 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWBCAtt+: Fine-Grained Pixel-Level Morphological Annotations for White Blood Cell Images
May 19, 2026The microscopic examination of white blood cells (WBCs) plays a fundamental role in pathology and is essential for diagnosing blood disorders such as leukemia and anemia. To support further research on WBC images, multiple datasets have been proposed. However, they mainly annotate cell categories, and lack detailed morphological characteristics that pathologists use to explain their interpretations of cells. To address this gap, we introduce WBCAtt+, a novel dataset of WBC images densely annotated with 11 morphological attributes and five pixel-level cell components. With 113k image-level labels and 10k segmentation maps, WBCAtt+ is the first to provide comprehensive annotations for WBC images. Leveraging this dataset, we provide baseline models for attribute recognition and semantic segmentation. We also design an attribute recognition model to incorporate compositional structure of cells, further improving the recognition performance. Lastly, we showcase various applications enabled by our dataset, such as explainable AI models, including counterfactual example generation. \revision{The dataset and code are publicly available\footnote{https://doi.org/10.57967/hf/8143}}.
RSGround-R1: Rethinking Remote Sensing Visual Grounding through Spatial Reasoning
Jan 29, 2026Remote Sensing Visual Grounding (RSVG) aims to localize target objects in large-scale aerial imagery based on natural language descriptions. Owing to the vast spatial scale and high semantic ambiguity of remote sensing scenes, these descriptions often rely heavily on positional cues, posing unique challenges for Multimodal Large Language Models (MLLMs) in spatial reasoning. To leverage this unique feature, we propose a reasoning-guided, position-aware post-training framework, dubbed \textbf{RSGround-R1}, to progressively enhance spatial understanding. Specifically, we first introduce Chain-of-Thought Supervised Fine-Tuning (CoT-SFT) using synthetically generated RSVG reasoning data to establish explicit position awareness. Reinforcement Fine-Tuning (RFT) is then applied, augmented by our newly designed positional reward that provides continuous and distance-aware guidance toward accurate localization. Moreover, to mitigate incoherent localization behaviors across rollouts, we introduce a spatial consistency guided optimization scheme that dynamically adjusts policy updates based on their spatial coherence, ensuring stable and robust convergence. Extensive experiments on RSVG benchmarks demonstrate superior performance and generalization of our model.
DiffStyle3D: Consistent 3D Gaussian Stylization via Attention Optimization
Jan 27, 20263D style transfer enables the creation of visually expressive 3D content, enriching the visual appearance of 3D scenes and objects. However, existing VGG- and CLIP-based methods struggle to model multi-view consistency within the model itself, while diffusion-based approaches can capture such consistency but rely on denoising directions, leading to unstable training. To address these limitations, we propose DiffStyle3D, a novel diffusion-based paradigm for 3DGS style transfer that directly optimizes in the latent space. Specifically, we introduce an Attention-Aware Loss that performs style transfer by aligning style features in the self-attention space, while preserving original content through content feature alignment. Inspired by the geometric invariance of 3D stylization, we propose a Geometry-Guided Multi-View Consistency method that integrates geometric information into self-attention to enable cross-view correspondence modeling. Based on geometric information, we additionally construct a geometry-aware mask to prevent redundant optimization in overlapping regions across views, which further improves multi-view consistency. Extensive experiments show that DiffStyle3D outperforms state-of-the-art methods, achieving higher stylization quality and visual realism.
