 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Multi-Task Learning for Teacher Question Detection in Online Classrooms
May 16, 2020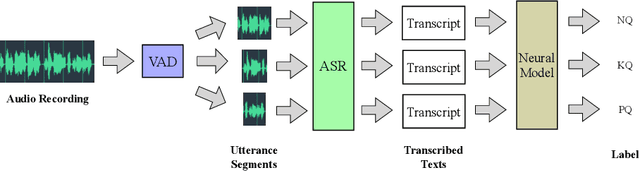

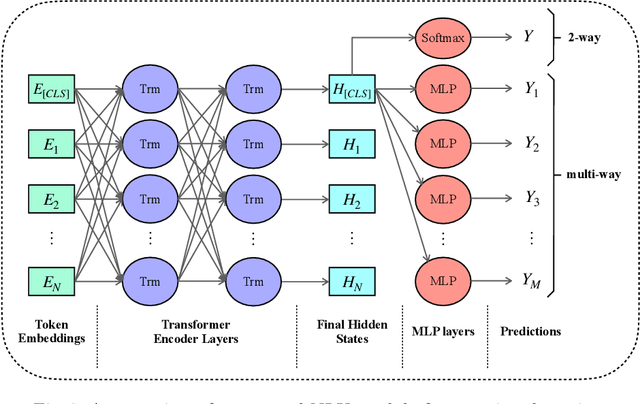
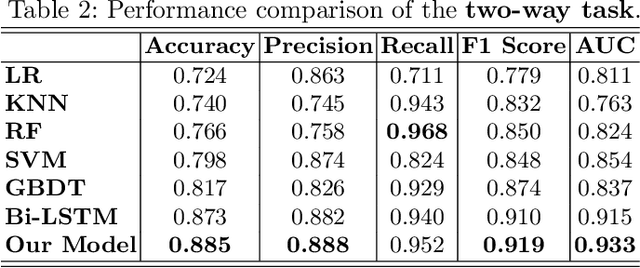
Asking questions is one of the most crucial pedagogical techniques used by teachers in class. It not only offers open-ended discussions between teachers and students to exchange ideas but also provokes deeper student thought and critical analysis. Providing teachers with such pedagogical feedback will remarkably help teachers improve their overall teaching quality over time in classrooms. Therefore, in this work, we build an end-to-end neural framework that automatically detects questions from teachers' audio recordings. Compared with traditional methods, our approach not only avoids cumbersome feature engineering, but also adapts to the task of multi-class question detection in real education scenarios. By incorporating multi-task learning techniques, we are able to strengthen the understanding of semantic relations among different types of questions. We conducted extensive experiments on the question detection tasks in a real-world online classroom dataset and the results demonstrate the superiority of our model in terms of various evaluation metrics.
TAL EmotioNet Challenge 2020 Rethinking the Model Chosen Problem in Multi-Task Learning
Apr 21, 2020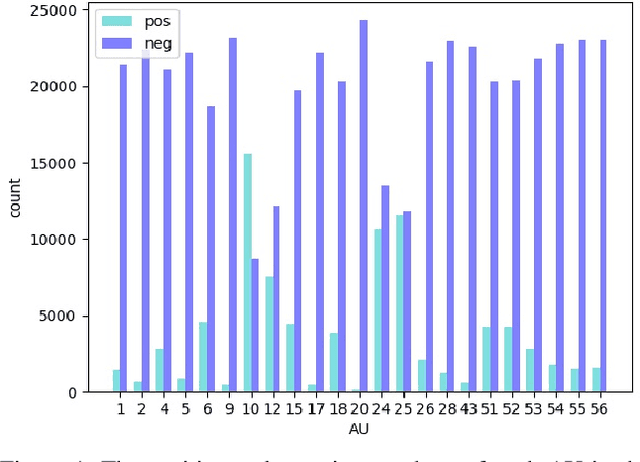
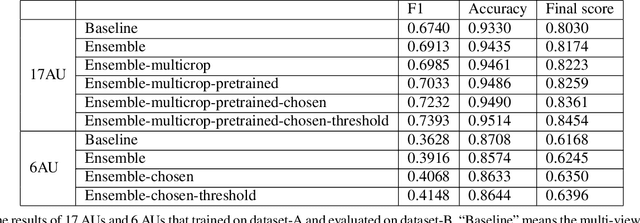
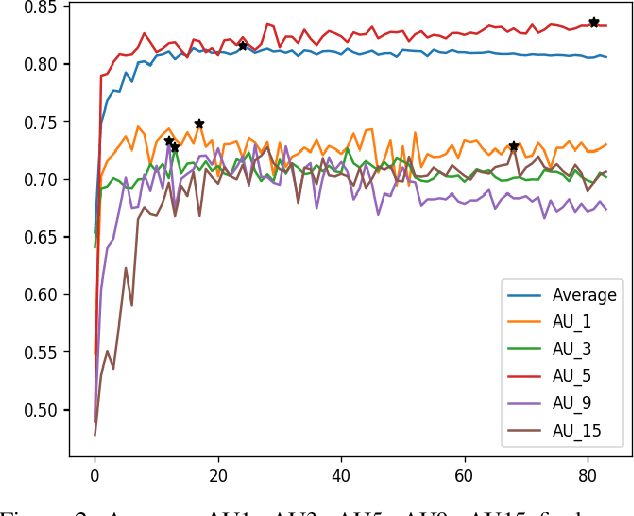

This paper introduces our approach to the EmotioNet Challenge 2020. We pose the AU recognition problem as a multi-task learning problem, where the non-rigid facial muscle motion (mainly the first 17 AUs) and the rigid head motion (the last 6 AUs) are modeled separately. The co-occurrence of the expression features and the head pose features are explored. We observe that different AUs converge at various speed. By choosing the optimal checkpoint for each AU, the recognition results are improved. We are able to obtain a final score of 0.746 in validation set and 0.7306 in the test set of the challenge.
Identifying At-Risk K-12 Students in Multimodal Online Environments: A Machine Learning Approach
Mar 21, 2020



