 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Learning from Limited Educational Data with Crowdsourced Labels
Sep 23, 2020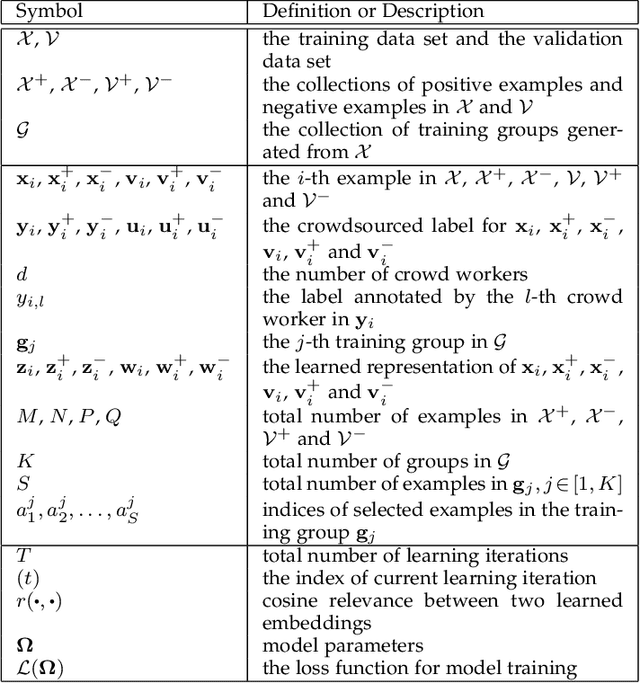
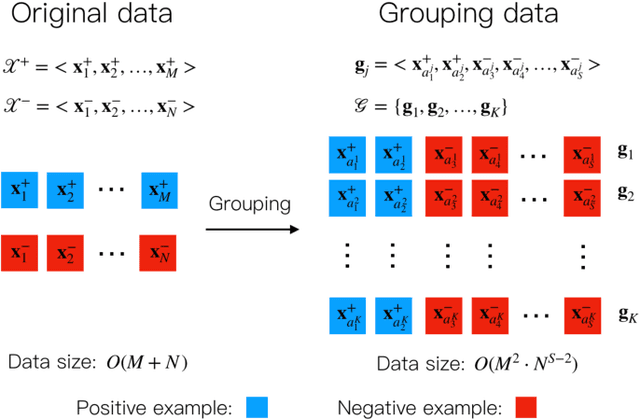
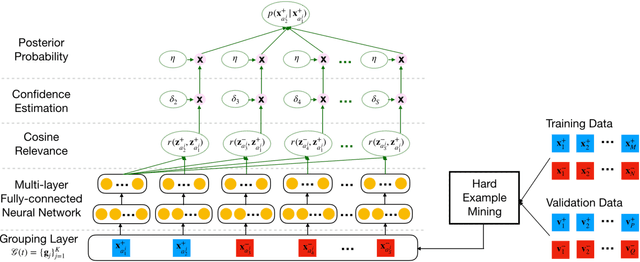
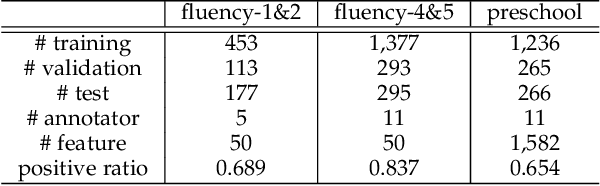
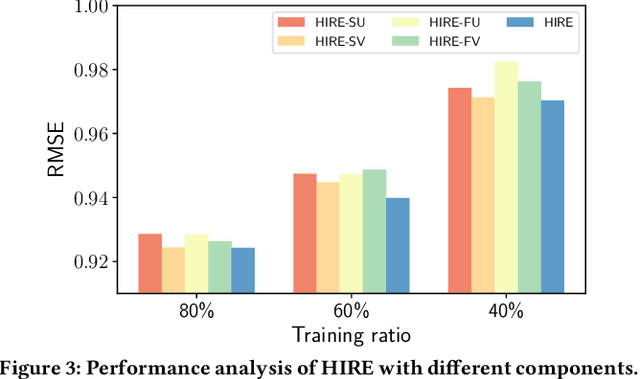
Representation learning has been proven to play an important role in the unprecedented success of machine learning models in numerous tasks, such as machine translation, face recognition and recommendation. The majority of existing representation learning approaches often require a large number of consistent and noise-free labels. However, due to various reasons such as budget constraints and privacy concerns, labels are very limited in many real-world scenarios. Directly applying standard representation learning approaches on small labeled data sets will easily run into over-fitting problems and lead to sub-optimal solutions. Even worse, in some domains such as education, the limited labels are usually annotated by multiple workers with diverse expertise, which yields noises and inconsistency in such crowdsourcing settings. In this paper, we propose a novel framework which aims to learn effective representations from limited data with crowdsourced labels. Specifically, we design a grouping based deep neural network to learn embeddings from a limited number of training samples and present a Bayesian confidence estimator to capture the inconsistency among crowdsourced labels. Furthermore, to expedite the training process, we develop a hard example selection procedure to adaptively pick up training examples that are misclassified by the model. Extensive experiments