 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$\textbf{AGT$^{AO}$}$: Robust and Stabilized LLM Unlearning via Adversarial Gating Training with Adaptive Orthogonality
Feb 02, 2026While Large Language Models (LLMs) have achieved remarkable capabilities, they unintentionally memorize sensitive data, posing critical privacy and security risks. Machine unlearning is pivotal for mitigating these risks, yet existing paradigms face a fundamental dilemma: aggressive unlearning often induces catastrophic forgetting that degrades model utility, whereas conservative strategies risk superficial forgetting, leaving models vulnerable to adversarial recovery. To address this trade-off, we propose $\textbf{AGT$^{AO}$}$ (Adversarial Gating Training with Adaptive Orthogonality), a unified framework designed to reconcile robust erasure with utility preservation. Specifically, our approach introduces $\textbf{Adaptive Orthogonality (AO)}$ to dynamically mitigate geometric gradient conflicts between forgetting and retention objectives, thereby minimizing unintended knowledge degradation. Concurrently, $\textbf{Adversarial Gating Training (AGT)}$ formulates unlearning as a latent-space min-max game, employing a curriculum-based gating mechanism to simulate and counter internal recovery attempts. Extensive experiments demonstrate that $\textbf{AGT$^{AO}$}$ achieves a superior trade-off between unlearning efficacy (KUR $\approx$ 0.01) and model utility (MMLU 58.30). Code is available at https://github.com/TiezMind/AGT-unlearning.
ErrEval: Error-Aware Evaluation for Question Generation through Explicit Diagnostics
Jan 15, 2026Automatic Question Generation (QG) often produces outputs with critical defects, such as factual hallucinations and answer mismatches. However, existing evaluation methods, including LLM-based evaluators, mainly adopt a black-box and holistic paradigm without explicit error modeling, leading to the neglect of such defects and overestimation of question quality. To address this issue, we propose ErrEval, a flexible and Error-aware Evaluation framework that enhances QG evaluation through explicit error diagnostics. Specifically, ErrEval reformulates evaluation as a two-stage process of error diagnosis followed by informed scoring. At the first stage, a lightweight plug-and-play Error Identifier detects and categorizes common errors across structural, linguistic, and content-related aspects. These diagnostic signals are then incorporated as explicit evidence to guide LLM evaluators toward more fine-grained and grounded judgments. Extensive experiments on three benchmarks demonstrate the effectiveness of ErrEval, showing that incorporating explicit diagnostics improves alignment with human judgments. Further analyses confirm that ErrEval effectively mitigates the overestimation of low-quality questions.
GKG-LLM: A Unified Framework for Generalized Knowledge Graph Construction
Mar 17, 2025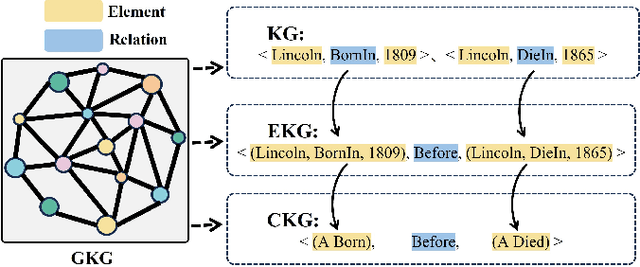



The construction of Generalized Knowledge Graph (GKG), including knowledge graph, event knowledge graph and commonsense knowledge graph, is fundamental for various natural language processing tasks. Current studies typically construct these types of graph separately, overlooking holistic insights and potential unification that could be beneficial in computing resources and usage perspectives. However, a key challenge in developing a unified framework for GKG is obstacles arising from task-specific differences. In this study, we propose a unified framework for constructing generalized knowledge graphs to address this challenge. First, we collect data from 15 sub-tasks in 29 datasets across the three types of graphs, categorizing them into in-sample, counter-task, and out-of-distribution (OOD) data. Then, we propose a three-stage curriculum learning fine-tuning framework, by iteratively injecting knowledge from the three types of graphs into the Large Language Models. Extensive experiments show that our proposed model improves the construction of all three graph types across in-domain, OOD and counter-task data.