With the rapid emergence of K-12 online learning platforms, a new era of education has been opened up. By offering more affordable and personalized courses compared to in-person classrooms, K-12 online tutoring is pushing the boundaries of education to the general public. It is crucial to have a dropout warning framework to preemptively identify K-12 students who are at risk of dropping out of the online courses. Prior researchers have focused on predicting dropout in Massive Open Online Courses (MOOCs), which often deliver higher education, i.e., graduate level courses at top institutions. However, few studies have focused on developing a machine learning approach for students in K-12 online courses. The dropout prediction scenarios are significantly different between MOOC based learning and K-12 online tutoring in many aspects such as environmental modalities, learning goals, online behaviors, etc. In this paper, we develop a machine learning framework to conduct accurate at-risk student identification specialized in K-12 multimodal online environments. Our approach considers both online and offline factors around K-12 students and aims at solving the challenging problems of (1) multiple modalities, i.e., K-12 online environments involve interactions from different modalities such as video, voice, etc; (2) length variability, i.e., students with different lengths of learning history; (3) time sensitivity, i.e., the dropout likelihood is changing with time; and (4) data imbalance, i.e., only less than 20\% of K-12 students will choose to drop out the class. We conduct a wide range of offline and online experiments to demonstrate the effectiveness of our approach. In our offline experiments, we show that our method improves the dropout prediction performance when compared to state-of-the-art baselines on a real-world educational data set.
Learning Multi-level Dependencies for Robust Word Recognition
Nov 22, 2019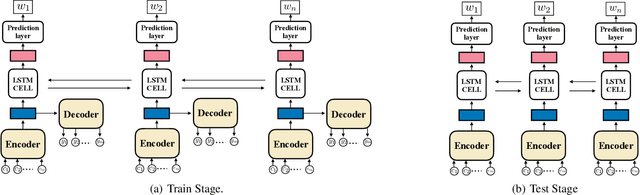

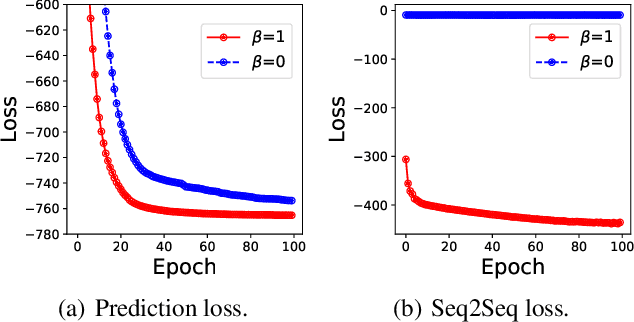
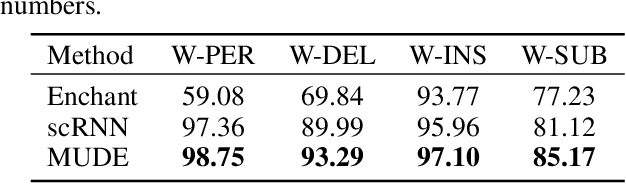
Robust language processing systems are becoming increasingly important given the recent awareness of dangerous situations where brittle machine learning models can be easily broken with the presence of noises. In this paper, we introduce a robust word recognition framework that captures multi-level sequential dependencies in noised sentences. The proposed framework employs a sequence-to-sequence model over characters of each word, whose output is given to a word-level bi-directional recurrent neural network. We conduct extensive experiments to verify the effectiveness of the framework. The results show that the proposed framework outperforms state-of-the-art methods by a large margin and they also suggest that character-level dependencies can play an important role in word recognition.
