 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTableDreamer: Progressive and Weakness-guided Data Synthesis from Scratch for Table Instruction Tuning
Jun 10, 2025Despite the commendable progress of recent LLM-based data synthesis methods, they face two limitations in generating table instruction tuning data. First, they can not thoroughly explore the vast input space of table understanding tasks, leading to limited data diversity. Second, they ignore the weaknesses in table understanding ability of the target LLM and blindly pursue the increase of data quantity, resulting in suboptimal data efficiency. In this paper, we introduce a progressive and weakness-guided data synthesis framework tailored for table instruction tuning, named TableDreamer, to mitigate the above issues. Specifically, we first synthesize diverse tables and related instructions as seed data, and then perform an iterative exploration of the input space under the guidance of the newly identified weakness data, which eventually serve as the final training data for fine-tuning the target LLM. Extensive experiments on 10 tabular benchmarks demonstrate the effectiveness of the proposed framework, which boosts the average accuracy of Llama3.1-8B-instruct by 11.62% (49.07% to 60.69%) with 27K GPT-4o synthetic data and outperforms state-of-the-art data synthesis baselines which use more training data. The code and data is available at https://github.com/SpursGoZmy/TableDreamer
Pervasive wireless channel modeling theory and applications to 6G GBSMs for all frequency bands and all scenarios
Jun 06, 2022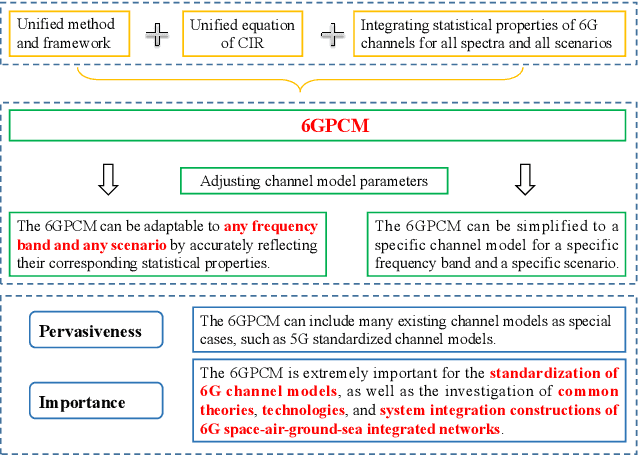
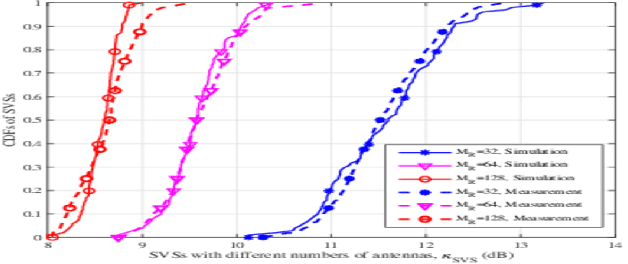

In this paper, a pervasive wireless channel modeling theory is first proposed, which uses a unified channel modeling method and a unified equation of channel impulse response (CIR), and can integrate important channel characteristics at different frequency bands and scenarios. Then, we apply the proposed theory to a three dimensional (3D) space-time-frequency (STF) non-stationary geometry-based stochastic model (GBSM) for the sixth generation (6G) wireless communication systems. The proposed 6G pervasive channel model (6GPCM) can characterize statistical properties of channels at all frequency bands from sub-6 GHz to visible light communication (VLC) bands and all scenarios such as unmanned aerial vehicle (UAV), maritime, (ultra-)massive multiple-input multiple-output (MIMO), reconfigurable intelligent surface (RIS), and industry Internet of things (IIoT) scenarios. By adjusting channel model parameters, the 6GPCM can be reduced to various simplified channel models for specific frequency bands and scenarios. Also, it includes standard fifth generation (5G) channel models as special cases. In addition, key statistical properties of the proposed 6GPCM are derived, simulated, and verified by various channel measurement results, which clearly demonstrates its accuracy, pervasiveness, and applicability.
