 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Flow-Based Gradual Domain Adaption: A Semi-Dual Optimal Transport Perspective
Feb 01, 2026Gradual domain adaptation (GDA) aims to mitigate domain shift by progressively adapting models from the source domain to the target domain via intermediate domains. However, real intermediate domains are often unavailable or ineffective, necessitating the synthesis of intermediate samples. Flow-based models have recently been used for this purpose by interpolating between source and target distributions; however, their training typically relies on sample-based log-likelihood estimation, which can discard useful information and thus degrade GDA performance. The key to addressing this limitation is constructing the intermediate domains via samples directly. To this end, we propose an Entropy-regularized Semi-dual Unbalanced Optimal Transport (E-SUOT) framework to construct intermediate domains. Specifically, we reformulate flow-based GDA as a Lagrangian dual problem and derive an equivalent semi-dual objective that circumvents the need for likelihood estimation. However, the dual problem leads to an unstable min-max training procedure. To alleviate this issue, we further introduce entropy regularization to convert it into a more stable alternative optimization procedure. Based on this, we propose a novel GDA training framework and provide theoretical analysis in terms of stability and generalization. Finally, extensive experiments are conducted to demonstrate the efficacy of the E-SUOT framework.
Advancing Math Reasoning in Language Models: The Impact of Problem-Solving Data, Data Synthesis Methods, and Training Stages
Jan 23, 2025Advancements in LLMs have significantly expanded their capabilities across various domains. However, mathematical reasoning remains a challenging area, prompting the development of math-specific LLMs. These models typically follow a two-stage training paradigm: pre-training with math-related corpora and post-training with problem datasets for SFT. Despite these efforts, the improvements in mathematical reasoning achieved through continued pre-training (CPT) are often less significant compared to those obtained via SFT. This study addresses this discrepancy by exploring alternative strategies during the pre-training phase, focusing on the use of problem-solving data over general mathematical corpora. We investigate three primary research questions: (1) Can problem-solving data enhance the model's mathematical reasoning capabilities more effectively than general mathematical corpora during CPT? (2) Are synthetic data from the same source equally effective, and which synthesis methods are most efficient? (3) How do the capabilities developed from the same problem-solving data differ between the CPT and SFT stages, and what factors contribute to these differences? Our findings indicate that problem-solving data significantly enhances the model's mathematical capabilities compared to general mathematical corpora. We also identify effective data synthesis methods, demonstrating that the tutorship amplification synthesis method achieves the best performance. Furthermore, while SFT facilitates instruction-following abilities, it underperforms compared to CPT with the same data, which can be partially attributed to its poor learning capacity for hard multi-step problem-solving data. These insights provide valuable guidance for optimizing the mathematical reasoning capabilities of LLMs, culminating in our development of a powerful mathematical base model called JiuZhang-8B.
What Are Step-Level Reward Models Rewarding? Counterintuitive Findings from MCTS-Boosted Mathematical Reasoning
Dec 20, 2024Step-level reward models (SRMs) can significantly enhance mathematical reasoning performance through process supervision or step-level preference alignment based on reinforcement learning. The performance of SRMs is pivotal, as they serve as critical guidelines, ensuring that each step in the reasoning process is aligned with desired outcomes. Recently, AlphaZero-like methods, where Monte Carlo Tree Search (MCTS) is employed for automatic step-level preference annotation, have proven particularly effective. However, the precise mechanisms behind the success of SRMs remain largely unexplored. To address this gap, this study delves into the counterintuitive aspects of SRMs, particularly focusing on MCTS-based approaches. Our findings reveal that the removal of natural language descriptions of thought processes has minimal impact on the efficacy of SRMs. Furthermore, we demonstrate that SRMs are adept at assessing the complex logical coherence present in mathematical language while having difficulty in natural language. These insights provide a nuanced understanding of the core elements that drive effective step-level reward modeling in mathematical reasoning. By shedding light on these mechanisms, this study offers valuable guidance for developing more efficient and streamlined SRMs, which can be achieved by focusing on the crucial parts of mathematical reasoning.