Multimodal Learning For Classroom Activity Detection
Oct 22, 2019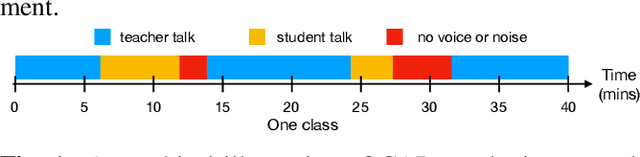
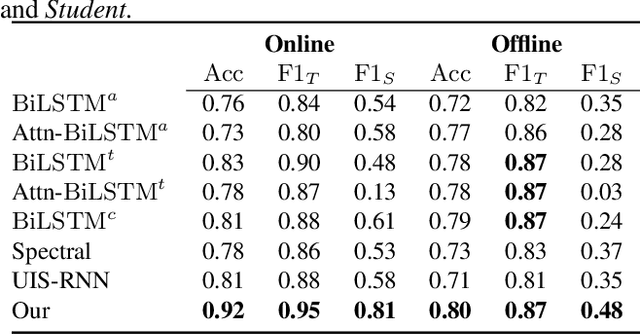
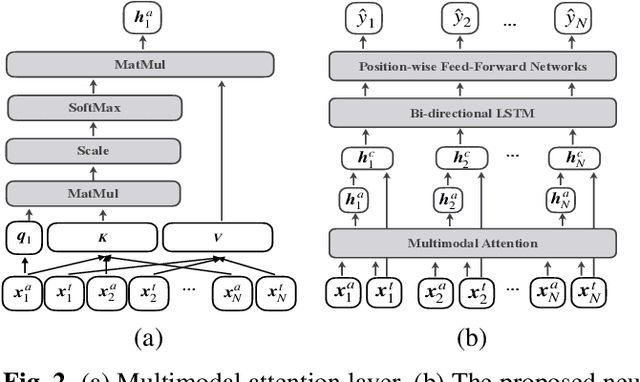
Classroom activity detection (CAD) focuses on accurately classifying whether the teacher or student is speaking and recording both the length of individual utterances during a class. A CAD solution helps teachers get instant feedback on their pedagogical instructions. This greatly improves educators' teaching skills and hence leads to students' achievement. However, CAD is very challenging because (1) the CAD model needs to be generalized well enough for different teachers and students; (2) data from both vocal and language modalities has to be wisely fused so that they can be complementary; and (3) the solution shouldn't heavily rely on additional recording device. In this paper, we address the above challenges by using a novel attention based neural framework. Our framework not only extracts both speech and language information, but utilizes attention mechanism to capture long-term semantic dependence. Our framework is device-free and is able to take any classroom recording as input. The proposed CAD learning framework is evaluated in two real-world education applications. The experimental results demonstrate the benefits of our approach on learning attention based neural network from classroom data with different modalities, and show our approach is able to outperform state-of-the-art baselines in terms of various evaluation metrics.