Self-Supervised Audio-and-Text Pre-training with Extremely Low-Resource Parallel Data
Apr 10, 2022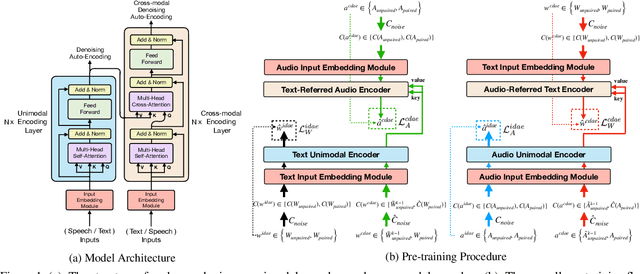
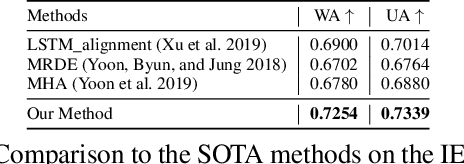
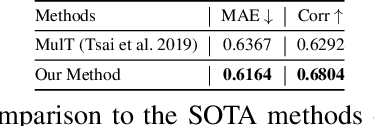
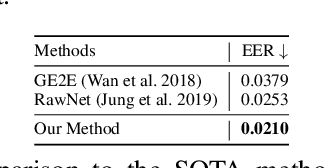
Multimodal pre-training for audio-and-text has recently been proved to be effective and has significantly improved the performance of many downstream speech understanding tasks. However, these state-of-the-art pre-training audio-text models work well only when provided with large amount of parallel audio-and-text data, which brings challenges on many languages that are rich in unimodal corpora but scarce of parallel cross-modal corpus. In this paper, we investigate whether it is possible to pre-train an audio-text multimodal model with extremely low-resource parallel data and extra non-parallel unimodal data. Our pre-training framework consists of the following components: (1) Intra-modal Denoising Auto-Encoding (IDAE), which is able to reconstruct input text (audio) representations from a noisy version of itself. (2) Cross-modal Denoising Auto-Encoding (CDAE), which is pre-trained to reconstruct the input text (audio), given both a noisy version of the input text (audio) and the corresponding translated noisy audio features (text embeddings). (3) Iterative Denoising Process (IDP), which iteratively translates raw audio (text) and the corresponding text embeddings (audio features) translated from previous iteration into the new less-noisy text embeddings (audio features). We adapt a dual cross-modal Transformer as our backbone model which consists of two unimodal encoders for IDAE and two cross-modal encoders for CDAE and IDP. Our method achieves comparable performance on multiple downstream speech understanding tasks compared with the model pre-trained on fully parallel data, demonstrating the great potential of the proposed method. Our code is available at: \url{https://github.com/KarlYuKang/Low-Resource-Multimodal-Pre-training}.