conducted on three real-world data sets demonstrate the superiority of our framework on learning representations from limited data with crowdsourced labels, comparing with various state-of-the-art baselines. In addition, we provide a comprehensive analysis on each of the main components of our proposed framework and also introduce the promising results it achieved in our real production to fully understand the proposed framework.
Neural Multi-Task Learning for Teacher Question Detection in Online Classrooms
May 16, 2020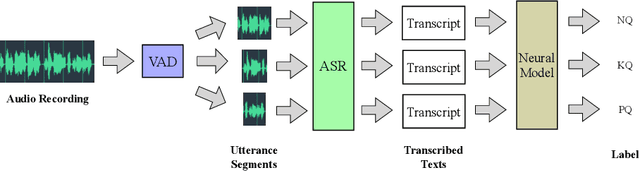

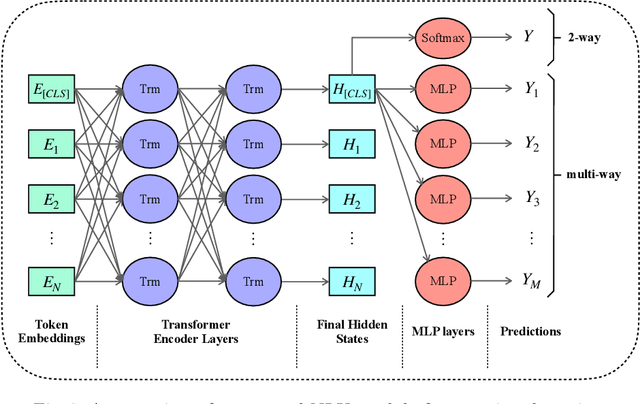
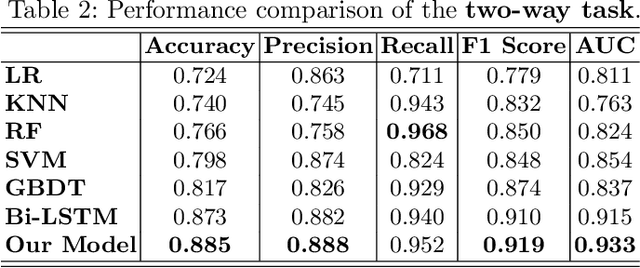
Asking questions is one of the most crucial pedagogical techniques used by teachers in class. It not only offers open-ended discussions between teachers and students to exchange ideas but also provokes deeper student thought and critical analysis. Providing teachers with such pedagogical feedback will remarkably help teachers improve their overall teaching quality over time in classrooms. Therefore, in this work, we build an end-to-end neural framework that automatically detects questions from teachers' audio recordings. Compared with traditional methods, our approach not only avoids cumbersome feature engineering, but also adapts to the task of multi-class question detection in real education scenarios. By incorporating multi-task learning techniques, we are able to strengthen the understanding of semantic relations among different types of questions. We conducted extensive experiments on the question detection tasks in a real-world online classroom dataset and the results demonstrate the superiority of our model in terms of various evaluation metrics.
