 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistill Any Depth: Distillation Creates a Stronger Monocular Depth Estimator
Feb 26, 2025Monocular depth estimation (MDE) aims to predict scene depth from a single RGB image and plays a crucial role in 3D scene understanding. Recent advances in zero-shot MDE leverage normalized depth representations and distillation-based learning to improve generalization across diverse scenes. However, current depth normalization methods for distillation, relying on global normalization, can amplify noisy pseudo-labels, reducing distillation effectiveness. In this paper, we systematically analyze the impact of different depth normalization strategies on pseudo-label distillation. Based on our findings, we propose Cross-Context Distillation, which integrates global and local depth cues to enhance pseudo-label quality. Additionally, we introduce a multi-teacher distillation framework that leverages complementary strengths of different depth estimation models, leading to more robust and accurate depth predictions. Extensive experiments on benchmark datasets demonstrate that our approach significantly outperforms state-of-the-art methods, both quantitatively and qualitatively.
DiffCalib: Reformulating Monocular Camera Calibration as Diffusion-Based Dense Incident Map Generation
May 24, 2024Monocular camera calibration is a key precondition for numerous 3D vision applications. Despite considerable advancements, existing methods often hinge on specific assumptions and struggle to generalize across varied real-world scenarios, and the performance is limited by insufficient training data. Recently, diffusion models trained on expansive datasets have been confirmed to maintain the capability to generate diverse, high-quality images. This success suggests a strong potential of the models to effectively understand varied visual information. In this work, we leverage the comprehensive visual knowledge embedded in pre-trained diffusion models to enable more robust and accurate monocular camera intrinsic estimation. Specifically, we reformulate the problem of estimating the four degrees of freedom (4-DoF) of camera intrinsic parameters as a dense incident map generation task. The map details the angle of incidence for each pixel in the RGB image, and its format aligns well with the paradigm of diffusion models. The camera intrinsic then can be derived from the incident map with a simple non-learning RANSAC algorithm during inference. Moreover, to further enhance the performance, we