 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying the Robustness of Retrieval-Augmented Language Models Against Spurious Features in Grounding Data
Mar 07, 2025Robustness has become a critical attribute for the deployment of RAG systems in real-world applications. Existing research focuses on robustness to explicit noise (e.g., document semantics) but overlooks spurious features (a.k.a. implicit noise). While previous works have explored spurious features in LLMs, they are limited to specific features (e.g., formats) and narrow scenarios (e.g., ICL). In this work, we statistically confirm the presence of spurious features in the RAG paradigm, a robustness problem caused by the sensitivity of LLMs to semantic-agnostic features. Moreover, we provide a comprehensive taxonomy of spurious features and empirically quantify their impact through controlled experiments. Further analysis reveals that not all spurious features are harmful and they can even be beneficial sometimes. Extensive evaluation results across multiple LLMs suggest that spurious features are a widespread and challenging problem in the field of RAG. The code and dataset will be released to facilitate future research. We release all codes and data at: $\\\href{https://github.com/maybenotime/RAG-SpuriousFeatures}{https://github.com/maybenotime/RAG-SpuriousFeatures}$.
MuDAF: Long-Context Multi-Document Attention Focusing through Contrastive Learning on Attention Heads
Feb 19, 2025Large Language Models (LLMs) frequently show distracted attention due to irrelevant information in the input, which severely impairs their long-context capabilities. Inspired by recent studies on the effectiveness of retrieval heads in long-context factutality, we aim at addressing this distraction issue through improving such retrieval heads directly. We propose Multi-Document Attention Focusing (MuDAF), a novel method that explicitly optimizes the attention distribution at the head level through contrastive learning. According to the experimental results, MuDAF can significantly improve the long-context question answering performance of LLMs, especially in multi-document question answering. Extensive evaluations on retrieval scores and attention visualizations show that MuDAF possesses great potential in making attention heads more focused on relevant information and reducing attention distractions.
Towards Truthful Multilingual Large Language Models: Benchmarking and Alignment Strategies
Jun 20, 2024In the era of large language models (LLMs), building multilingual large language models (MLLMs) that can serve users worldwide holds great significance. However, existing research seldom focuses on the truthfulness of MLLMs. Meanwhile, contemporary multilingual aligning technologies struggle to balance massive languages and often exhibit serious truthfulness gaps across different languages, especially those that differ greatly from English. In our work, we construct a benchmark for truthfulness evaluation in multilingual scenarios and explore the ways to align facts across languages to enhance the truthfulness of MLLMs. Furthermore, we propose Fact-aware Multilingual Selective Synergy (FaMSS) to optimize the data allocation across a large number of languages and different data types. Experimental results demonstrate that our approach can effectively reduce the multilingual representation disparity and enhance the multilingual capabilities of LLMs.