Expediting and Elevating Large Language Model Reasoning via Hidden Chain-of-Thought Decoding
Sep 13, 2024Large language models (LLMs) have demonstrated remarkable capabilities in tasks requiring reasoning and multi-step problem-solving through the use of chain-of-thought (CoT) prompting. However, generating the full CoT process results in significantly longer output sequences, leading to increased computational costs and latency during inference. To address this challenge, we propose a novel approach to compress the CoT process through semantic alignment, enabling more efficient decoding while preserving the benefits of CoT reasoning. Our method introduces an auxiliary CoT model that learns to generate and compress the full thought process into a compact special token representation semantically aligned with the original CoT output. This compressed representation is then integrated into the input of the Hidden Chain-of-Thought (HCoT) model. The training process follows a two-stage procedure: First, the CoT model is optimized to generate the compressed token representations aligned with the ground-truth CoT outputs using a contrastive loss. Subsequently, with the CoT model parameters frozen, the HCoT model is fine-tuned to generate accurate subsequent predictions conditioned on the prefix instruction and the compressed CoT representations from the CoT model. Extensive experiments across three challenging domains - mathematical reasoning, agent invocation, and question answering - demonstrate that our semantic compression approach achieves competitive or improved performance compared to the full CoT baseline, while providing significant speedups of at least 1.5x in decoding time. Moreover, incorporating contrastive learning objectives further enhances the quality of the compressed representations, leading to better CoT prompting and improved task accuracy. Our work paves the way for more efficient exploitation of multi-step reasoning capabilities in LLMs across a wide range of applications.
Hypertext Entity Extraction in Webpage
Mar 04, 2024



Webpage entity extraction is a fundamental natural language processing task in both research and applications. Nowadays, the majority of webpage entity extraction models are trained on structured datasets which strive to retain textual content and its structure information. However, existing datasets all overlook the rich hypertext features (e.g., font color, font size) which show their effectiveness in previous works. To this end, we first collect a \textbf{H}ypertext \textbf{E}ntity \textbf{E}xtraction \textbf{D}ataset (\textit{HEED}) from the e-commerce domains, scraping both the text and the corresponding explicit hypertext features with high-quality manual entity annotations. Furthermore, we present the \textbf{Mo}E-based \textbf{E}ntity \textbf{E}xtraction \textbf{F}ramework (\textit{MoEEF}), which efficiently integrates multiple features to enhance model performance by Mixture of Experts and outperforms strong baselines, including the state-of-the-art small-scale models and GPT-3.5-turbo. Moreover, the effectiveness of hypertext features in \textit{HEED} and several model components in \textit{MoEEF} are analyzed.
Optimal Transport for Treatment Effect Estimation
Oct 27, 2023Estimating conditional average treatment effect from observational data is highly challenging due to the existence of treatment selection bias. Prevalent methods mitigate this issue by aligning distributions of different treatment groups in the latent space. However, there are two critical problems that these methods fail to address: (1) mini-batch sampling effects (MSE), which causes misalignment in non-ideal mini-batches with outcome imbalance and outliers; (2) unobserved confounder effects (UCE), which results in inaccurate discrepancy calculation due to the neglect of unobserved confounders. To tackle these problems, we propose a principled approach named Entire Space CounterFactual Regression (ESCFR), which is a new take on optimal transport in the context of causality. Specifically, based on the framework of stochastic optimal transport, we propose a relaxed mass-preserving regularizer to address the MSE issue and design a proximal factual outcome regularizer to handle the UCE issue. Extensive experiments demonstrate that our proposed ESCFR can successfully tackle the treatment selection bias and achieve significantly better performance than state-of-the-art methods.
