 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReDiffuse: Rotation Equivariant Diffusion Model for Multi-focus Image Fusion
Mar 22, 2026Diffusion models have achieved impressive performance on multi-focus image fusion (MFIF). However, a key challenge in applying diffusion models to the ill-posed MFIF problem is that defocus blur can make common symmetric geometric structures (e.g., textures and edges) appear warped and deformed, often leading to unexpected artifacts in the fused images. Therefore, embedding rotation equivariance into diffusion networks is essential, as it enables the fusion results to faithfully preserve the original orientation and structural consistency of geometric patterns underlying the input images. Motivated by this, we propose ReDiffuse, a rotation-equivariant diffusion model for MFIF. Specifically, we carefully construct the basic diffusion architectures to achieve end-to-end rotation equivariance. We also provide a rigorous theoretical analysis to evaluate its intrinsic equivariance error, demonstrating the validity of embedding equivariance structures. ReDiffuse is comprehensively evaluated against various MFIF methods across four datasets (Lytro, MFFW, MFI-WHU, and Road-MF). Results demonstrate that ReDiffuse achieves competitive performance, with improvements of 0.28-6.64\% across six evaluation metrics. The code is available at https://github.com/MorvanLi/ReDiffuse.
Towards Efficient and Robust Linguistic Emotion Diagnosis for Mental Health via Multi-Agent Instruction Refinement
Jan 20, 2026Linguistic expressions of emotions such as depression, anxiety, and trauma-related states are pervasive in clinical notes, counseling dialogues, and online mental health communities, and accurate recognition of these emotions is essential for clinical triage, risk assessment, and timely intervention. Although large language models (LLMs) have demonstrated strong generalization ability in emotion analysis tasks, their diagnostic reliability in high-stakes, context-intensive medical settings remains highly sensitive to prompt design. Moreover, existing methods face two key challenges: emotional comorbidity, in which multiple intertwined emotional states complicate prediction, and inefficient exploration of clinically relevant cues. To address these challenges, we propose APOLO (Automated Prompt Optimization for Linguistic Emotion Diagnosis), a framework that systematically explores a broader and finer-grained prompt space to improve diagnostic efficiency and robustness. APOLO formulates instruction refinement as a Partially Observable Markov Decision Process and adopts a multi-agent collaboration mechanism involving Planner, Teacher, Critic, Student, and Target roles. Within this closed-loop framework, the Planner defines an optimization trajectory, while the Teacher-Critic-Student agents iteratively refine prompts to enhance reasoning stability and effectiveness, and the Target agent determines whether to continue optimization based on performance evaluation. Experimental results show that APOLO consistently improves diagnostic accuracy and robustness across domain-specific and stratified benchmarks, demonstrating a scalable and generalizable paradigm for trustworthy LLM applications in mental healthcare.
ErrEval: Error-Aware Evaluation for Question Generation through Explicit Diagnostics
Jan 15, 2026Automatic Question Generation (QG) often produces outputs with critical defects, such as factual hallucinations and answer mismatches. However, existing evaluation methods, including LLM-based evaluators, mainly adopt a black-box and holistic paradigm without explicit error modeling, leading to the neglect of such defects and overestimation of question quality. To address this issue, we propose ErrEval, a flexible and Error-aware Evaluation framework that enhances QG evaluation through explicit error diagnostics. Specifically, ErrEval reformulates evaluation as a two-stage process of error diagnosis followed by informed scoring. At the first stage, a lightweight plug-and-play Error Identifier detects and categorizes common errors across structural, linguistic, and content-related aspects. These diagnostic signals are then incorporated as explicit evidence to guide LLM evaluators toward more fine-grained and grounded judgments. Extensive experiments on three benchmarks demonstrate the effectiveness of ErrEval, showing that incorporating explicit diagnostics improves alignment with human judgments. Further analyses confirm that ErrEval effectively mitigates the overestimation of low-quality questions.