jointly estimate a depth map to provide extra geometric information for the incident map estimation. Extensive experiments on multiple testing datasets demonstrate that our model achieves state-of-the-art performance, gaining up to a 40% reduction in prediction errors. Besides, the experiments also show that the precise camera intrinsic and depth maps estimated by our pipeline can greatly benefit practical applications such as 3D reconstruction from a single in-the-wild image.
PointAttN: You Only Need Attention for Point Cloud Completion
Mar 16, 2022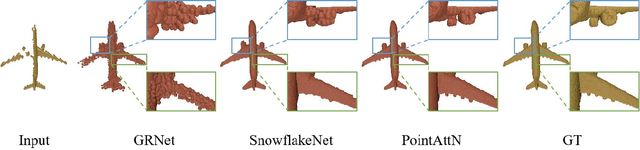
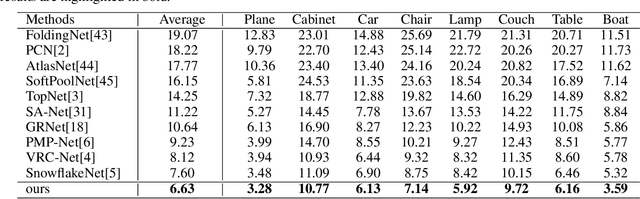
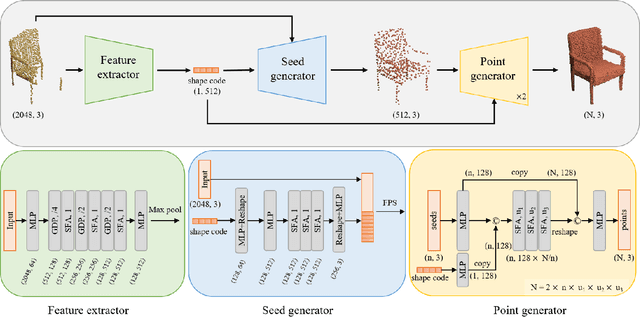
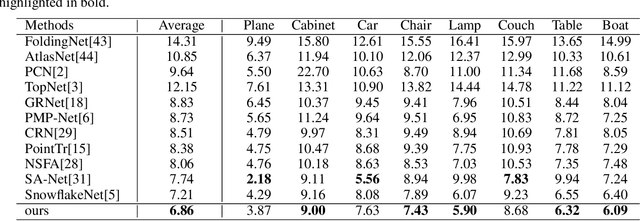
Point cloud completion referring to completing 3D shapes from partial 3D point clouds is a fundamental problem for 3D point cloud analysis tasks. Benefiting from the development of deep neural networks, researches on point cloud completion have made great progress in recent years. However, the explicit local region partition like kNNs involved in existing methods makes them sensitive to the density distribution of point clouds. Moreover, it serves limited receptive fields that prevent capturing features from long-range context information. To solve the problems, we leverage the cross-attention and self-attention mechanisms to design novel neural network for processing point cloud in a per-point manner to eliminate kNNs. Two essential blocks Geometric Details Perception (GDP) and Self-Feature Augment (SFA) are proposed to establish the short-range and long-range structural relationships directly among points in a simple yet effective way via attention mechanism. Then based on GDP and SFA, we construct a new framework with popular encoder-decoder architecture for point cloud completion. The proposed framework, namely PointAttN, is simple, neat and effective, which can precisely capture the structural information of 3D shapes and predict complete point clouds with highly detailed geometries. Experimental results demonstrate that our PointAttN outperforms state-of-the-art methods by a large margin on popular benchmarks like Completion3D and PCN. Code is available at: https://github.com/ohhhyeahhh/PointAttN
Collaborative Visual Inertial SLAM for Multiple Smart Phones
Jun 23, 2021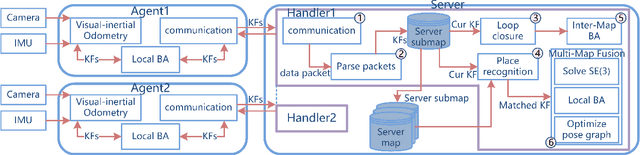
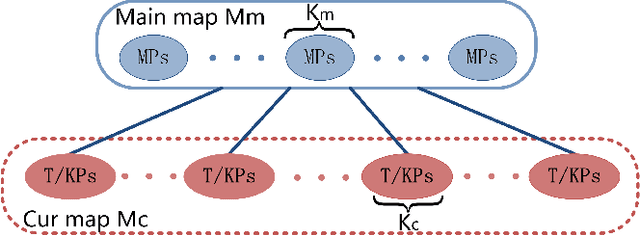
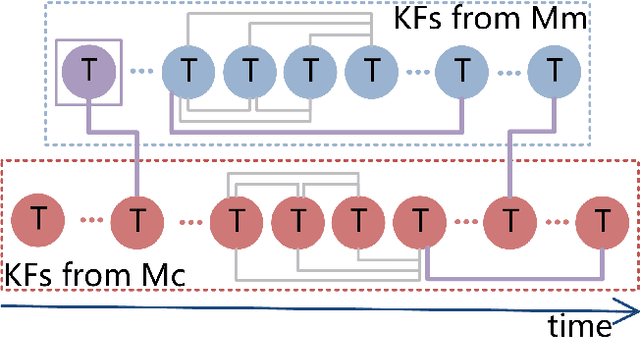
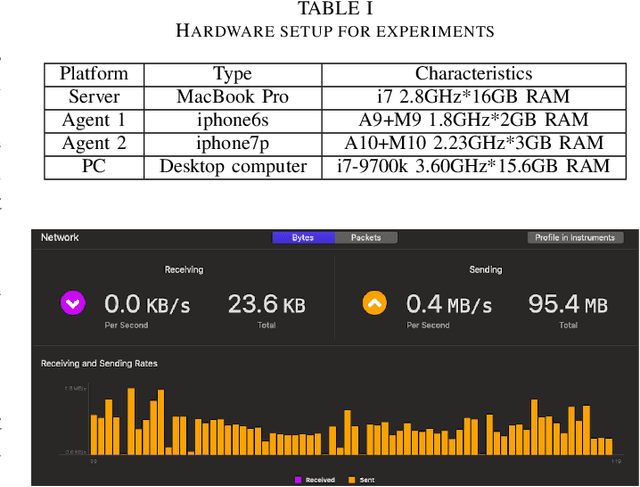
