 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointAttN: You Only Need Attention for Point Cloud Completion
Mar 16, 2022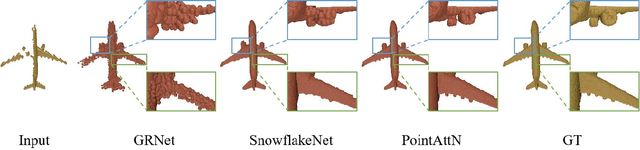
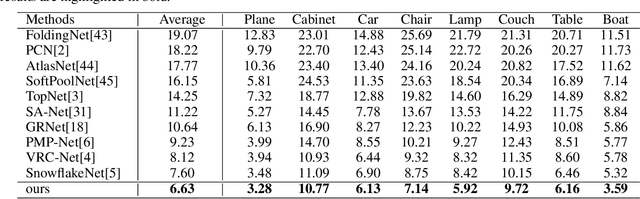
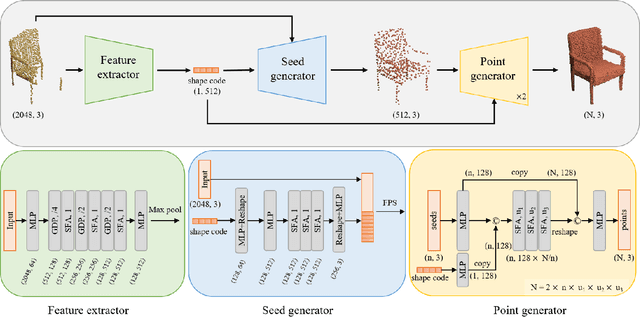
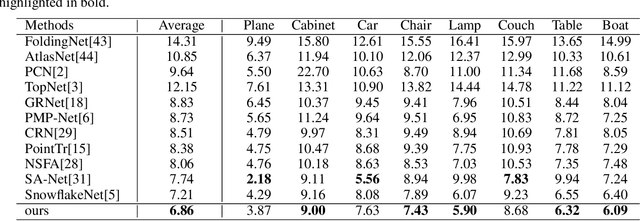
Point cloud completion referring to completing 3D shapes from partial 3D point clouds is a fundamental problem for 3D point cloud analysis tasks. Benefiting from the development of deep neural networks, researches on point cloud completion have made great progress in recent years. However, the explicit local region partition like kNNs involved in existing methods makes them sensitive to the density distribution of point clouds. Moreover, it serves limited receptive fields that prevent capturing features from long-range context information. To solve the problems, we leverage the cross-attention and self-attention mechanisms to design novel neural network for processing point cloud in a per-point manner to eliminate kNNs. Two essential blocks Geometric Details Perception (GDP) and Self-Feature Augment (SFA) are proposed to establish the short-range and long-range structural relationships directly among points in a simple yet effective way via attention mechanism. Then based on GDP and SFA, we construct a new framework with popular encoder-decoder architecture for point cloud completion. The proposed framework, namely PointAttN, is simple, neat and effective, which can precisely capture the structural information of 3D shapes and predict complete point clouds with highly detailed geometries. Experimental results demonstrate that our PointAttN outperforms state-of-the-art methods by a large margin on popular benchmarks like Completion3D and PCN. Code is available at: https://github.com/ohhhyeahhh/PointAttN
Blind Motion Deblurring with Cycle Generative Adversarial Networks
Jan 08, 2019
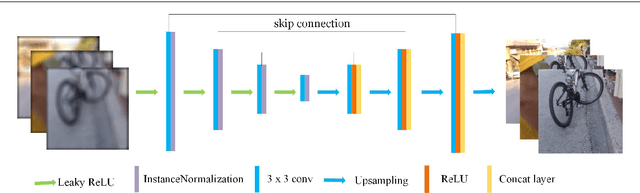

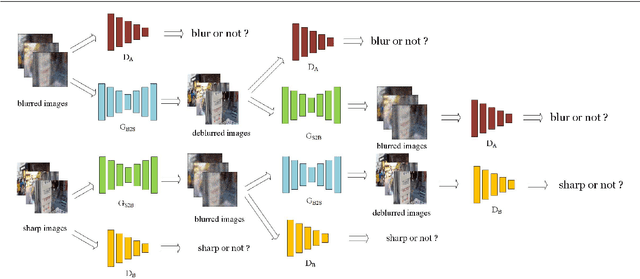
Blind motion deblurring is one of the most basic and challenging problems in image processing and computer vision. It aims to recover a sharp image from its blurred version knowing nothing about the blur process. Many existing methods use Maximum A Posteriori (MAP) or Expectation Maximization (EM) frameworks to deal with this kind of problems, but they cannot handle well the figh frequency features of natural images. Most recently, deep neural networks have been emerging as a powerful tool for image deblurring. In this paper, we prove that encoder-decoder architecture gives better results for image deblurring tasks. In addition, we propose a novel end-to-end learning model which refines generative adversarial network by many novel training strategies so as to tackle the problem of deblurring. Experimental results show that our model can capture high frequency features well, and the results on benchmark dataset show that proposed model achieves the competitive performance.