MeViS: A Multi-Modal Dataset for Referring Motion Expression Video Segmentation
Dec 11, 2025



This paper proposes a large-scale multi-modal dataset for referring motion expression video segmentation, focusing on segmenting and tracking target objects in videos based on language description of objects' motions. Existing referring video segmentation datasets often focus on salient objects and use language expressions rich in static attributes, potentially allowing the target object to be identified in a single frame. Such datasets underemphasize the role of motion in both videos and languages. To explore the feasibility of using motion expressions and motion reasoning clues for pixel-level video understanding, we introduce MeViS, a dataset containing 33,072 human-annotated motion expressions in both text and audio, covering 8,171 objects in 2,006 videos of complex scenarios. We benchmark 15 existing methods across 4 tasks supported by MeViS, including 6 referring video object segmentation (RVOS) methods, 3 audio-guided video object segmentation (AVOS) methods, 2 referring multi-object tracking (RMOT) methods, and 4 video captioning methods for the newly introduced referring motion expression generation (RMEG) task. The results demonstrate weaknesses and limitations of existing methods in addressing motion expression-guided video understanding. We further analyze the challenges and propose an approach LMPM++ for RVOS/AVOS/RMOT that achieves new state-of-the-art results. Our dataset provides a platform that facilitates the development of motion expression-guided video understanding algorithms in complex video scenes. The proposed MeViS dataset and the method's source code are publicly available at https://henghuiding.com/MeViS/
* IEEE TPAMI, Project Page: https://henghuiding.com/MeViS/
SplitFlux: Learning to Decouple Content and Style from a Single Image
Nov 19, 2025



Disentangling image content and style is essential for customized image generation. Existing SDXL-based methods struggle to achieve high-quality results, while the recently proposed Flux model fails to achieve effective content-style separation due to its underexplored characteristics. To address these challenges, we conduct a systematic analysis of Flux and make two key observations: (1) Single Dream Blocks are essential for image generation; and (2) Early single stream blocks mainly control content, whereas later blocks govern style. Based on these insights, we propose SplitFlux, which disentangles content and style by fine-tuning the single dream blocks via LoRA, enabling the disentangled content to be re-embedded into new contexts. It includes two key components: (1) Rank-Constrained Adaptation. To preserve content identity and structure, we compress the rank and amplify the magnitude of updates within specific blocks, preventing content leakage into style blocks. (2) Visual-Gated LoRA. We split the content LoRA into two branches with different ranks, guided by image saliency. The high-rank branch preserves primary subject information, while the low-rank branch encodes residual details, mitigating content overfitting and enabling seamless re-embedding. Extensive experiments demonstrate that SplitFlux consistently outperforms state-of-the-art methods, achieving superior content preservation and stylization quality across diverse scenarios.
FantasyStyle: Controllable Stylized Distillation for 3D Gaussian Splatting
Aug 11, 2025The success of 3DGS in generative and editing applications has sparked growing interest in 3DGS-based style transfer. However, current methods still face two major challenges: (1) multi-view inconsistency often leads to style conflicts, resulting in appearance smoothing and distortion; and (2) heavy reliance on VGG features, which struggle to disentangle style and content from style images, often causing content leakage and excessive stylization. To tackle these issues, we introduce \textbf{FantasyStyle}, a 3DGS-based style transfer framework, and the first to rely entirely on diffusion model distillation. It comprises two key components: (1) \textbf{Multi-View Frequency Consistency}. We enhance cross-view consistency by applying a 3D filter to multi-view noisy latent, selectively reducing low-frequency components to mitigate stylized prior conflicts. (2) \textbf{Controllable Stylized Distillation}. To suppress content leakage from style images, we introduce negative guidance to exclude undesired content. In addition, we identify the limitations of Score Distillation Sampling and Delta Denoising Score in 3D style transfer and remove the reconstruction term accordingly. Building on these insights, we propose a controllable stylized distillation that leverages negative guidance to more effectively optimize the 3D Gaussians. Extensive experiments demonstrate that our method consistently outperforms state-of-the-art approaches, achieving higher stylization quality and visual realism across various scenes and styles.
ReferSplat: Referring Segmentation in 3D Gaussian Splatting
Aug 11, 2025We introduce Referring 3D Gaussian Splatting Segmentation (R3DGS), a new task that aims to segment target objects in a 3D Gaussian scene based on natural language descriptions, which often contain spatial relationships or object attributes. This task requires the model to identify newly described objects that may be occluded or not directly visible in a novel view, posing a significant challenge for 3D multi-modal understanding. Developing this capability is crucial for advancing embodied AI. To support research in this area, we construct the first R3DGS dataset, Ref-LERF. Our analysis reveals that 3D multi-modal understanding and spatial relationship modeling are key challenges for R3DGS. To address these challenges, we propose ReferSplat, a framework that explicitly models 3D Gaussian points with natural language expressions in a spatially aware paradigm. ReferSplat achieves state-of-the-art performance on both the newly proposed R3DGS task and 3D open-vocabulary segmentation benchmarks. Dataset and code are available at https://github.com/heshuting555/ReferSplat.
