries of RAVS and facilitate future research in this field, we propose Omnimodal Referring Audio-Visual Segmentation (OmniAVS), a new dataset containing 2,098 videos and 59,458 multimodal referring expressions. OmniAVS stands out with three key innovations: (1) 8 types of multimodal expressions that flexibly combine text, speech, sound, and visual cues; (2) an emphasis on understanding audio content beyond just detecting their presence; and (3) the inclusion of complex reasoning and world knowledge in expressions. Furthermore, we introduce Omnimodal Instructed Segmentation Assistant (OISA), to address the challenges of multimodal reasoning and fine-grained understanding of audiovisual content in OmniAVS. OISA uses MLLM to comprehend complex cues and perform reasoning-based segmentation. Extensive experiments show that OISA outperforms existing methods on OmniAVS and achieves competitive results on other related tasks.
MOVE: Motion-Guided Few-Shot Video Object Segmentation
Jul 29, 2025This work addresses motion-guided few-shot video object segmentation (FSVOS), which aims to segment dynamic objects in videos based on a few annotated examples with the same motion patterns. Existing FSVOS datasets and methods typically focus on object categories, which are static attributes that ignore the rich temporal dynamics in videos, limiting their application in scenarios requiring motion understanding. To fill this gap, we introduce MOVE, a large-scale dataset specifically designed for motion-guided FSVOS. Based on MOVE, we comprehensively evaluate 6 state-of-the-art methods from 3 different related tasks across 2 experimental settings. Our results reveal that current methods struggle to address motion-guided FSVOS, prompting us to analyze the associated challenges and propose a baseline method, Decoupled Motion Appearance Network (DMA). Experiments demonstrate that our approach achieves superior performance in few shot motion understanding, establishing a solid foundation for future research in this direction.
MMT-Bench: A Comprehensive Multimodal Benchmark for Evaluating Large Vision-Language Models Towards Multitask AGI
Apr 24, 2024



Large Vision-Language Models (LVLMs) show significant strides in general-purpose multimodal applications such as visual dialogue and embodied navigation. However, existing multimodal evaluation benchmarks cover a limited number of multimodal tasks testing rudimentary capabilities, falling short in tracking LVLM development. In this study, we present MMT-Bench, a comprehensive benchmark designed to assess LVLMs across massive multimodal tasks requiring expert knowledge and deliberate visual recognition, localization, reasoning, and planning. MMT-Bench comprises $31,325$ meticulously curated multi-choice visual questions from various multimodal scenarios such as vehicle driving and embodied navigation, covering $32$ core meta-tasks and $162$ subtasks in multimodal understanding. Due to its extensive task coverage, MMT-Bench enables the evaluation of LVLMs using a task map, facilitating the discovery of in- and out-of-domain tasks. Evaluation results involving $30$ LVLMs such as the proprietary GPT-4V, GeminiProVision, and open-sourced InternVL-Chat, underscore the significant challenges posed by MMT-Bench. We anticipate that MMT-Bench will inspire the community to develop next-generation multimodal foundation models aimed at achieving general-purpose multimodal intelligence.
CTVIS: Consistent Training for Online Video Instance Segmentation
Jul 24, 2023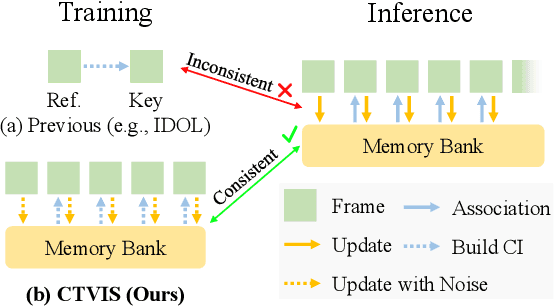
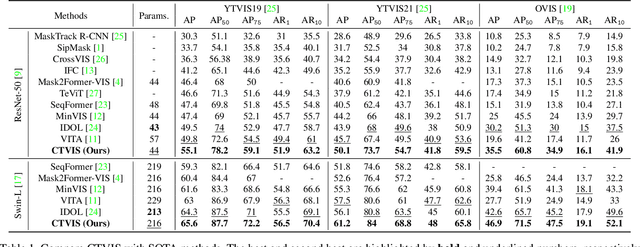
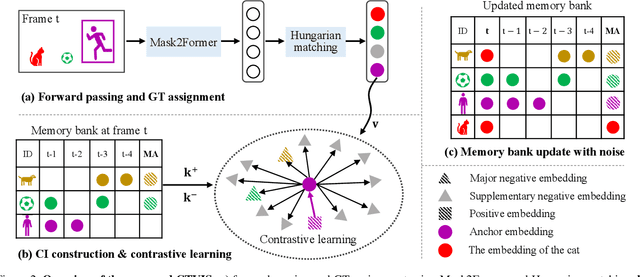
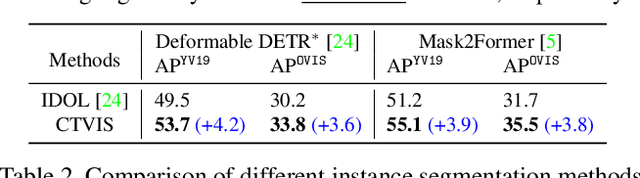
The discrimination of instance embeddings plays a vital role in associating instances across time for online video instance segmentation (VIS). Instance embedding learning is directly supervised by the contrastive loss computed upon the contrastive items (CIs), which are sets of anchor/positive/negative embeddings. Recent online VIS methods leverage CIs sourced from one reference frame only, which we argue is insufficient for learning highly discriminative embeddings. Intuitively, a possible strategy to enhance CIs is replicating the inference phase during training. To this end, we propose a simple yet effective training strategy, called Consistent Training for Online VIS (CTVIS), which devotes to aligning the training and inference pipelines in terms of building CIs. Specifically, CTVIS constructs CIs by referring inference the momentum-averaged embedding and the memory bank storage mechanisms, and adding noise to the relevant embeddings. Such an extension allows a reliable comparison between embeddings of current instances and the stable representations of historical instances, thereby conferring an advantage in modeling VIS challenges such as occlusion, re-identification, and deformation. Empirically, CTVIS outstrips the SOTA VIS models by up to +5.0 points on three VIS benchmarks, including YTVIS19 (55.1% AP), YTVIS21 (50.1% AP) and OVIS (35.5% AP). Furthermore, we find that pseudo-videos transformed from images can train robust models surpassing fully-supervised ones.