 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-to-Human Interaction Detection
Jul 02, 2023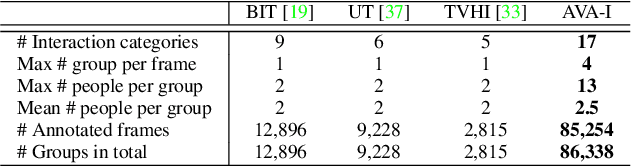
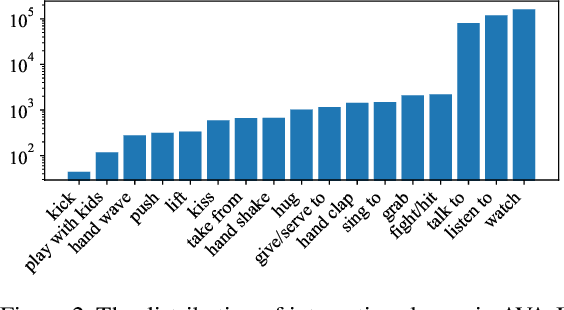


A comprehensive understanding of interested human-to-human interactions in video streams, such as queuing, handshaking, fighting and chasing, is of immense importance to the surveillance of public security in regions like campuses, squares and parks. Different from conventional human interaction recognition, which uses choreographed videos as inputs, neglects concurrent interactive groups, and performs detection and recognition in separate stages, we introduce a new task named human-to-human interaction detection (HID). HID devotes to detecting subjects, recognizing person-wise actions, and grouping people according to their interactive relations, in one model. First, based on the popular AVA dataset created for action detection, we establish a new HID benchmark, termed AVA-Interaction (AVA-I), by adding annotations on interactive relations in a frame-by-frame manner. AVA-I consists of 85,254 frames and 86,338 interactive groups, and each image includes up to 4 concurrent interactive groups. Second, we present a novel baseline approach SaMFormer for HID, containing a visual feature extractor, a split stage which leverages a Transformer-based model to decode action instances and interactive groups, and a merging stage which reconstructs the relationship between instances and groups. All SaMFormer components are jointly trained in an end-to-end manner. Extensive experiments on AVA-I validate the superiority of SaMFormer over representative methods. The dataset and code will be made public to encourage more follow-up studies.
LAGNet: Logic-Aware Graph Network for Human Interaction Understanding
Nov 26, 2020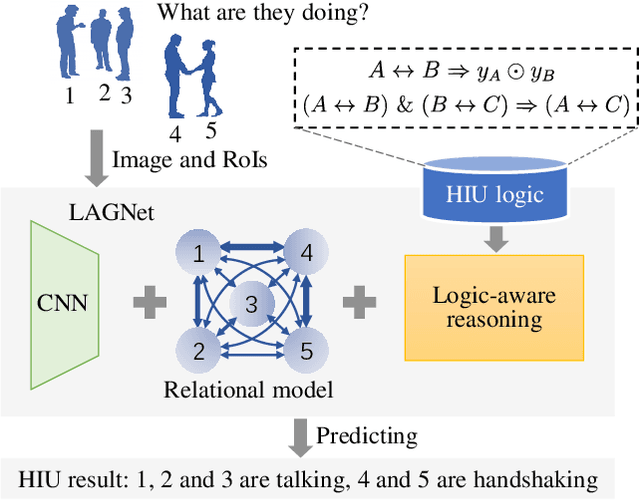
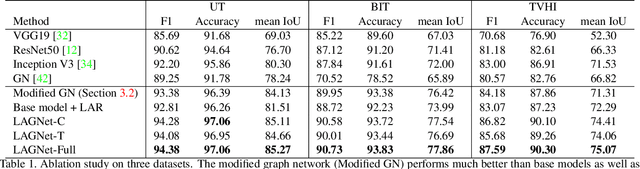
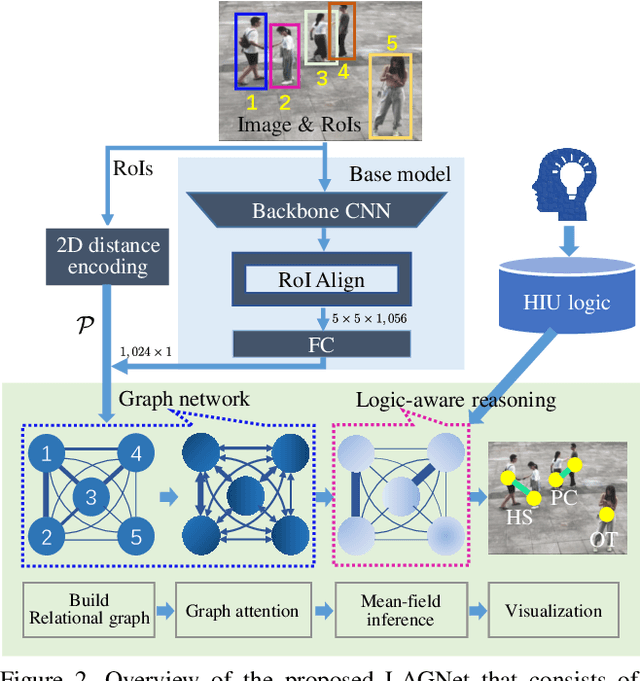

Compared with the progress made on human activity classification, much less success has been achieved on human interaction understanding (HIU). Apart from the latter task is much more challenging, the main cause is that recent approaches learn human interactive relations via shallow graphical representations, which is inadequate to model complicated human interactions. In this paper, we propose a deep logic-aware graph network, which combines the representative ability of graph attention and the rigorousness of logical reasoning to facilitate human interaction understanding. Our network consists of three components, a backbone CNN to extract image features, a graph network to learn interactive relations among participants, and a logic-aware reasoning module. Our key observation is that the first-order logic for HIU can be embedded into higher-order energy functions, minimizing which delivers logic-aware predictions. An efficient mean-field inference algorithm is proposed, such that all modules of our network could be trained jointly in an end-to-end way. Experimental results show that our approach achieves leading performance on three existing benchmarks and a new challenging dataset crafted by ourselves. Code is available at: https://git.io/LAGNet.