 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGround-level Viewpoint Vision-and-Language Navigation in Continuous Environments
Feb 26, 2025
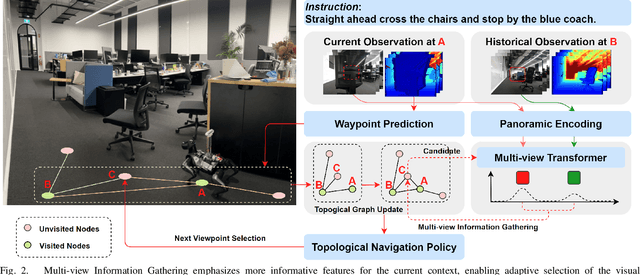

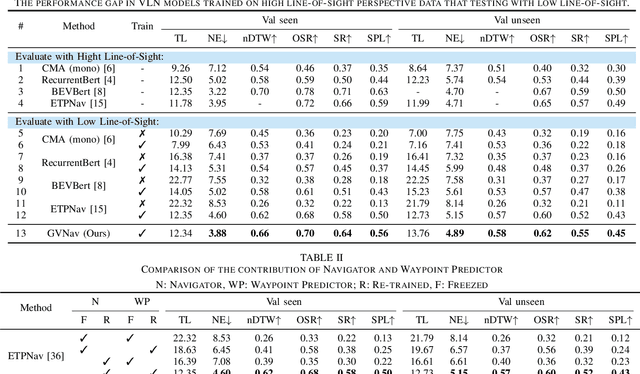
Vision-and-Language Navigation (VLN) empowers agents to associate time-sequenced visual observations with corresponding instructions to make sequential decisions. However, generalization remains a persistent challenge, particularly when dealing with visually diverse scenes or transitioning from simulated environments to real-world deployment. In this paper, we address the mismatch between human-centric instructions and quadruped robots with a low-height field of view, proposing a Ground-level Viewpoint Navigation (GVNav) approach to mitigate this issue. This work represents the first attempt to highlight the generalization gap in VLN across varying heights of visual observation in realistic robot deployments. Our approach leverages weighted historical observations as enriched spatiotemporal contexts for instruction following, effectively managing feature collisions within cells by assigning appropriate weights to identical features across different viewpoints. This enables low-height robots to overcome challenges such as visual obstructions and perceptual mismatches. Additionally, we transfer the connectivity graph from the HM3D and Gibson datasets as an extra resource to enhance spatial priors and a more comprehensive representation of real-world scenarios, leading to improved performance and generalizability of the waypoint predictor in real-world environments. Extensive experiments demonstrate that our Ground-level Viewpoint Navigation (GVnav) approach significantly improves performance in both simulated environments and real-world deployments with quadruped robots.
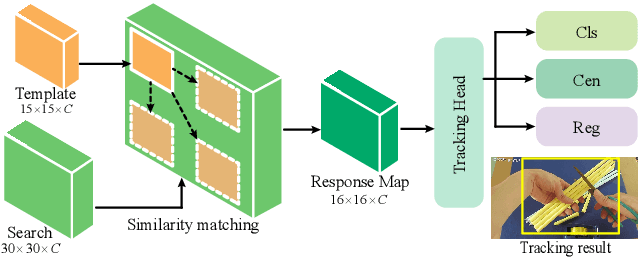
Context-Aware Integration of Language and Visual References for Natural Language Tracking
Mar 29, 2024Tracking by natural language specification (TNL) aims to consistently localize a target in a video sequence given a linguistic description in the initial frame. Existing methodologies perform language-based and template-based matching for target reasoning separately and merge the matching results from two sources, which suffer from tracking drift when language and visual templates miss-align with the dynamic target state and ambiguity in the later merging stage. To tackle the issues, we propose a joint multi-modal tracking framework with 1) a prompt modulation module to leverage the complementarity between temporal visual templates and language expressions, enabling precise and context-aware appearance and linguistic cues, and 2) a unified target decoding module to integrate the multi-modal reference cues and executes the integrated queries on the search image to predict the target location in an end-to-end manner directly. This design ensures spatio-temporal consistency by leveraging historical visual information and introduces an integrated solution, generating predictions in a single step. Extensive experiments conducted on TNL2K, OTB-Lang, LaSOT, and RefCOCOg validate the efficacy of our proposed approach. The results demonstrate competitive performance against state-of-the-art methods for both tracking and grounding.
InterTracker: Discovering and Tracking General Objects Interacting with Hands in the Wild
Aug 14, 2023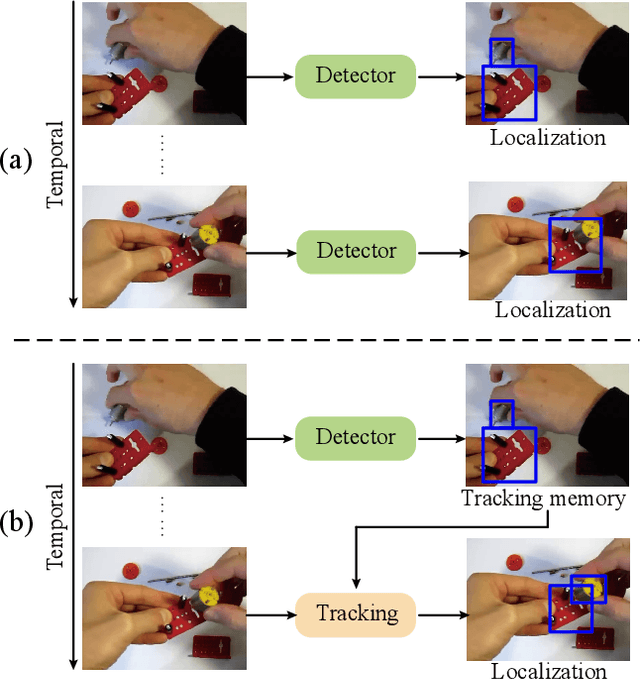
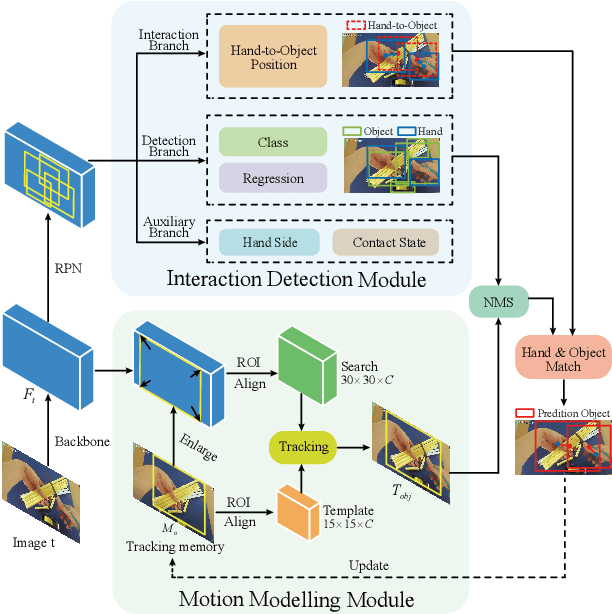