The efficiency and accuracy of mapping are crucial in a large scene and long-term AR applications. Multi-agent cooperative SLAM is the precondition of multi-user AR interaction. The cooperation of multiple smart phones has the potential to improve efficiency and robustness of task completion and can complete tasks that a single agent cannot do. However, it depends on robust communication, efficient location detection, robust mapping, and efficient information sharing among agents. We propose a multi-intelligence collaborative monocular visual-inertial SLAM deployed on multiple ios mobile devices with a centralized architecture. Each agent can independently explore the environment, run a visual-inertial odometry module online, and then send all the measurement information to a central server with higher computing resources. The server manages all the information received, detects overlapping areas, merges and optimizes the map, and shares information with the agents when needed. We have verified the performance of the system in public datasets and real environments. The accuracy of mapping and fusion of the proposed system is comparable to VINS-Mono which requires higher computing resources.
LAGNet: Logic-Aware Graph Network for Human Interaction Understanding
Nov 26, 2020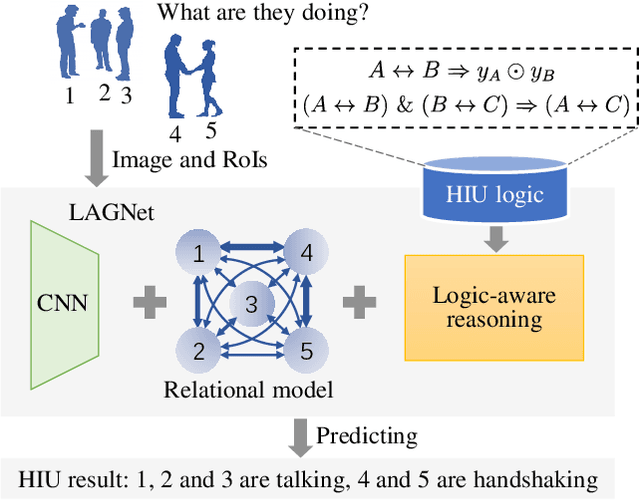
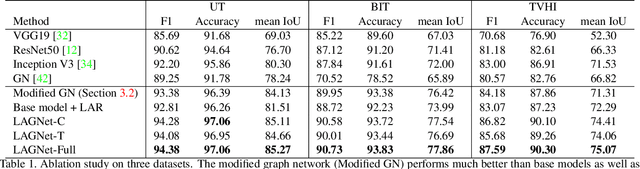
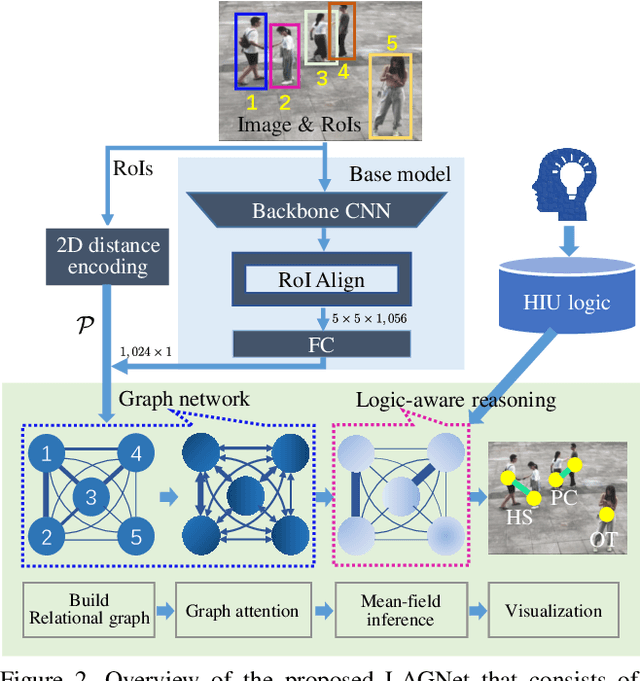

Compared with the progress made on human activity classification, much less success has been achieved on human interaction understanding (HIU). Apart from the latter task is much more challenging, the main cause is that recent approaches learn human interactive relations via shallow graphical representations, which is inadequate to model complicated human interactions. In this paper, we propose a deep logic-aware graph network, which combines the representative ability of graph attention and the rigorousness of logical reasoning to facilitate human interaction understanding. Our network consists of three components, a backbone CNN to extract image features, a graph network to learn interactive relations among participants, and a logic-aware reasoning module. Our key observation is that the first-order logic for HIU can be embedded into higher-order energy functions, minimizing which delivers logic-aware predictions. An efficient mean-field inference algorithm is proposed, such that all modules of our network could be trained jointly in an end-to-end way. Experimental results show that our approach achieves leading performance on three existing benchmarks and a new challenging dataset crafted by ourselves. Code is available at: https://git.io/LAGNet.