Self-Supervised Audio-and-Text Pre-training with Extremely Low-Resource Parallel Data
Apr 10, 2022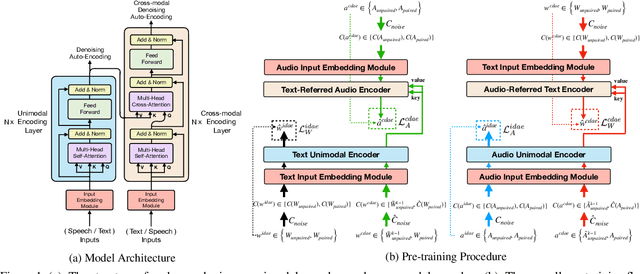
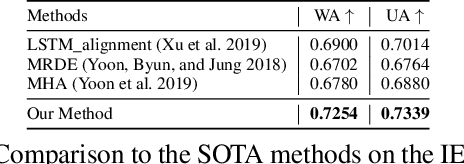
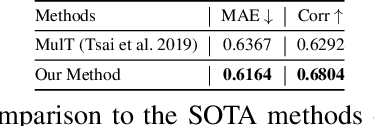
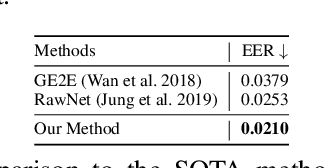
Multimodal pre-training for audio-and-text has recently been proved to be effective and has significantly improved the performance of many downstream speech understanding tasks. However, these state-of-the-art pre-training audio-text models work well only when provided with large amount of parallel audio-and-text data, which brings challenges on many languages that are rich in unimodal corpora but scarce of parallel cross-modal corpus. In this paper, we investigate whether it is possible to pre-train an audio-text multimodal model with extremely low-resource parallel data and extra non-parallel unimodal data. Our pre-training framework consists of the following components: (1) Intra-modal Denoising Auto-Encoding (IDAE), which is able to reconstruct input text (audio) representations from a noisy version of itself. (2) Cross-modal Denoising Auto-Encoding (CDAE), which is pre-trained to reconstruct the input text (audio), given both a noisy version of the input text (audio) and the corresponding translated noisy audio features (text embeddings). (3) Iterative Denoising Process (IDP), which iteratively translates raw audio (text) and the corresponding text embeddings (audio features) translated from previous iteration into the new less-noisy text embeddings (audio features). We adapt a dual cross-modal Transformer as our backbone model which consists of two unimodal encoders for IDAE and two cross-modal encoders for CDAE and IDP. Our method achieves comparable performance on multiple downstream speech understanding tasks compared with the model pre-trained on fully parallel data, demonstrating the great potential of the proposed method. Our code is available at: \url{https://github.com/KarlYuKang/Low-Resource-Multimodal-Pre-training}.
CTAL: Pre-training Cross-modal Transformer for Audio-and-Language Representations
Sep 01, 2021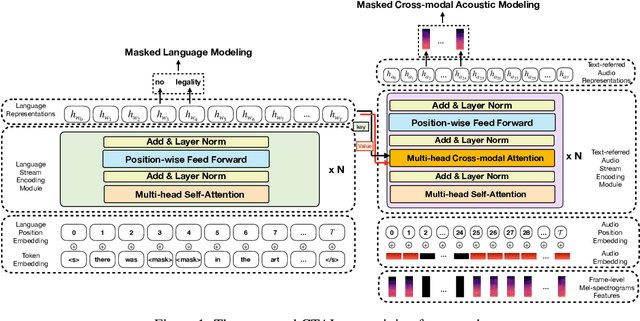
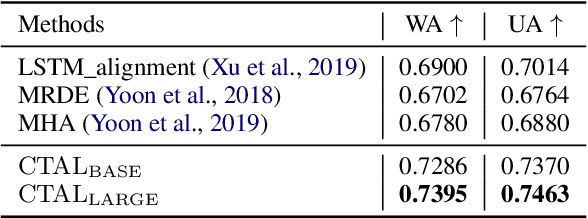
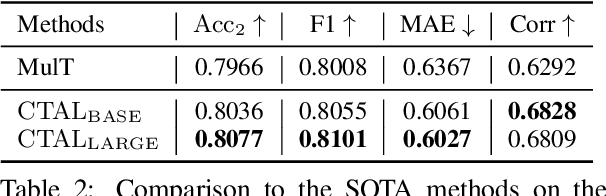
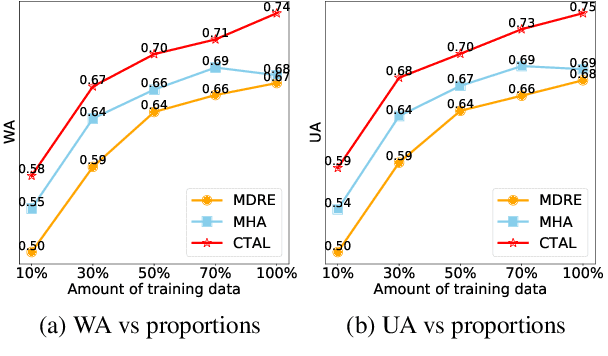
Existing audio-language task-specific predictive approaches focus on building complicated late-fusion mechanisms. However, these models are facing challenges of overfitting with limited labels and low model generalization abilities. In this paper, we present a Cross-modal Transformer for Audio-and-Language, i.e., CTAL, which aims to learn the intra-modality and inter-modality connections between audio and language through two proxy tasks on a large amount of audio-and-language pairs: masked language modeling and masked cross-modal acoustic modeling. After fine-tuning our pre-trained model on multiple downstream audio-and-language tasks, we observe significant improvements across various tasks, such as, emotion classification, sentiment analysis, and speaker verification. On this basis, we further propose a specially-designed fusion mechanism that can be used in fine-tuning phase, which allows our pre-trained model to achieve better performance. Lastly, we demonstrate detailed ablation studies to prove that both our novel cross-modality fusion component and audio-language pre-training methods significantly contribute to the promising results.