Self-Supervised Audio-and-Text Pre-training with Extremely Low-Resource Parallel Data
Apr 10, 2022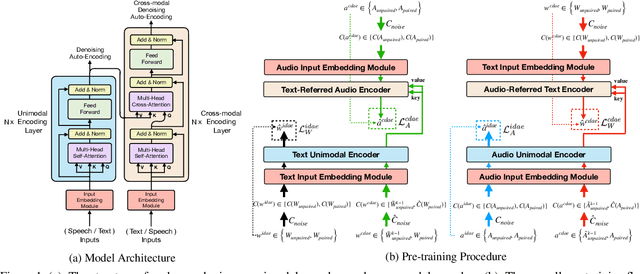
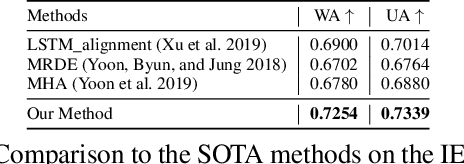
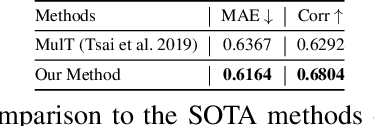
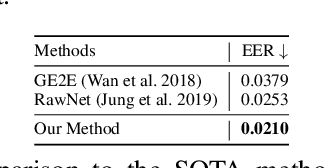
Multimodal pre-training for audio-and-text has recently been proved to be effective and has significantly improved the performance of many downstream speech understanding tasks. However, these state-of-the-art pre-training audio-text models work well only when provided with large amount of parallel audio-and-text data, which brings challenges on many languages that are rich in unimodal corpora but scarce of parallel cross-modal corpus. In this paper, we investigate whether it is possible to pre-train an audio-text multimodal model with extremely low-resource parallel data and extra non-parallel unimodal data. Our pre-training framework consists of the following components: (1) Intra-modal Denoising Auto-Encoding (IDAE), which is able to reconstruct input text (audio) representations from a noisy version of itself. (2) Cross-modal Denoising Auto-Encoding (CDAE), which is pre-trained to reconstruct the input text (audio), given both a noisy version of the input text (audio) and the corresponding translated noisy audio features (text embeddings). (3) Iterative Denoising Process (IDP), which iteratively translates raw audio (text) and the corresponding text embeddings (audio features) translated from previous iteration into the new less-noisy text embeddings (audio features). We adapt a dual cross-modal Transformer as our backbone model which consists of two unimodal encoders for IDAE and two cross-modal encoders for CDAE and IDP. Our method achieves comparable performance on multiple downstream speech understanding tasks compared with the model pre-trained on fully parallel data, demonstrating the great potential of the proposed method. Our code is available at: \url{https://github.com/KarlYuKang/Low-Resource-Multimodal-Pre-training}.
ESCM$^2$: Entire Space Counterfactual Multi-Task Model for Post-Click Conversion Rate Estimation
Apr 03, 2022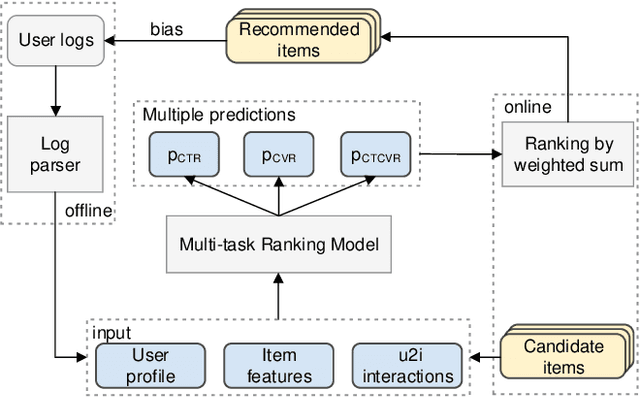

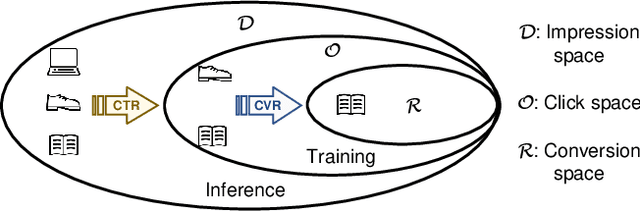
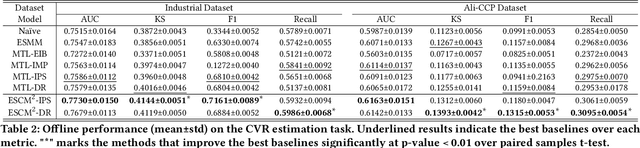
Accurate estimation of post-click conversion rate is critical for building recommender systems, which has long been confronted with sample selection bias and data sparsity issues. Methods in the Entire Space Multi-task Model (ESMM) family leverage the sequential pattern of user actions, i.e. $impression\rightarrow click \rightarrow conversion$ to address data sparsity issue. However, they still fail to ensure the unbiasedness of CVR estimates. In this paper, we theoretically demonstrate that ESMM suffers from the following two problems: (1) Inherent Estimation Bias (IEB), where the estimated CVR of ESMM is inherently higher than the ground truth; (2) Potential Independence Priority (PIP) for CTCVR estimation, where there is a risk that the ESMM overlooks the causality from click to conversion. To this end, we devise a principled approach named Entire Space Counterfactual Multi-task Modelling (ESCM$^2$), which employs a counterfactual risk miminizer as a regularizer in ESMM to address both IEB and PIP issues simultaneously. Extensive experiments on offline datasets and online environments demonstrate that our proposed ESCM$^2$ can largely mitigate the inherent IEB and PIP issues and achieve better performance than baseline models.