Hierarchical Alignment-enhanced Adaptive Grounding Network for Generalized Referring Expression Comprehension
Jan 02, 2025In this work, we address the challenging task of Generalized Referring Expression Comprehension (GREC). Compared to the classic Referring Expression Comprehension (REC) that focuses on single-target expressions, GREC extends the scope to a more practical setting by further encompassing no-target and multi-target expressions. Existing REC methods face challenges in handling the complex cases encountered in GREC, primarily due to their fixed output and limitations in multi-modal representations. To address these issues, we propose a Hierarchical Alignment-enhanced Adaptive Grounding Network (HieA2G) for GREC, which can flexibly deal with various types of referring expressions. First, a Hierarchical Multi-modal Semantic Alignment (HMSA) module is proposed to incorporate three levels of alignments, including word-object, phrase-object, and text-image alignment. It enables hierarchical cross-modal interactions across multiple levels to achieve comprehensive and robust multi-modal understanding, greatly enhancing grounding ability for complex cases. Then, to address the varying number of target objects in GREC, we introduce an Adaptive Grounding Counter (AGC) to dynamically determine the number of output targets. Additionally, an auxiliary contrastive loss is employed in AGC to enhance object-counting ability by pulling in multi-modal features with the same counting and pushing away those with different counting. Extensive experimental results show that HieA2G achieves new state-of-the-art performance on the challenging GREC task and also the other 4 tasks, including REC, Phrase Grounding, Referring Expression Segmentation (RES), and Generalized Referring Expression Segmentation (GRES), demonstrating the remarkable superiority and generalizability of the proposed HieA2G.
QGEval: A Benchmark for Question Generation Evaluation
Jun 09, 2024
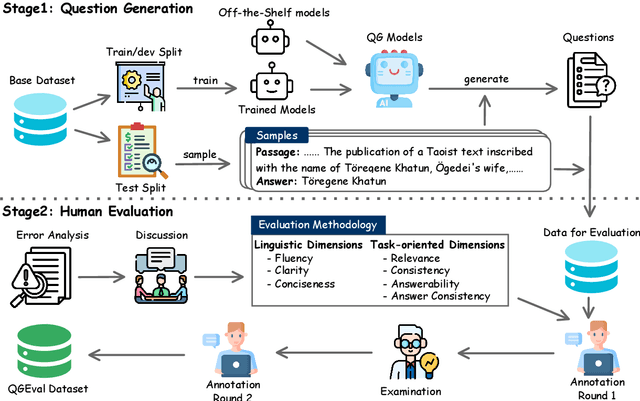
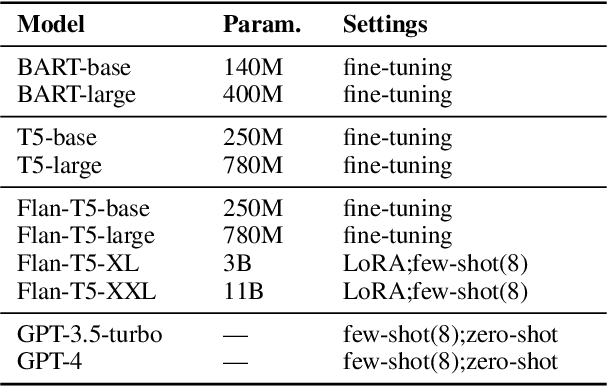
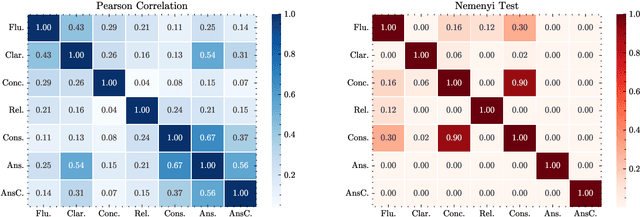
Automatically generated questions often suffer from problems such as unclear expression or factual inaccuracies, requiring a reliable and comprehensive evaluation of their quality. Human evaluation is frequently used in the field of question generation (QG) and is one of the most accurate evaluation methods. It also serves as the standard for automatic metrics. However, there is a lack of unified evaluation criteria, which hampers the development of both QG technologies and automatic evaluation methods. To address this, we propose QGEval, a multi-dimensional Evaluation benchmark for Question Generation, which evaluates both generated questions and existing automatic metrics across 7 dimensions: fluency, clarity, conciseness, relevance, consistency, answerability, and answer consistency. We demonstrate the appropriateness of these dimensions by examining their correlations and distinctions. Analysis with QGEval reveals that 1) most QG models perform unsatisfactorily in terms of answerability and answer consistency, and 2) existing metrics fail to align well with human assessments when evaluating generated questions across the 7 dimensions. We expect this work to foster the development of both QG technologies and automatic metrics for QG.