MOSEv2: A More Challenging Dataset for Video Object Segmentation in Complex Scenes
Aug 07, 2025Video object segmentation (VOS) aims to segment specified target objects throughout a video. Although state-of-the-art methods have achieved impressive performance (e.g., 90+% J&F) on existing benchmarks such as DAVIS and YouTube-VOS, these datasets primarily contain salient, dominant, and isolated objects, limiting their generalization to real-world scenarios. To advance VOS toward more realistic environments, coMplex video Object SEgmentation (MOSEv1) was introduced to facilitate VOS research in complex scenes. Building on the strengths and limitations of MOSEv1, we present MOSEv2, a significantly more challenging dataset designed to further advance VOS methods under real-world conditions. MOSEv2 consists of 5,024 videos and over 701,976 high-quality masks for 10,074 objects across 200 categories. Compared to its predecessor, MOSEv2 introduces significantly greater scene complexity, including more frequent object disappearance and reappearance, severe occlusions and crowding, smaller objects, as well as a range of new challenges such as adverse weather (e.g., rain, snow, fog), low-light scenes (e.g., nighttime, underwater), multi-shot sequences, camouflaged objects, non-physical targets (e.g., shadows, reflections), scenarios requiring external knowledge, etc. We benchmark 20 representative VOS methods under 5 different settings and observe consistent performance drops. For example, SAM2 drops from 76.4% on MOSEv1 to only 50.9% on MOSEv2. We further evaluate 9 video object tracking methods and find similar declines, demonstrating that MOSEv2 presents challenges across tasks. These results highlight that despite high accuracy on existing datasets, current VOS methods still struggle under real-world complexities. MOSEv2 is publicly available at https://MOSE.video.
Multimodal Referring Segmentation: A Survey
Aug 01, 2025Multimodal referring segmentation aims to segment target objects in visual scenes, such as images, videos, and 3D scenes, based on referring expressions in text or audio format. This task plays a crucial role in practical applications requiring accurate object perception based on user instructions. Over the past decade, it has gained significant attention in the multimodal community, driven by advances in convolutional neural networks, transformers, and large language models, all of which have substantially improved multimodal perception capabilities. This paper provides a comprehensive survey of multimodal referring segmentation. We begin by introducing this field's background, including problem definitions and commonly used datasets. Next, we summarize a unified meta architecture for referring segmentation and review representative methods across three primary visual scenes, including images, videos, and 3D scenes. We further discuss Generalized Referring Expression (GREx) methods to address the challenges of real-world complexity, along with related tasks and practical applications. Extensive performance comparisons on standard benchmarks are also provided. We continually track related works at https://github.com/henghuiding/Awesome-Multimodal-Referring-Segmentation.