Recommender Systems with Heterogeneous Side Information
Jul 18, 2019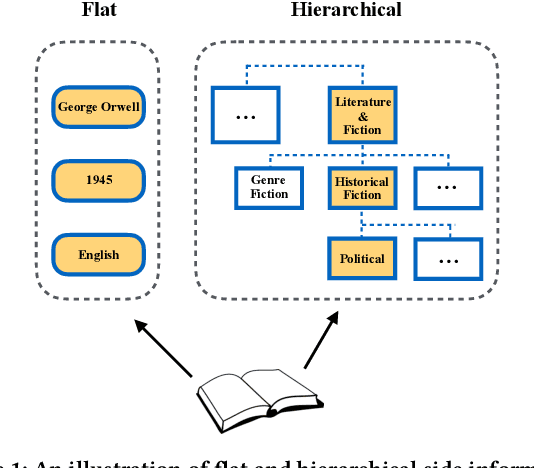
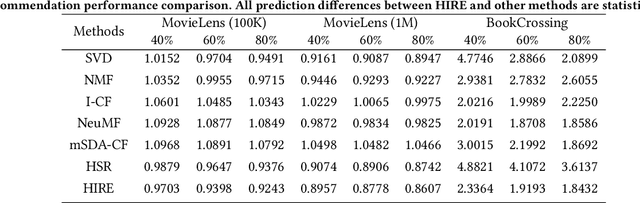
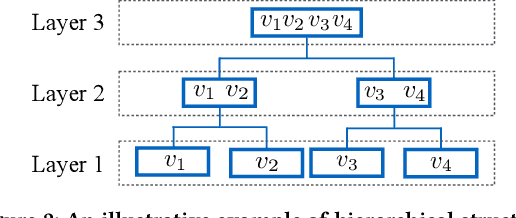
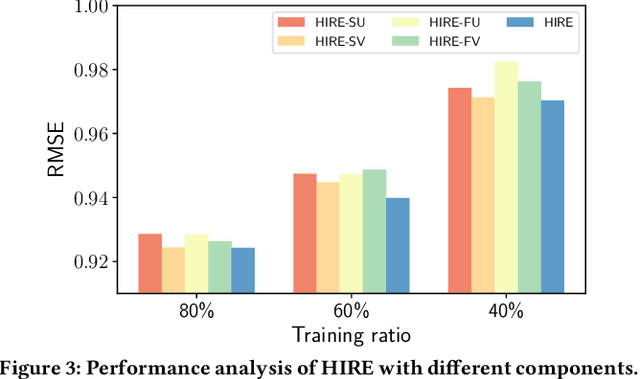
In modern recommender systems, both users and items are associated with rich side information, which can help understand users and items. Such information is typically heterogeneous and can be roughly categorized into flat and hierarchical side information. While side information has been proved to be valuable, the majority of existing systems have exploited either only flat side information or only hierarchical side information due to the challenges brought by the heterogeneity. In this paper, we investigate the problem of exploiting heterogeneous side information for recommendations. Specifically, we propose a novel framework jointly captures flat and hierarchical side information with mathematical coherence. We demonstrate the effectiveness of the proposed framework via extensive experiments on various real-world datasets. Empirical results show that our approach is able to lead a significant performance gain over the state-of-the-art methods.
Learning Effective Embeddings From Crowdsourced Labels: An Educational Case Study
Jul 18, 2019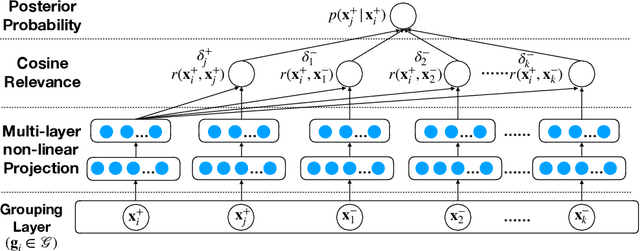
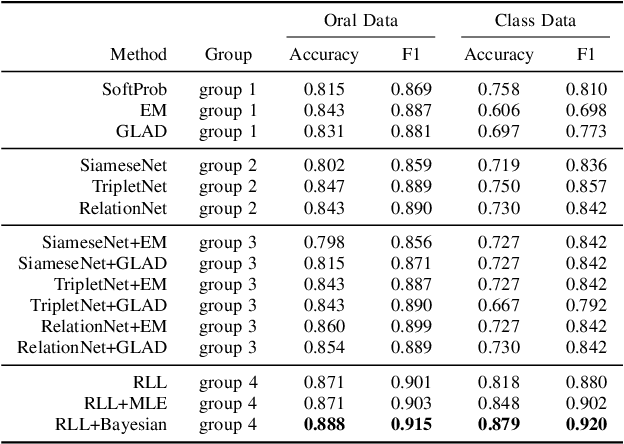
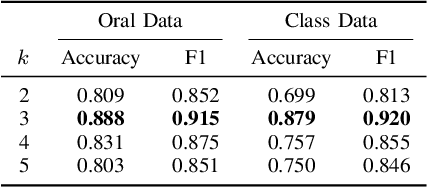
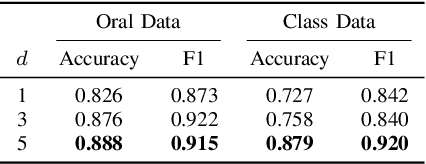
Learning representation has been proven to be helpful in numerous machine learning tasks. The success of the majority of existing representation learning approaches often requires a large amount of consistent and noise-free labels. However, labels are not accessible in many real-world scenarios and they are usually annotated by the crowds. In practice, the crowdsourced labels are usually inconsistent among crowd workers given their diverse expertise and the number of crowdsourced labels is very limited. Thus, directly adopting crowdsourced labels for existing representation learning algorithms is inappropriate and suboptimal. In this paper, we investigate the above problem and propose a novel framework of \textbf{R}epresentation \textbf{L}earning with crowdsourced \textbf{L}abels, i.e., "RLL", which learns representation of data with crowdsourced labels by jointly and coherently solving the challenges introduced by limited and inconsistent labels. The proposed representation learning framework is evaluated in two real-world education applications. The experimental results demonstrate the benefits of our approach on learning representation from limited labeled data from the crowds, and show RLL is able to outperform state-of-the-art baselines. Moreover, detailed experiments are conducted on RLL to fully understand its key components and the corresponding performance.