Graph Attention Tracking
Nov 23, 2020



Siamese network based trackers formulate the visual tracking task as a similarity matching problem. Almost all popular Siamese trackers realize the similarity learning via convolutional feature cross-correlation between a target branch and a search branch. However, since the size of target feature region needs to be pre-fixed, these cross-correlation base methods suffer from either reserving much adverse background information or missing a great deal of foreground information. Moreover, the global matching between the target and search region also largely neglects the target structure and part-level information. In this paper, to solve the above issues, we propose a simple target-aware Siamese graph attention network for general object tracking. We propose to establish part-to-part correspondence between the target and the search region with a complete bipartite graph, and apply the graph attention mechanism to propagate target information from the template feature to the search feature. Further, instead of using the pre-fixed region cropping for template-feature-area selection, we investigate a target-aware area selection mechanism to fit the size and aspect ratio variations of different objects. Experiments on challenging benchmarks including GOT-10k, UAV123, OTB-100 and LaSOT demonstrate that the proposed SiamGAT outperforms many state-of-the-art trackers and achieves leading performance. Code is available at: https://git.io/SiamGAT
Improving auto-encoder novelty detection using channel attention and entropy minimization
Jul 03, 2020

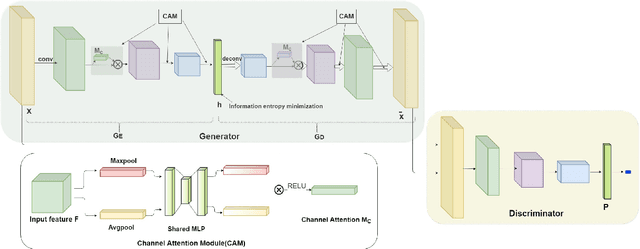
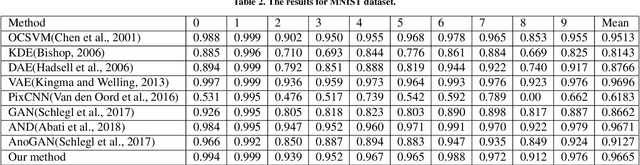
Novelty detection is a important research area which mainly solves the classification problem of inliers which usually consists of normal samples and outliers composed of abnormal samples. We focus on the role of auto-encoder in novelty detection and further improved the performance of such methods based on auto-encoder through two main contributions. Firstly, we introduce attention mechanism into novelty detection. Under the action of attention mechanism, auto-encoder can pay more attention to the representation of inlier samples through adversarial training. Secondly, we try to constrain the expression of the latent space by information entropy. Experimental results on three public datasets show that the proposed method has potential performance for novelty detection.