Temporal-aware Language Representation Learning From Crowdsourced Labels
Jul 15, 2021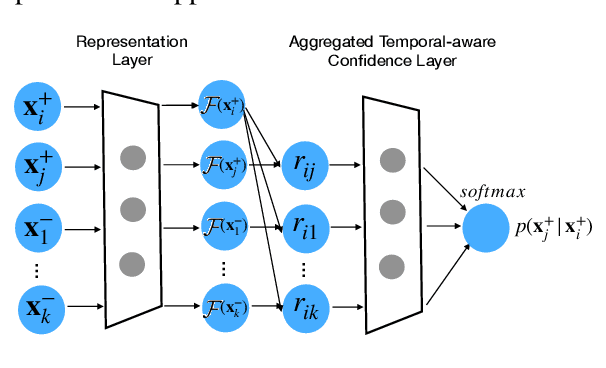


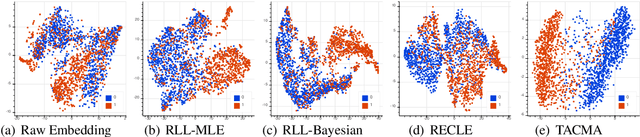
Learning effective language representations from crowdsourced labels is crucial for many real-world machine learning tasks. A challenging aspect of this problem is that the quality of crowdsourced labels suffer high intra- and inter-observer variability. Since the high-capacity deep neural networks can easily memorize all disagreements among crowdsourced labels, directly applying existing supervised language representation learning algorithms may yield suboptimal solutions. In this paper, we propose \emph{TACMA}, a \underline{t}emporal-\underline{a}ware language representation learning heuristic for \underline{c}rowdsourced labels with \underline{m}ultiple \underline{a}nnotators. The proposed approach (1) explicitly models the intra-observer variability with attention mechanism; (2) computes and aggregates per-sample confidence scores from multiple workers to address the inter-observer disagreements. The proposed heuristic is extremely easy to implement in around 5 lines of code. The proposed heuristic is evaluated on four synthetic and four real-world data sets. The results show that our approach outperforms a wide range of state-of-the-art baselines in terms of prediction accuracy and AUC. To encourage the reproducible results, we make our code publicly available at \url{https://github.com/CrowdsourcingMining/TACMA}.
Automatic Task Requirements Writing Evaluation via Machine Reading Comprehension
Jul 15, 2021

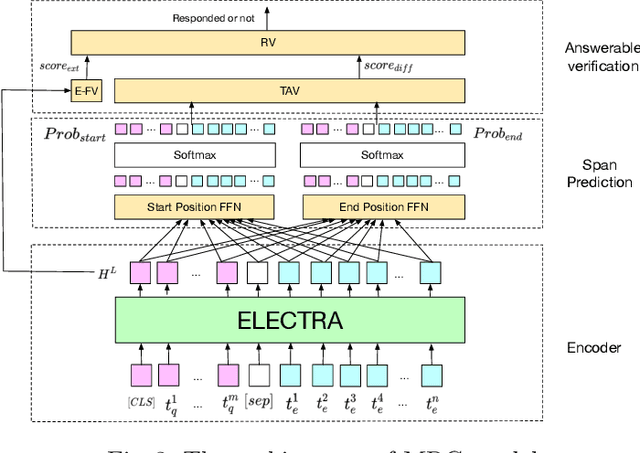
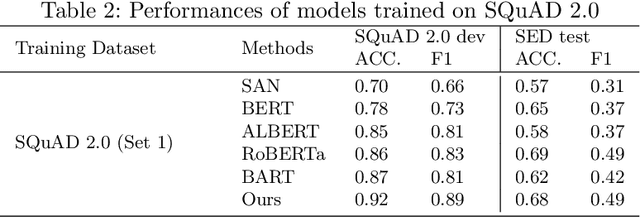
Task requirements (TRs) writing is an important question type in Key English Test and Preliminary English Test. A TR writing question may include multiple requirements and a high-quality essay must respond to each requirement thoroughly and accurately. However, the limited teacher resources prevent students from getting detailed grading instantly. The majority of existing automatic essay scoring systems focus on giving a holistic score but rarely provide reasons to support it. In this paper, we proposed an end-to-end framework based on machine reading comprehension (MRC) to address this problem to some extent. The framework not only detects whether an essay responds to a requirement question, but clearly marks where the essay answers the question. Our framework consists of three modules: question normalization module, ELECTRA based MRC module and response locating module. We extensively explore state-of-the-art MRC methods. Our approach achieves 0.93 accuracy score and 0.85 F1 score on a real-world educational dataset. To encourage reproducible results, we make our code publicly available at \url{https://github.com/aied2021TRMRC/AIED_2021_TRMRC_code}.