Multi-scale recognition with DAG-CNNs
May 20, 2015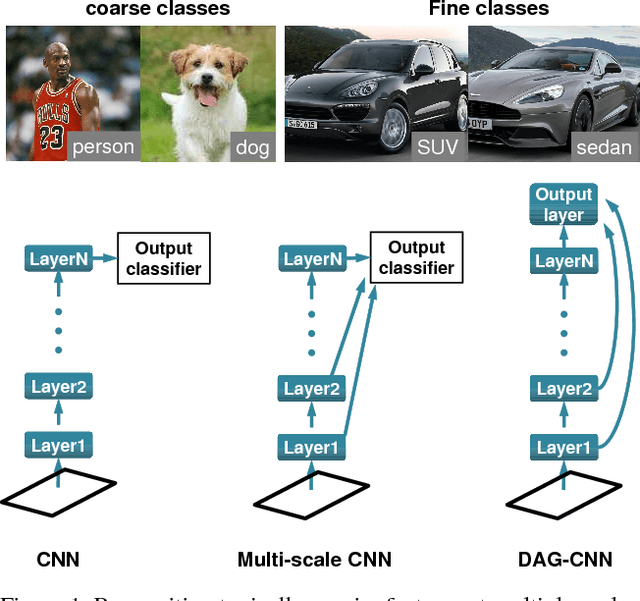
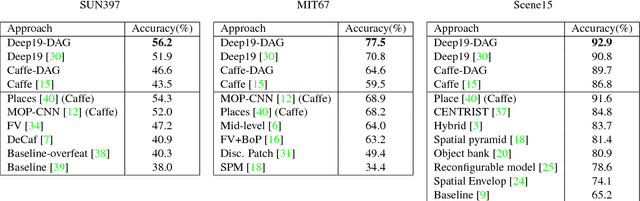

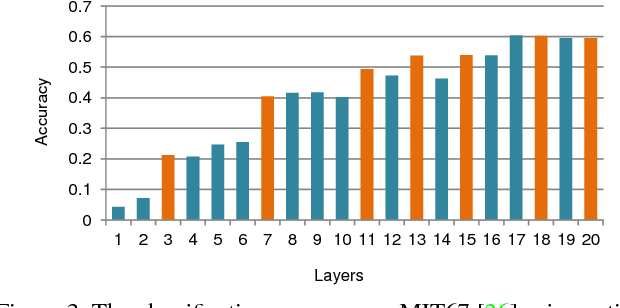
We explore multi-scale convolutional neural nets (CNNs) for image classification. Contemporary approaches extract features from a single output layer. By extracting features from multiple layers, one can simultaneously reason about high, mid, and low-level features during classification. The resulting multi-scale architecture can itself be seen as a feed-forward model that is structured as a directed acyclic graph (DAG-CNNs). We use DAG-CNNs to learn a set of multiscale features that can be effectively shared between coarse and fine-grained classification tasks. While fine-tuning such models helps performance, we show that even "off-the-self" multiscale features perform quite well. We present extensive analysis and demonstrate state-of-the-art classification performance on three standard scene benchmarks (SUN397, MIT67, and Scene15). In terms of the heavily benchmarked MIT67 and Scene15 datasets, our results reduce the lowest previously-reported error by 23.9% and 9.5%, respectively.