Understanding human interaction with objects is an important research topic for embodied Artificial Intelligence and identifying the objects that humans are interacting with is a primary problem for interaction understanding. Existing methods rely on frame-based detectors to locate interacting objects. However, this approach is subjected to heavy occlusions, background clutter, and distracting objects. To address the limitations, in this paper, we propose to leverage spatio-temporal information of hand-object interaction to track interactive objects under these challenging cases. Without prior knowledge of the general objects to be tracked like object tracking problems, we first utilize the spatial relation between hands and objects to adaptively discover the interacting objects from the scene. Second, the consistency and continuity of the appearance of objects between successive frames are exploited to track the objects. With this tracking formulation, our method also benefits from training on large-scale general object-tracking datasets. We further curate a video-level hand-object interaction dataset for testing and evaluation from 100DOH. The quantitative results demonstrate that our proposed method outperforms the state-of-the-art methods. Specifically, in scenes with continuous interaction with different objects, we achieve an impressive improvement of about 10% as evaluated using the Average Precision (AP) metric. Our qualitative findings also illustrate that our method can produce more continuous trajectories for interacting objects.
Graph Attention Tracking
Nov 23, 2020



Siamese network based trackers formulate the visual tracking task as a similarity matching problem. Almost all popular Siamese trackers realize the similarity learning via convolutional feature cross-correlation between a target branch and a search branch. However, since the size of target feature region needs to be pre-fixed, these cross-correlation base methods suffer from either reserving much adverse background information or missing a great deal of foreground information. Moreover, the global matching between the target and search region also largely neglects the target structure and part-level information. In this paper, to solve the above issues, we propose a simple target-aware Siamese graph attention network for general object tracking. We propose to establish part-to-part correspondence between the target and the search region with a complete bipartite graph, and apply the graph attention mechanism to propagate target information from the template feature to the search feature. Further, instead of using the pre-fixed region cropping for template-feature-area selection, we investigate a target-aware area selection mechanism to fit the size and aspect ratio variations of different objects. Experiments on challenging benchmarks including GOT-10k, UAV123, OTB-100 and LaSOT demonstrate that the proposed SiamGAT outperforms many state-of-the-art trackers and achieves leading performance. Code is available at: https://git.io/SiamGAT