Learning Multi-level Dependencies for Robust Word Recognition
Nov 22, 2019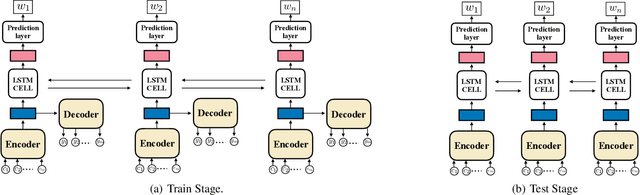

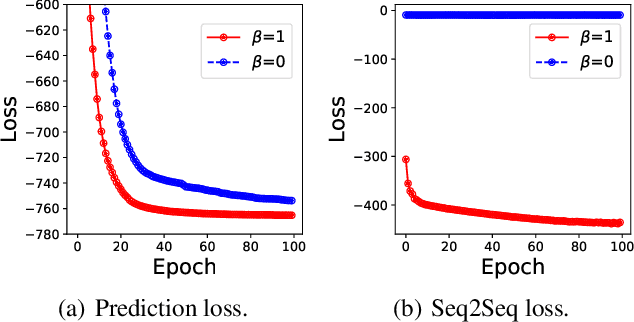
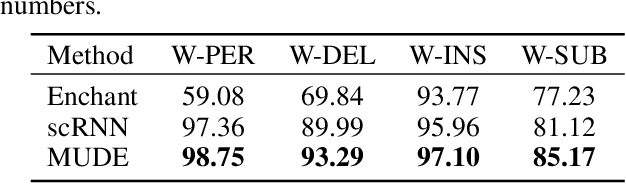
Robust language processing systems are becoming increasingly important given the recent awareness of dangerous situations where brittle machine learning models can be easily broken with the presence of noises. In this paper, we introduce a robust word recognition framework that captures multi-level sequential dependencies in noised sentences. The proposed framework employs a sequence-to-sequence model over characters of each word, whose output is given to a word-level bi-directional recurrent neural network. We conduct extensive experiments to verify the effectiveness of the framework. The results show that the proposed framework outperforms state-of-the-art methods by a large margin and they also suggest that character-level dependencies can play an important role in word recognition.
Multimodal Learning For Classroom Activity Detection
Oct 22, 2019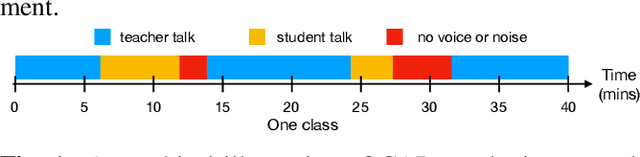
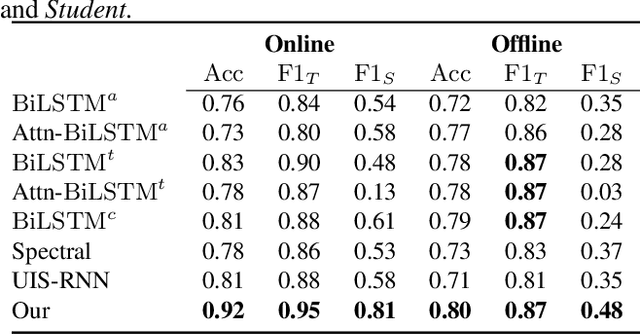
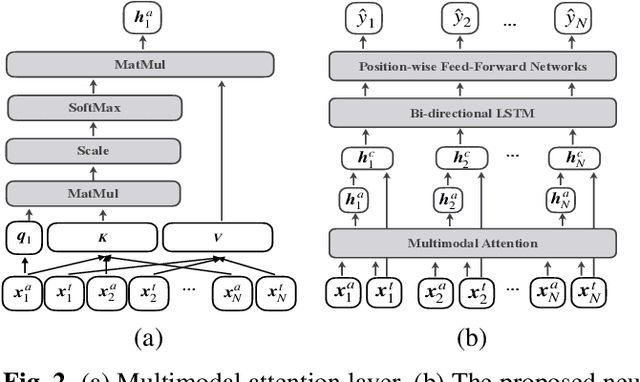
Classroom activity detection (CAD) focuses on accurately classifying whether the teacher or student is speaking and recording both the length of individual utterances during a class. A CAD solution helps teachers get instant feedback on their pedagogical instructions. This greatly improves educators' teaching skills and hence leads to students' achievement. However, CAD is very challenging because (1) the CAD model needs to be generalized well enough for different teachers and students; (2) data from both vocal and language modalities has to be wisely fused so that they can be complementary; and (3) the solution shouldn't heavily rely on additional recording device. In this paper, we address the above challenges by using a novel attention based neural framework. Our framework not only extracts both speech and language information, but utilizes attention mechanism to capture long-term semantic dependence. Our framework is device-free and is able to take any classroom recording as input. The proposed CAD learning framework is evaluated in two real-world education applications. The experimental results demonstrate the benefits of our approach on learning attention based neural network from classroom data with different modalities, and show our approach is able to outperform state-of-the-art baselines in terms of various evaluation metrics.