Formula graph self-attention network for representation-domain independent materials discovery
Jan 14, 2022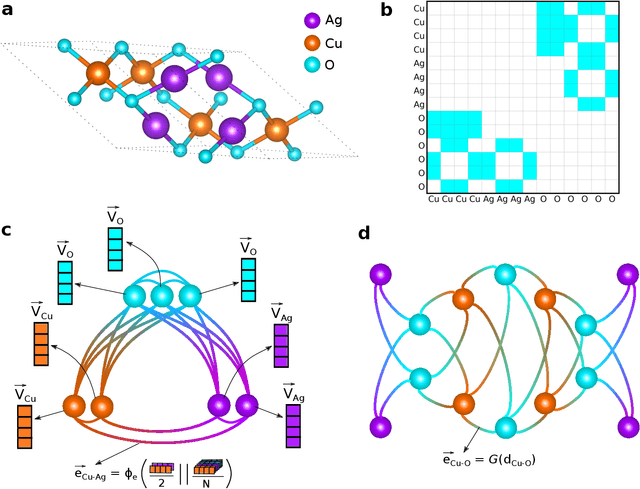
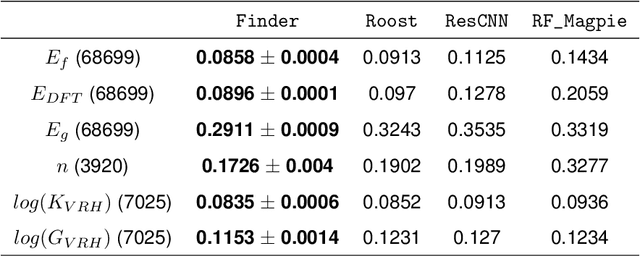
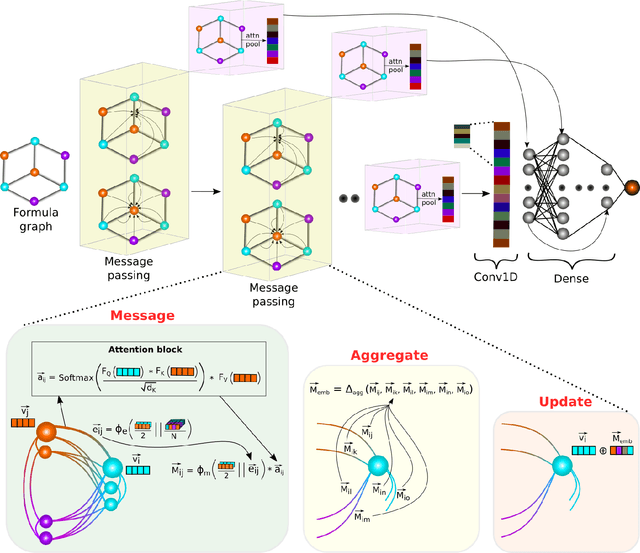
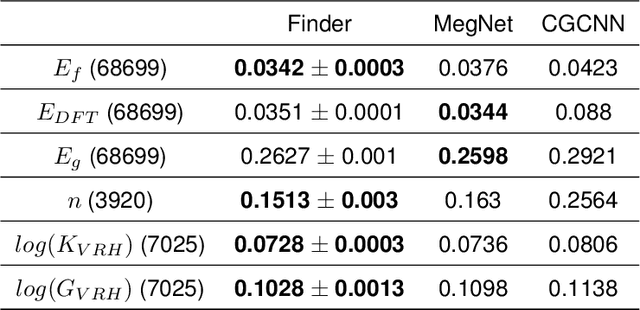
The success of machine learning (ML) in materials property prediction depends heavily on how the materials are represented for learning. Two dominant families of material descriptors exist, one that encodes crystal structure in the representation and the other that only uses stoichiometric information with the hope of discovering new materials. Graph neural networks (GNNs) in particular have excelled in predicting material properties within chemical accuracy. However, current GNNs are limited to only one of the above two avenues owing to the little overlap between respective material representations. Here, we introduce a new concept of formula graph which unifies both stoichiometry-only and structure-based material descriptors. We further develop a self-attention integrated GNN that assimilates a formula graph and show that the proposed architecture produces material embeddings transferable between the two domains. Our model substantially outperforms previous structure-based GNNs as well as structure-agnostic counterparts while exhibiting better sample efficiency and faster convergence. Finally, the model is applied in a challenging exemplar to predict the complex dielectric function of materials and nominate new substances that potentially exhibit epsilon-near-zero phenomena.
