 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Effective Embeddings From Crowdsourced Labels: An Educational Case Study
Paper and Code
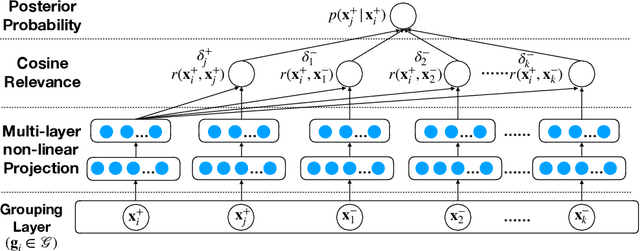
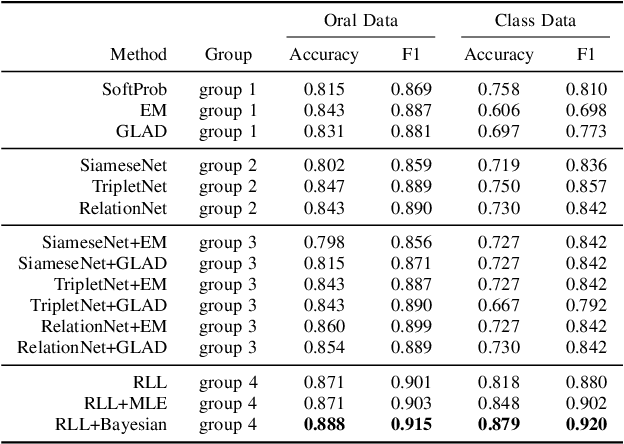
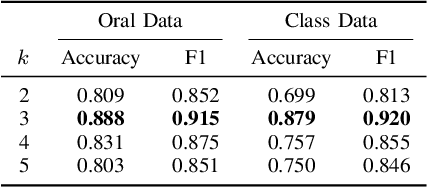
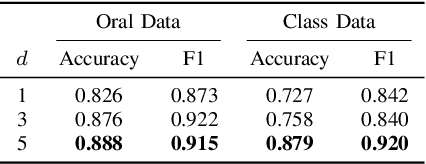
Learning representation has been proven to be helpful in numerous machine learning tasks. The success of the majority of existing representation learning approaches often requires a large amount of consistent and noise-free labels. However, labels are not accessible in many real-world scenarios and they are usually annotated by the crowds. In practice, the crowdsourced labels are usually inconsistent among crowd workers given their diverse expertise and the number of crowdsourced labels is very limited. Thus, directly adopting crowdsourced labels for existing representation learning algorithms is inappropriate and suboptimal. In this paper, we investigate the above problem and propose a novel framework of \textbf{R}epresentation \textbf{L}earning with crowdsourced \textbf{L}abels, i.e., "RLL", which learns representation of data with crowdsourced labels by jointly and coherently solving the challenges introduced by limited and inconsistent labels. The proposed representation learning framework is evaluated in two real-world education applications. The experimental results demonstrate the benefits of our approach on learning representation from limited labeled data from the crowds, and show RLL is able to outperform state-of-the-art baselines. Moreover, detailed experiments are conducted on RLL to fully understand its key components and the corresponding performance.