QGEval: A Benchmark for Question Generation Evaluation
Jun 09, 2024
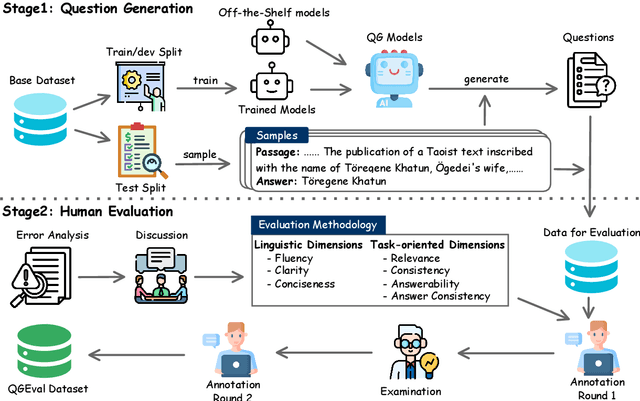
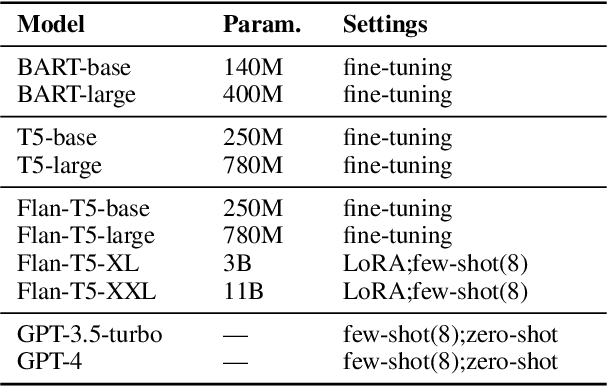
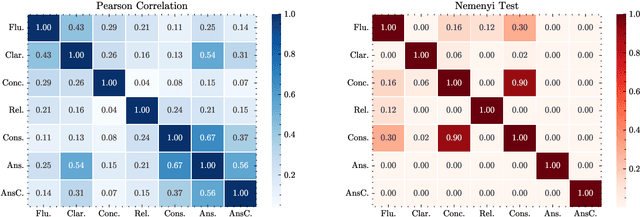
Automatically generated questions often suffer from problems such as unclear expression or factual inaccuracies, requiring a reliable and comprehensive evaluation of their quality. Human evaluation is frequently used in the field of question generation (QG) and is one of the most accurate evaluation methods. It also serves as the standard for automatic metrics. However, there is a lack of unified evaluation criteria, which hampers the development of both QG technologies and automatic evaluation methods. To address this, we propose QGEval, a multi-dimensional Evaluation benchmark for Question Generation, which evaluates both generated questions and existing automatic metrics across 7 dimensions: fluency, clarity, conciseness, relevance, consistency, answerability, and answer consistency. We demonstrate the appropriateness of these dimensions by examining their correlations and distinctions. Analysis with QGEval reveals that 1) most QG models perform unsatisfactorily in terms of answerability and answer consistency, and 2) existing metrics fail to align well with human assessments when evaluating generated questions across the 7 dimensions. We expect this work to foster the development of both QG technologies and automatic metrics for QG.