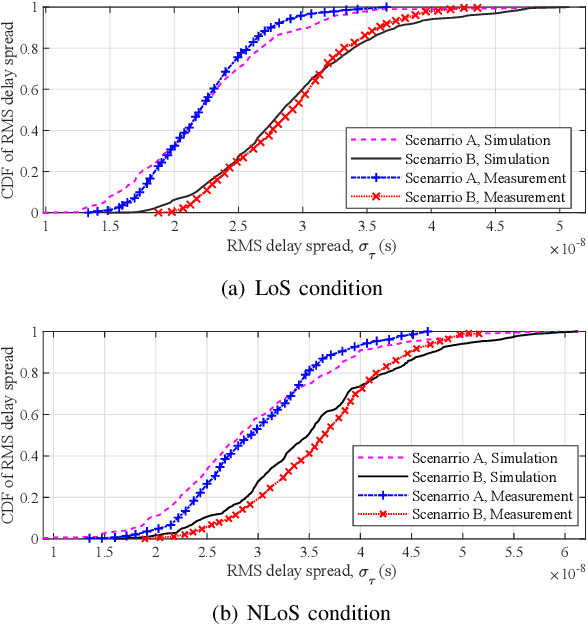
A Novel 3D Non-Stationary GBSM for 6G THz Ultra-Massive MIMO Wireless Systems
Aug 14, 2021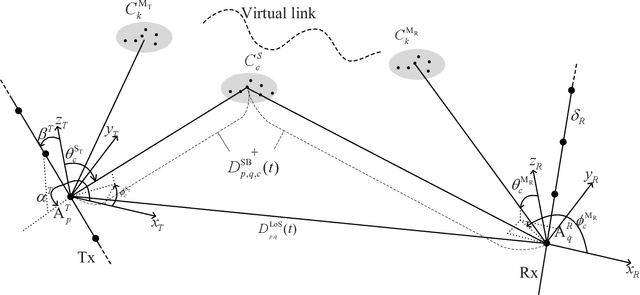

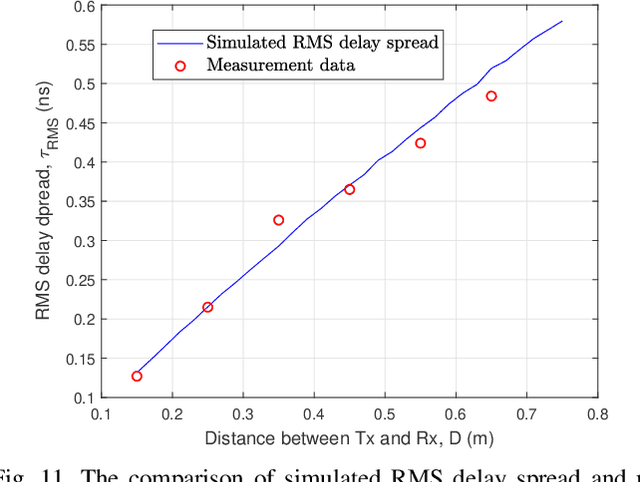

Terahertz (THz) communication is now being considered as one of possible technologies for the sixth generation (6G) wireless communication systems. In this paper, a novel three-dimensional (3D) space-time-frequency non-stationary theoretical channel model is first proposed for 6G THz wireless communication systems employing ultra-massive multiple-input multiple-output (MIMO) technologies with long traveling paths. Considering frequency-dependent diffuse scattering, which is a special property of THz channels different from millimeter wave (mmWave) channels, the relative angles and delays of rays within one cluster will evolve in the frequency domain. Then, a corresponding simulation model is proposed with discrete angles calculated using the method of equal area (MEA). The statistical properties of the proposed theoretical and simulation models are derived and compared, showing good agreements. The accuracy and flexibility of the proposed simulation model are demonstrated by comparing the simulation results of the relative angle spread and root mean square (RMS) delay spread with corresponding measurements.
Temporal-aware Language Representation Learning From Crowdsourced Labels
Jul 15, 2021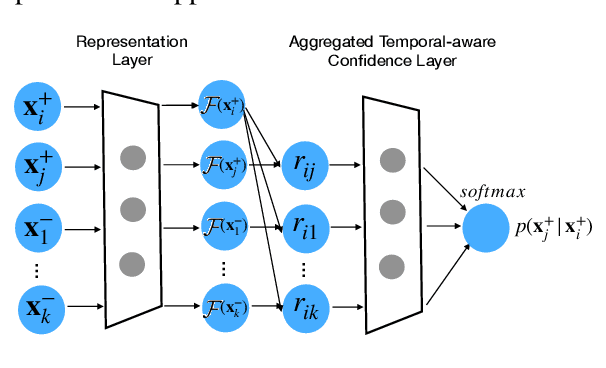


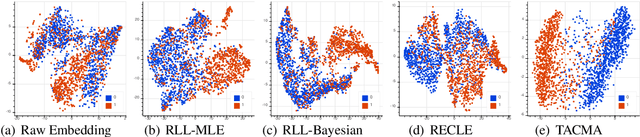
Learning effective language representations from crowdsourced labels is crucial for many real-world machine learning tasks. A challenging aspect of this problem is that the quality of crowdsourced labels suffer high intra- and inter-observer variability. Since the high-capacity deep neural networks can easily memorize all disagreements among crowdsourced labels, directly applying existing supervised language representation learning algorithms may yield suboptimal solutions. In this paper, we propose \emph{TACMA}, a \underline{t}emporal-\underline{a}ware language representation learning heuristic for \underline{c}rowdsourced labels with \underline{m}ultiple \underline{a}nnotators. The proposed approach (1) explicitly models the intra-observer variability with attention mechanism; (2) computes and aggregates per-sample confidence scores from multiple workers to address the inter-observer disagreements. The proposed heuristic is extremely easy to implement in around 5 lines of code. The proposed heuristic is evaluated on four synthetic and four real-world data sets. The results show that our approach outperforms a wide range of state-of-the-art baselines in terms of prediction accuracy and AUC. To encourage the reproducible results, we make our code publicly available at \url{https://github.com/CrowdsourcingMining/TACMA}.