PVUW 2025 Challenge Report: Advances in Pixel-level Understanding of Complex Videos in the Wild
Apr 15, 2025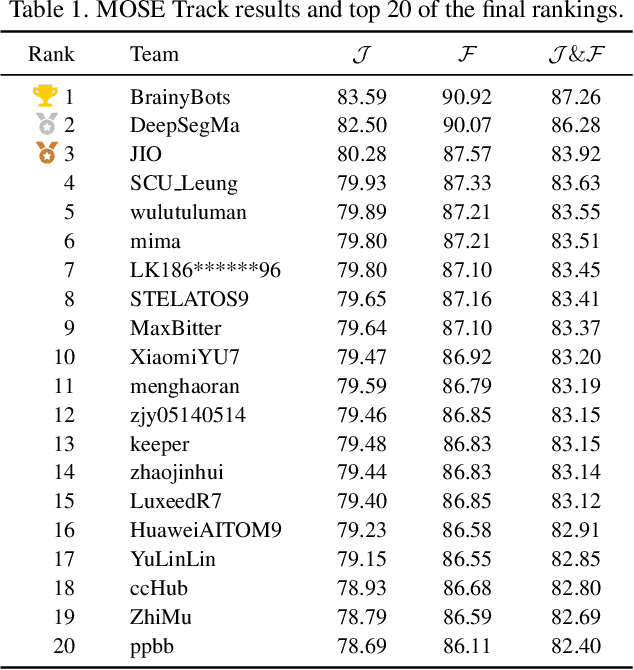
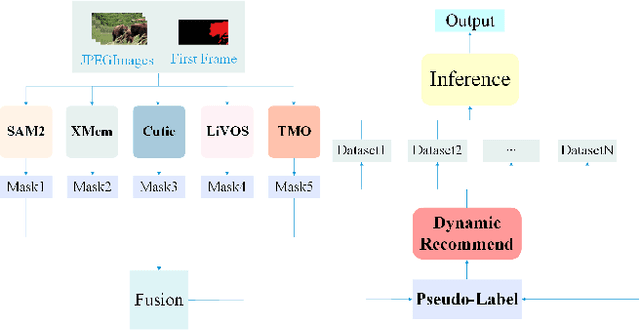
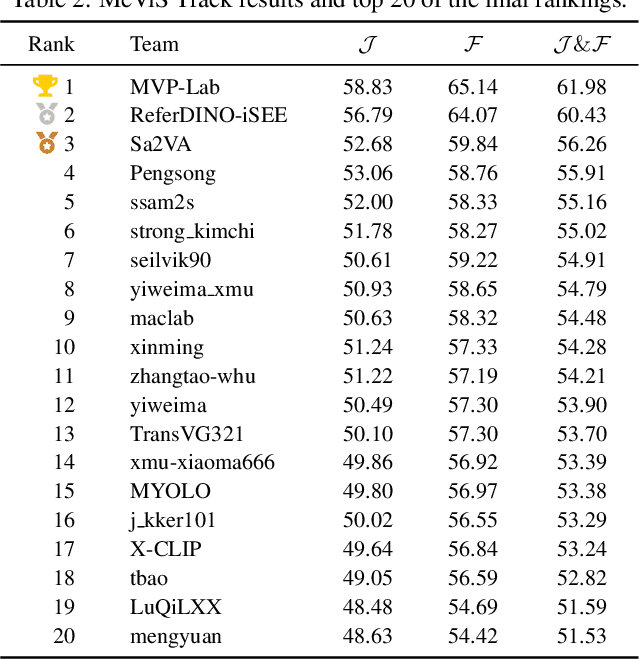
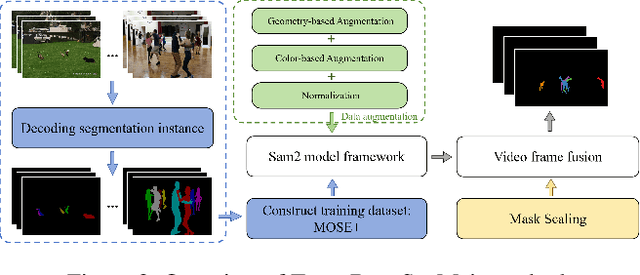
This report provides a comprehensive overview of the 4th Pixel-level Video Understanding in the Wild (PVUW) Challenge, held in conjunction with CVPR 2025. It summarizes the challenge outcomes, participating methodologies, and future research directions. The challenge features two tracks: MOSE, which focuses on complex scene video object segmentation, and MeViS, which targets motion-guided, language-based video segmentation. Both tracks introduce new, more challenging datasets designed to better reflect real-world scenarios. Through detailed evaluation and analysis, the challenge offers valuable insights into the current state-of-the-art and emerging trends in complex video segmentation. More information can be found on the workshop website: https://pvuw.github.io/.