Automatic Short Answer Grading via Multiway Attention Networks
Sep 23, 2019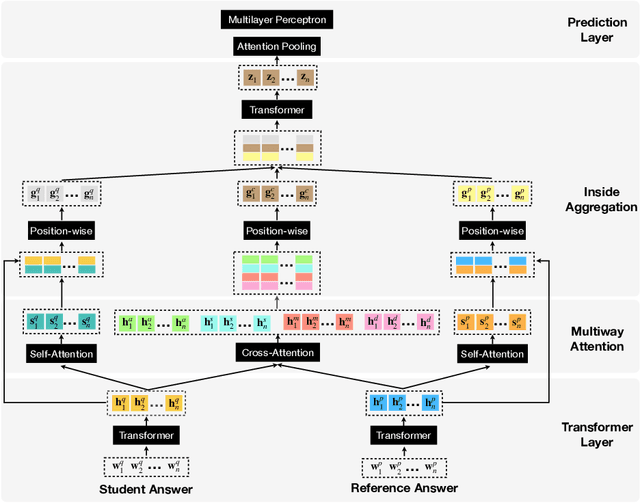

Automatic short answer grading (ASAG), which autonomously score student answers according to reference answers, provides a cost-effective and consistent approach to teaching professionals and can reduce their monotonous and tedious grading workloads. However, ASAG is a very challenging task due to two reasons: (1) student answers are made up of free text which requires a deep semantic understanding; and (2) the questions are usually open-ended and across many domains in K-12 scenarios. In this paper, we propose a generalized end-to-end ASAG learning framework which aims to (1) autonomously extract linguistic information from both student and reference answers; and (2) accurately model the semantic relations between free-text student and reference answers in open-ended domain. The proposed ASAG model is evaluated on a large real-world K-12 dataset and can outperform the state-of-the-art baselines in terms of various evaluation metrics.
A Multimodal Alerting System for Online Class Quality Assurance
Sep 01, 2019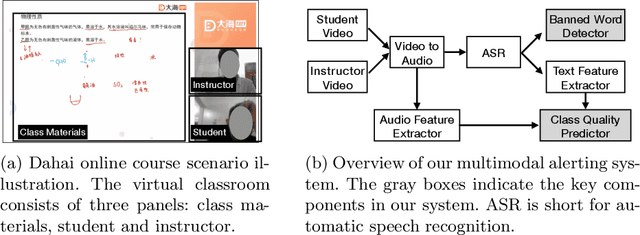

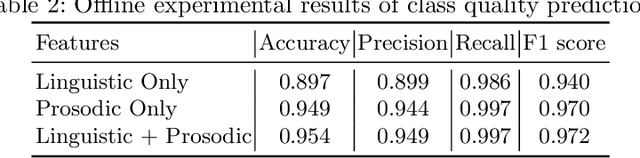
Online 1 on 1 class is created for more personalized learning experience. It demands a large number of teaching resources, which are scarce in China. To alleviate this problem, we build a platform (marketplace), i.e., \emph{Dahai} to allow college students from top Chinese universities to register as part-time instructors for the online 1 on 1 classes. To warn the unqualified instructors and ensure the overall education quality, we build a monitoring and alerting system by utilizing multimodal information from the online environment. Our system mainly consists of two key components: banned word detector and class quality predictor. The system performance is demonstrated both offline and online. By conducting experimental evaluation of real-world online courses, we are able to achieve 74.3\% alerting accuracy in our production environment.