A Multimodal Machine Learning Framework for Teacher Vocal Delivery Evaluation
Jul 15, 2021

The quality of vocal delivery is one of the key indicators for evaluating teacher enthusiasm, which has been widely accepted to be connected to the overall course qualities. However, existing evaluation for vocal delivery is mainly conducted with manual ratings, which faces two core challenges: subjectivity and time-consuming. In this paper, we present a novel machine learning approach that utilizes pairwise comparisons and a multimodal orthogonal fusing algorithm to generate large-scale objective evaluation results of the teacher vocal delivery in terms of fluency and passion. We collect two datasets from real-world education scenarios and the experiment results demonstrate the effectiveness of our algorithm. To encourage reproducible results, we make our code public available at \url{https://github.com/tal-ai/ML4VocalDelivery.git}.
An Educational System for Personalized Teacher Recommendation in K-12 Online Classrooms
Jul 15, 2021
In this paper, we propose a simple yet effective solution to build practical teacher recommender systems for online one-on-one classes. Our system consists of (1) a pseudo matching score module that provides reliable training labels; (2) a ranking model that scores every candidate teacher; (3) a novelty boosting module that gives additional opportunities to new teachers; and (4) a diversity metric that guardrails the recommended results to reduce the chance of collision. Offline experimental results show that our approach outperforms a wide range of baselines. Furthermore, we show that our approach is able to reduce the number of student-teacher matching attempts from 7.22 to 3.09 in a five-month observation on a third-party online education platform.
Solving ESL Sentence Completion Questions via Pre-trained Neural Language Models
Jul 15, 2021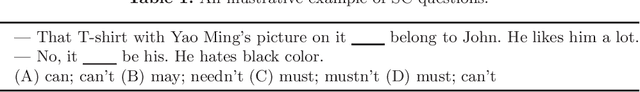
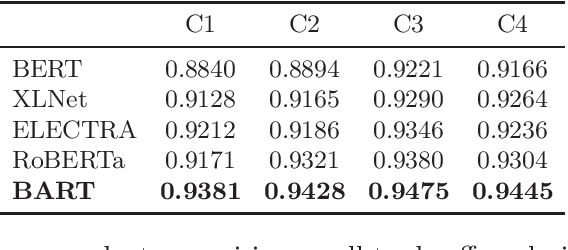
Sentence completion (SC) questions present a sentence with one or more blanks that need to be filled in, three to five possible words or phrases as options. SC questions are widely used for students learning English as a Second Language (ESL) and building computational approaches to automatically solve such questions is beneficial to language learners. In this work, we propose a neural framework to solve SC questions in English examinations by utilizing pre-trained language models. We conduct extensive experiments on a real-world K-12 ESL SC question dataset and the results demonstrate the superiority of our model in terms of prediction accuracy. Furthermore, we run precision-recall trade-off analysis to discuss the practical issues when deploying it in real-life scenarios. To encourage reproducible results, we make our code publicly available at \url{https://github.com/AIED2021/ESL-SentenceCompletion}.