A Multimodal Machine Learning Framework for Teacher Vocal Delivery Evaluation
Jul 15, 2021

The quality of vocal delivery is one of the key indicators for evaluating teacher enthusiasm, which has been widely accepted to be connected to the overall course qualities. However, existing evaluation for vocal delivery is mainly conducted with manual ratings, which faces two core challenges: subjectivity and time-consuming. In this paper, we present a novel machine learning approach that utilizes pairwise comparisons and a multimodal orthogonal fusing algorithm to generate large-scale objective evaluation results of the teacher vocal delivery in terms of fluency and passion. We collect two datasets from real-world education scenarios and the experiment results demonstrate the effectiveness of our algorithm. To encourage reproducible results, we make our code public available at \url{https://github.com/tal-ai/ML4VocalDelivery.git}.
Multi-Task Learning based Online Dialogic Instruction Detection with Pre-trained Language Models
Jul 15, 2021
In this work, we study computational approaches to detect online dialogic instructions, which are widely used to help students understand learning materials, and build effective study habits. This task is rather challenging due to the widely-varying quality and pedagogical styles of dialogic instructions. To address these challenges, we utilize pre-trained language models, and propose a multi-task paradigm which enhances the ability to distinguish instances of different classes by enlarging the margin between categories via contrastive loss. Furthermore, we design a strategy to fully exploit the misclassified examples during the training stage. Extensive experiments on a real-world online educational data set demonstrate that our approach achieves superior performance compared to representative baselines. To encourage reproducible results, we make our implementation online available at \url{https://github.com/AIED2021/multitask-dialogic-instruction}.
Analogical discovery of disordered perovskite oxides by crystal structure information hidden in unsupervised material fingerprints
May 25, 2021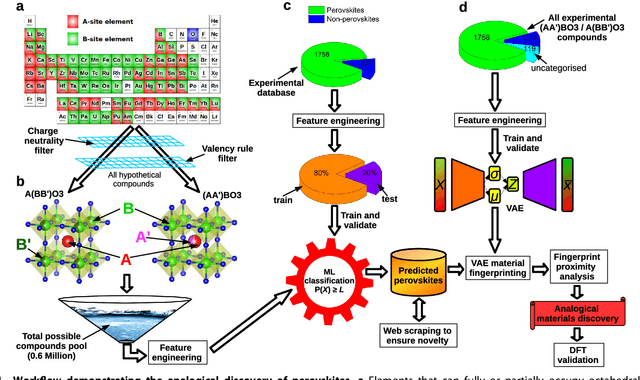

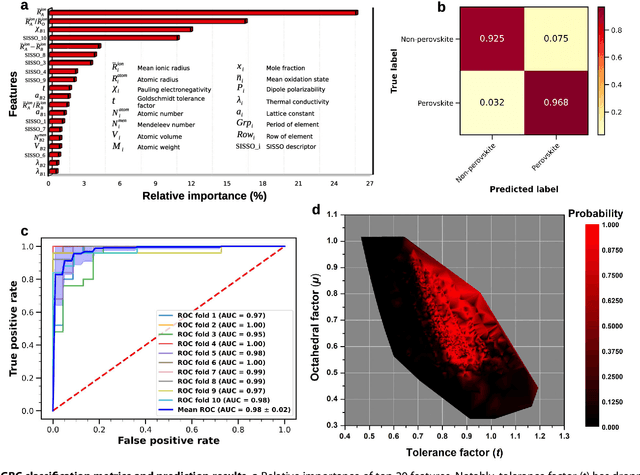
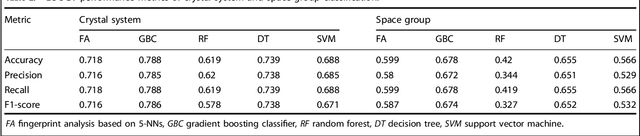