Deep Knowledge Tracing with Side Information
Sep 01, 2019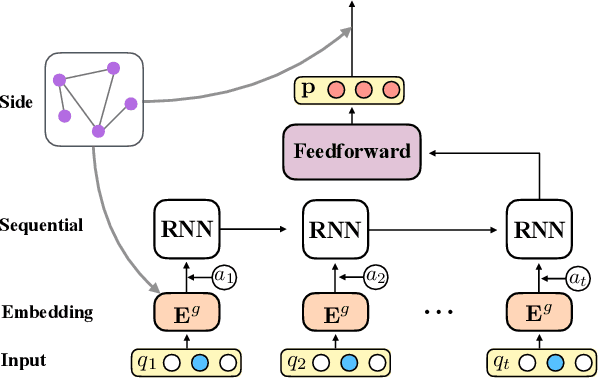
Monitoring student knowledge states or skill acquisition levels known as knowledge tracing, is a fundamental part of intelligent tutoring systems. Despite its inherent challenges, recent deep neural networks based knowledge tracing models have achieved great success, which is largely from models' ability to learn sequential dependencies of questions in student exercise data. However, in addition to sequential information, questions inherently exhibit side relations, which can enrich our understandings about student knowledge states and has great potentials to advance knowledge tracing. Thus, in this paper, we exploit side relations to improve knowledge tracing and design a novel framework DTKS. The experimental results on real education data validate the effectiveness of the proposed framework and demonstrate the importance of side information in knowledge tracing.
Dolphin: A Verbal Fluency Evaluation System for Elementary Education
Aug 04, 2019


Verbal fluency is critically important for children growth and personal development \cite{cohen1999verbal,berninger1992gender}. Due to the limited and imbalanced educational resource in China, elementary students barely have chances to improve their oral language skills in classes. Verbal fluency tasks (VFTs) were invented to let the students practice their oral language skills after school. VFTs are simple but concrete math related questions that ask students to not only report answers but speak out the entire thinking process. In spite of the great success of VFTs, they bring a heavy grading burden to elementary teachers. To alleviate this problem, we develop Dolphin, a verbal fluency evaluation system for Chinese elementary education. Dolphin is able to automatically evaluate both phonological fluency and semantic relevance of students' answers of their VFT assignments. We conduct a wide range of offline and online experiments to demonstrate the effectiveness of Dolphin. In our offline experiments, we show that Dolphin improves both phonological fluency and semantic relevance evaluation performance when compared to state-of-the-art baselines on real-world educational data sets. In our online A/B experiments, we test Dolphin with 183 teachers from 2 major cities (Hangzhou and Xi'an) in China for 10 weeks and the results show that VFT assignments grading coverage is improved by 22\%. To encourage the reproducible results, we make our code public on an anonymous git repo: \url{https://tinyurl.com/y52tzcw7}.
Recommender Systems with Heterogeneous Side Information
Jul 18, 2019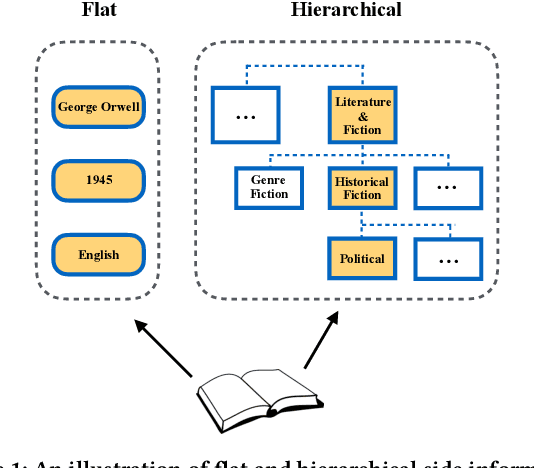
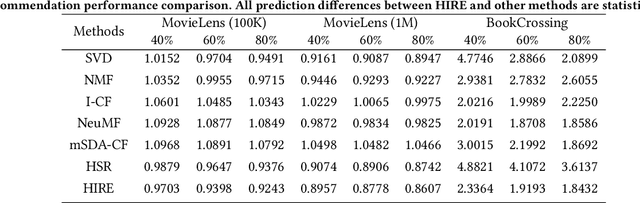
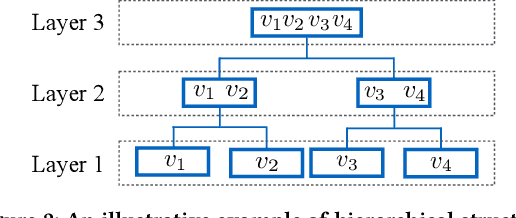
In modern recommender systems, both users and items are associated with rich side information, which can help understand users and items. Such information is typically heterogeneous and can be roughly categorized into flat and hierarchical side information. While side information has been proved to be valuable, the majority of existing systems have exploited either only flat side information or only hierarchical side information due to the challenges brought by the heterogeneity. In this paper, we investigate the problem of exploiting heterogeneous side information for recommendations. Specifically, we propose a novel framework jointly captures flat and hierarchical side information with mathematical coherence. We demonstrate the effectiveness of the proposed framework via extensive experiments on various real-world datasets. Empirical results show that our approach is able to lead a significant performance gain over the state-of-the-art methods.