CTAL: Pre-training Cross-modal Transformer for Audio-and-Language Representations
Sep 01, 2021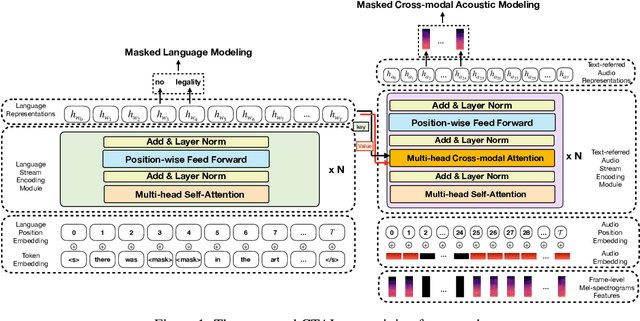
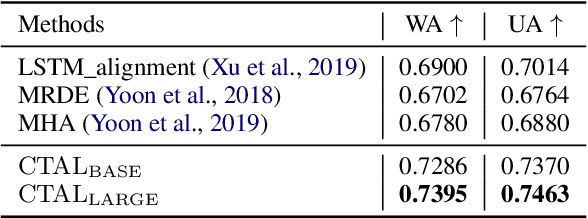
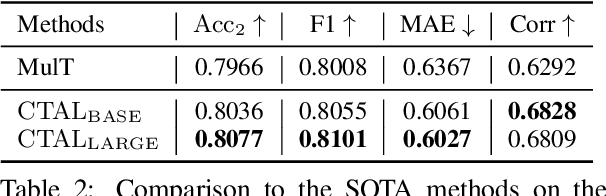
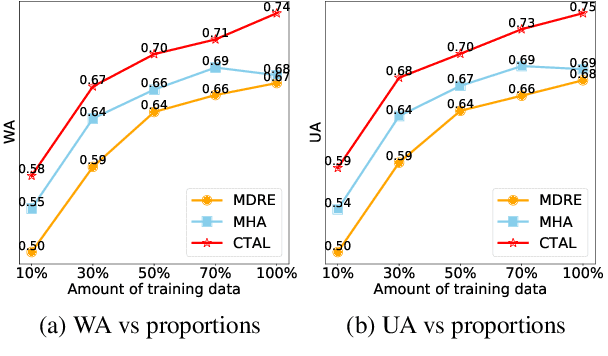
Existing audio-language task-specific predictive approaches focus on building complicated late-fusion mechanisms. However, these models are facing challenges of overfitting with limited labels and low model generalization abilities. In this paper, we present a Cross-modal Transformer for Audio-and-Language, i.e., CTAL, which aims to learn the intra-modality and inter-modality connections between audio and language through two proxy tasks on a large amount of audio-and-language pairs: masked language modeling and masked cross-modal acoustic modeling. After fine-tuning our pre-trained model on multiple downstream audio-and-language tasks, we observe significant improvements across various tasks, such as, emotion classification, sentiment analysis, and speaker verification. On this basis, we further propose a specially-designed fusion mechanism that can be used in fine-tuning phase, which allows our pre-trained model to achieve better performance. Lastly, we demonstrate detailed ablation studies to prove that both our novel cross-modality fusion component and audio-language pre-training methods significantly contribute to the promising results.
Solving ESL Sentence Completion Questions via Pre-trained Neural Language Models
Jul 15, 2021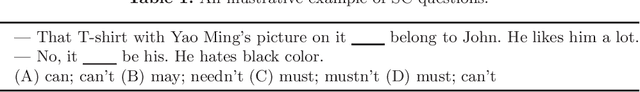
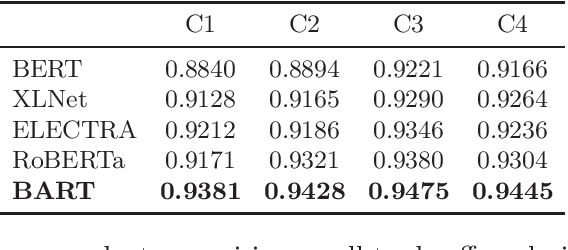
Sentence completion (SC) questions present a sentence with one or more blanks that need to be filled in, three to five possible words or phrases as options. SC questions are widely used for students learning English as a Second Language (ESL) and building computational approaches to automatically solve such questions is beneficial to language learners. In this work, we propose a neural framework to solve SC questions in English examinations by utilizing pre-trained language models. We conduct extensive experiments on a real-world K-12 ESL SC question dataset and the results demonstrate the superiority of our model in terms of prediction accuracy. Furthermore, we run precision-recall trade-off analysis to discuss the practical issues when deploying it in real-life scenarios. To encourage reproducible results, we make our code publicly available at \url{https://github.com/AIED2021/ESL-SentenceCompletion}.