SiamCAR: Siamese Fully Convolutional Classification and Regression for Visual Tracking
Dec 13, 2019

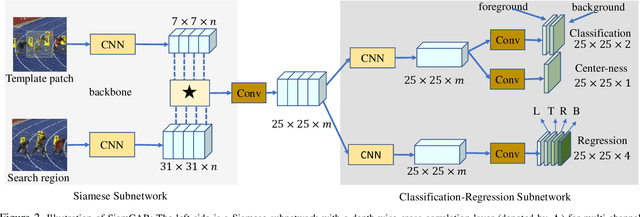
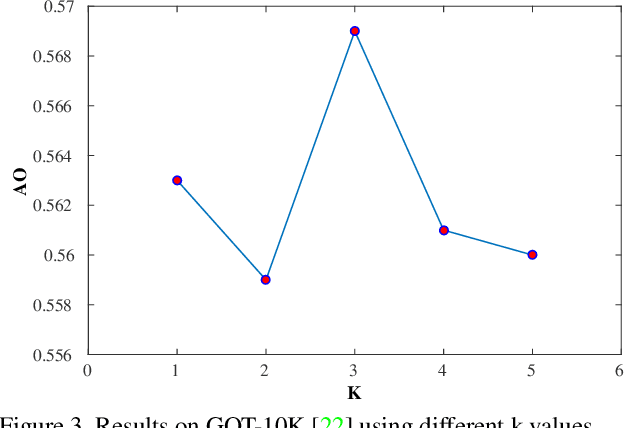
By decomposing the visual tracking task into two subproblems as classification for pixel category and regression for object bounding box at this pixel, we propose a novel fully convolutional Siamese network to solve visual tracking end-to-end in a per-pixel manner. The proposed framework SiamCAR consists of two simple subnetworks: one Siamese subnetwork for feature extraction and one classification-regression subnetwork for bounding box prediction. Our framework takes ResNet-50 as backbone. Different from state-of-the-art trackers like Siamese-RPN, SiamRPN++ and SPM, which are based on region proposal, the proposed framework is both proposal and anchor free. Consequently, we are able to avoid the tricky hyper-parameter tuning of anchors and reduce human intervention. The proposed framework is simple, neat and effective. Extensive experiments and comparisons with state-of-the-art trackers are conducted on many challenging benchmarks like GOT-10K, LaSOT, UAV123 and OTB-50. Without bells and whistles, our SiamCAR achieves the leading performance with a considerable real-time speed.
End-to-end feature fusion siamese network for adaptive visual tracking
Feb 04, 2019


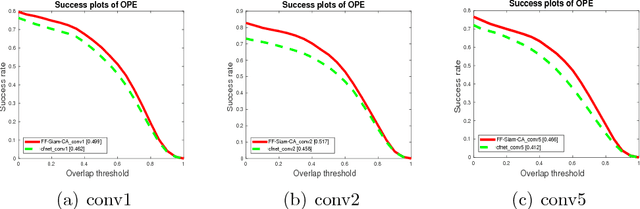
According to observations, different visual objects have different salient features in different scenarios. Even for the same object, its salient shape and appearance features may change greatly from time to time in a long-term tracking task. Motivated by them, we proposed an end-to-end feature fusion framework based on Siamese network, named FF-Siam, which can effectively fuse different features for adaptive visual tracking. The framework consists of four layers. A feature extraction layer is designed to extract the different features of the target region and search region. The extracted features are then put into a weight generation layer to obtain the channel weights, which indicate the importance of different feature channels. Both features and the channel weights are utilized in a template generation layer to generate a discriminative template. Finally, the corresponding response maps created by the convolution of the search region features and the template are applied with a fusion layer to obtain the final response map for locating the target. Experimental results demonstrate that the proposed framework achieves state-of-the-art performance on the popular Temple-Color, OTB50 and UAV123 benchmarks.