Knowledge forest: a novel model to organize knowledge fragments
Dec 14, 2019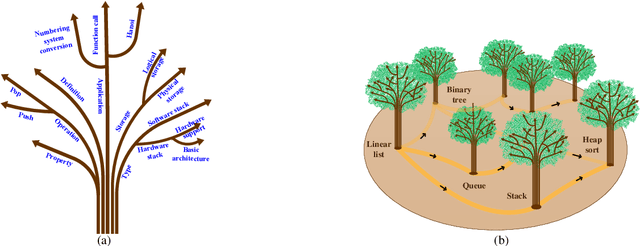
With the rapid growth of knowledge, it shows a steady trend of knowledge fragmentization. Knowledge fragmentization manifests as that the knowledge related to a specific topic in a course is scattered in isolated and autonomous knowledge sources. We term the knowledge of a facet in a specific topic as a knowledge fragment. The problem of knowledge fragmentization brings two challenges: First, knowledge is scattered in various knowledge sources, which exerts users' considerable efforts to search for the knowledge of their interested topics, thereby leading to information overload. Second, learning dependencies which refer to the precedence relationships between topics in the learning process are concealed by the isolation and autonomy of knowledge sources, thus causing learning disorientation. To solve the knowledge fragmentization problem, we propose a novel knowledge organization model, knowledge forest, which consists of facet trees and learning dependencies. Facet trees can organize knowledge fragments with facet hyponymy to alleviate information overload. Learning dependencies can organize disordered topics to cope with learning disorientation. We conduct extensive experiments on three manually constructed datasets from the Data Structure, Data Mining, and Computer Network courses, and the experimental results show that knowledge forest can effectively organize knowledge fragments, and alleviate information overload and learning disorientation.
Extended Answer and Uncertainty Aware Neural Question Generation
Nov 19, 2019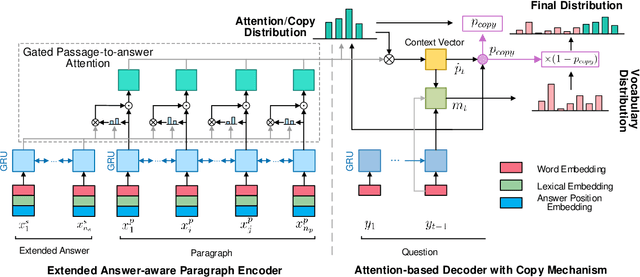
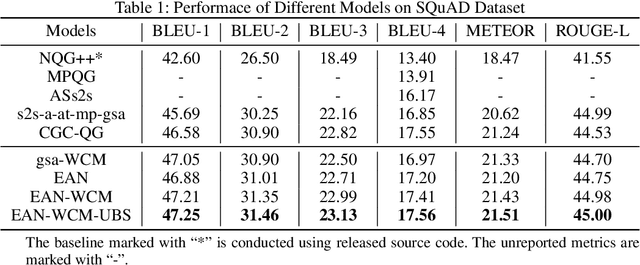
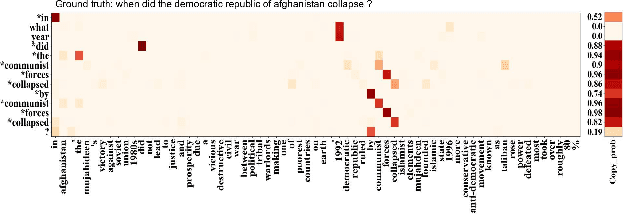

In this paper, we study automatic question generation, the task of creating questions from corresponding text passages where some certain spans of the text can serve as the answers. We propose an Extended Answer-aware Network (EAN) which is trained with Word-based Coverage Mechanism (WCM) and decodes with Uncertainty-aware Beam Search (UBS). The EAN represents the target answer by its surrounding sentence with an encoder, and incorporates the information of the extended answer into paragraph representation with gated paragraph-to-answer attention to tackle the problem of the inadequate representation of the target answer. To reduce undesirable repetition, the WCM penalizes repeatedly attending to the same words at different time-steps in the training stage. The UBS aims to seek a better balance between the model confidence in copying words from an input text paragraph and the confidence in generating words from a vocabulary. We conduct experiments on the SQuAD dataset, and the results show our approach achieves significant performance improvement.