Compositional disorder induces myriad captivating phenomena in perovskites. Target-driven discovery of perovskite solid solutions has been a great challenge due to the analytical complexity introduced by disorder. Here, we demonstrate that an unsupervised deep learning strategy can find fingerprints of disordered materials that embed perovskite formability and underlying crystal structure information by learning only from the chemical composition, manifested in (A1-xA'x)BO3 and A(B1-xB'x)O3 formulae. This phenomenon can be capitalized to predict the crystal symmetry of experimental compositions, outperforming several supervised machine learning (ML) algorithms. The educated nature of material fingerprints has led to the conception of analogical materials discovery that facilitates inverse exploration of promising perovskites based on similarity investigation with known materials. The search space of unstudied perovskites is screened from ~600,000 feasible compounds using experimental data powered ML models and automated web mining tools at a 94% success rate. This concept further provides insights on possible phase transitions and computational modelling of complex compositions. The proposed quantitative analysis of materials analogies is expected to bridge the gap between the existing materials literature and the undiscovered terrain.
NeuCrowd: Neural Sampling Network for Representation Learning with Crowdsourced Labels
Mar 21, 2020
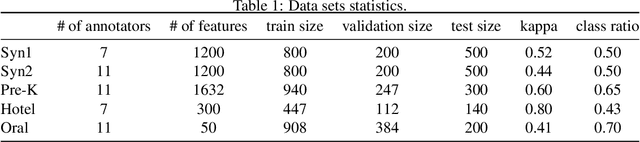
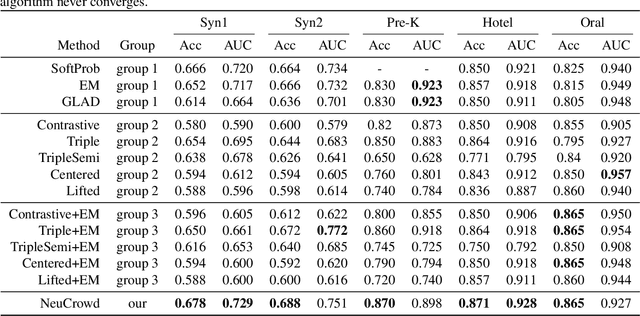

Representation learning approaches require a massive amount of discriminative training data, which is unavailable in many scenarios, such as healthcare, small city, education, etc. In practice, people refer to crowdsourcing to get annotated labels. However, due to issues like data privacy, budget limitation, shortage of domain-specific annotators, the number of crowdsourced labels are still very limited. Moreover, because of annotators' diverse expertises, crowdsourced labels are often inconsistent. Thus, directly applying existing representation learning algorithms may easily get the overfitting problem and yield suboptimal solutions. In this paper, we propose \emph{NeuCrowd}, a unified framework for representation learning from crowdsourced labels. The proposed framework (1) creates a sufficient number of high-quality \emph{n}-tuplet training samples by utilizing safety-aware sampling and robust anchor generation; and (2) automatically learns a neural sampling network that adaptively learns to select effective samples for representation learning network. The proposed framework is evaluated on both synthetic and real-world data sets. The results show that our approach outperforms a wide range of state-of-the-art baselines in terms of prediction accuracy and AUC\footnote{To encourage the reproducible results, we make our code public on a github repository, i.e., \url{https://github.com/crowd-data-mining/NeuCrowd}}.