Robust Learning for Text Classification with Multi-source Noise Simulation and Hard Example Mining
Jul 15, 2021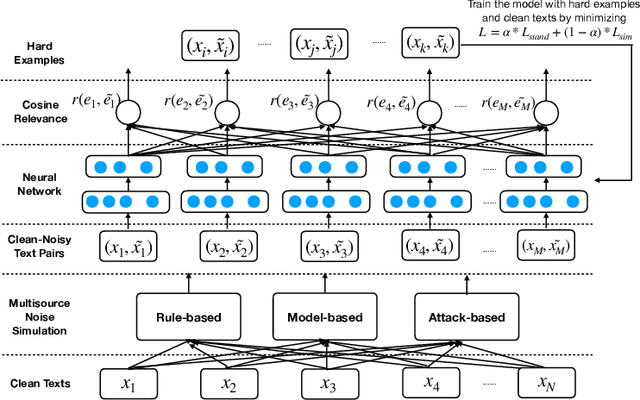
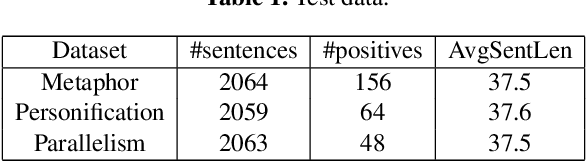
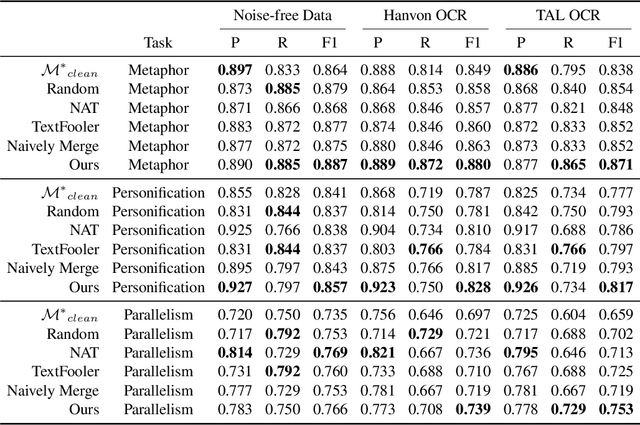
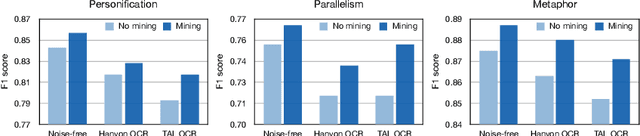
Many real-world applications involve the use of Optical Character Recognition (OCR) engines to transform handwritten images into transcripts on which downstream Natural Language Processing (NLP) models are applied. In this process, OCR engines may introduce errors and inputs to downstream NLP models become noisy. Despite that pre-trained models achieve state-of-the-art performance in many NLP benchmarks, we prove that they are not robust to noisy texts generated by real OCR engines. This greatly limits the application of NLP models in real-world scenarios. In order to improve model performance on noisy OCR transcripts, it is natural to train the NLP model on labelled noisy texts. However, in most cases there are only labelled clean texts. Since there is no handwritten pictures corresponding to the text, it is impossible to directly use the recognition model to obtain noisy labelled data. Human resources can be employed to copy texts and take pictures, but it is extremely expensive considering the size of data for model training. Consequently, we are interested in making NLP models intrinsically robust to OCR errors in a low resource manner. We propose a novel robust training framework which 1) employs simple but effective methods to directly simulate natural OCR noises from clean texts and 2) iteratively mines the hard examples from a large number of simulated samples for optimal performance. 3) To make our model learn noise-invariant representations, a stability loss is employed. Experiments on three real-world datasets show that the proposed framework boosts the robustness of pre-trained models by a large margin. We believe that this work can greatly promote the application of NLP models in actual scenarios, although the algorithm we use is simple and straightforward. We make our codes and three datasets publicly available\footnote{https://github.com/tal-ai/Robust-learning-MSSHEM}.