Learning Effective Embeddings From Crowdsourced Labels: An Educational Case Study
Jul 18, 2019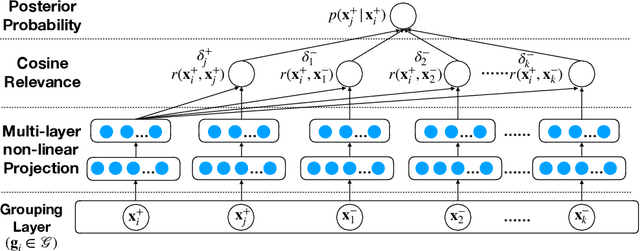
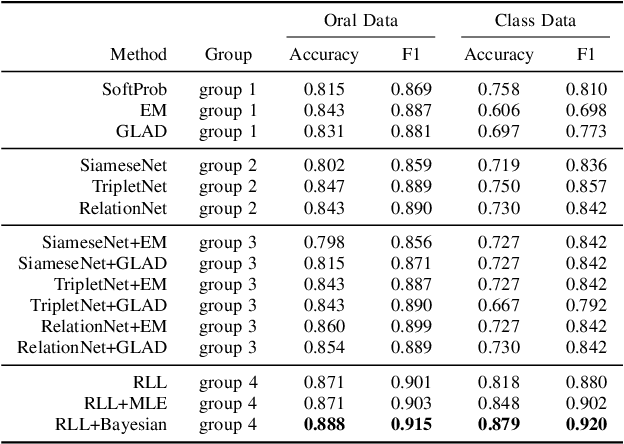
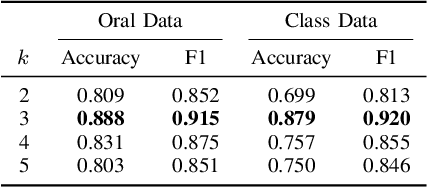
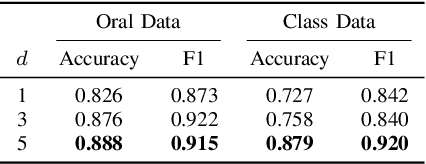
Learning representation has been proven to be helpful in numerous machine learning tasks. The success of the majority of existing representation learning approaches often requires a large amount of consistent and noise-free labels. However, labels are not accessible in many real-world scenarios and they are usually annotated by the crowds. In practice, the crowdsourced labels are usually inconsistent among crowd workers given their diverse expertise and the number of crowdsourced labels is very limited. Thus, directly adopting crowdsourced labels for existing representation learning algorithms is inappropriate and suboptimal. In this paper, we investigate the above problem and propose a novel framework of \textbf{R}epresentation \textbf{L}earning with crowdsourced \textbf{L}abels, i.e., "RLL", which learns representation of data with crowdsourced labels by jointly and coherently solving the challenges introduced by limited and inconsistent labels. The proposed representation learning framework is evaluated in two real-world education applications. The experimental results demonstrate the benefits of our approach on learning representation from limited labeled data from the crowds, and show RLL is able to outperform state-of-the-art baselines. Moreover, detailed experiments are conducted on RLL to fully understand its key components and the corresponding performance.