Neural Multi-Task Learning for Teacher Question Detection in Online Classrooms
May 16, 2020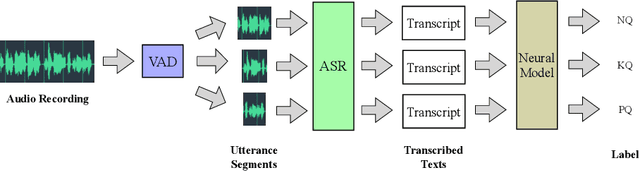

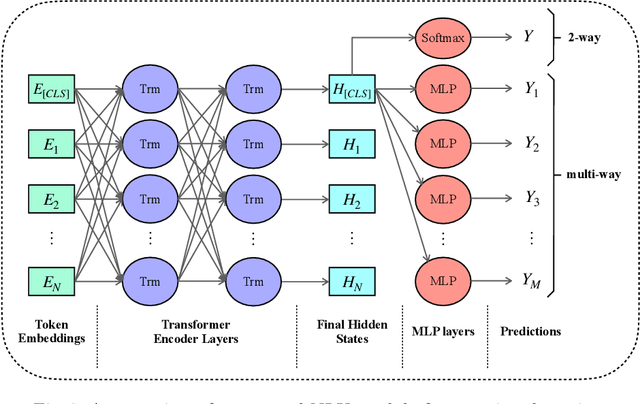
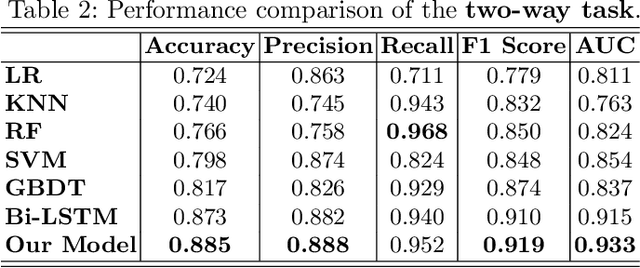
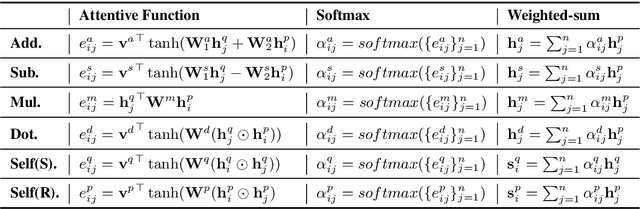
Asking questions is one of the most crucial pedagogical techniques used by teachers in class. It not only offers open-ended discussions between teachers and students to exchange ideas but also provokes deeper student thought and critical analysis. Providing teachers with such pedagogical feedback will remarkably help teachers improve their overall teaching quality over time in classrooms. Therefore, in this work, we build an end-to-end neural framework that automatically detects questions from teachers' audio recordings. Compared with traditional methods, our approach not only avoids cumbersome feature engineering, but also adapts to the task of multi-class question detection in real education scenarios. By incorporating multi-task learning techniques, we are able to strengthen the understanding of semantic relations among different types of questions. We conducted extensive experiments on the question detection tasks in a real-world online classroom dataset and the results demonstrate the superiority of our model in terms of various evaluation metrics.
Dolphin: A Verbal Fluency Evaluation System for Elementary Education
Aug 04, 2019


Verbal fluency is critically important for children growth and personal development \cite{cohen1999verbal,berninger1992gender}. Due to the limited and imbalanced educational resource in China, elementary students barely have chances to improve their oral language skills in classes. Verbal fluency tasks (VFTs) were invented to let the students practice their oral language skills after school. VFTs are simple but concrete math related questions that ask students to not only report answers but speak out the entire thinking process. In spite of the great success of VFTs, they bring a heavy grading burden to elementary teachers. To alleviate this problem, we develop Dolphin, a verbal fluency evaluation system for Chinese elementary education. Dolphin is able to automatically evaluate both phonological fluency and semantic relevance of students' answers of their VFT assignments. We conduct a wide range of offline and online experiments to demonstrate the effectiveness of Dolphin. In our offline experiments, we show that Dolphin improves both phonological fluency and semantic relevance evaluation performance when compared to state-of-the-art baselines on real-world educational data sets. In our online A/B experiments, we test Dolphin with 183 teachers from 2 major cities (Hangzhou and Xi'an) in China for 10 weeks and the results show that VFT assignments grading coverage is improved by 22\%. To encourage the reproducible results, we make our code public on an anonymous git repo: \url{https://tinyurl.com/y52tzcw7}.