 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Optimization of Latency and Accuracy for Split Federated Learning in User-Centric Cell-Free MIMO Networks
Feb 05, 2026This paper proposes a user-centric split federated learning (UCSFL) framework for user-centric cell-free multiple-input multiple-output (CF-MIMO) networks to support split federated learning (SFL). In the proposed UCSFL framework, users deploy split sub-models locally, while complete models are maintained and updated at access point (AP)-side distributed processing units (DPUs), followed by a two-level aggregation procedure across DPUs and the central processing unit (CPU). Under standard machine learning (ML) assumptions, we provide a theoretical convergence analysis for UCSFL, which reveals that the AP-cluster size is a key factor influencing model training accuracy. Motivated by this result, we introduce a new performance metric, termed the latency-to-accuracy ratio, defined as the ratio of a user's per-iteration training latency to the weighted size of its AP cluster. Based on this metric, we formulate a joint optimization problem to minimize the maximum latency-to-accuracy ratio by jointly optimizing uplink power control, downlink beamforming, model splitting, and AP clustering. The resulting problem is decomposed into two sub-problems operating on different time scales, for which dedicated algorithms are developed to handle the short-term and long-term optimizations, respectively. Simulation results verify the convergence of the proposed algorithms and demonstrate that UCSFL effectively reduces the latency-to-accuracy ratio of the VGG16 model compared with baseline schemes. Moreover, the proposed framework adaptively adjusts splitting and clustering strategies in response to varying communication and computation resources. An MNIST-based handwritten digit classification example further shows that UCSFL significantly accelerates the convergence of the VGG16 model.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Two-Stage Signal Reconstruction for Amplitude-Phase-Time Block Modulation-based Communications
Dec 20, 2025Operating power amplifiers (PAs) at lower input back-off (IBO) levels is an effective way to improve PA efficiency, but often introduces severe nonlinear distortion that degrades transmission performance. Amplitude-phase-time block modulation (APTBM) has recently emerged as an effective solution to this problem. By leveraging the intrinsic amplitude and phase constraints of each APTBM block, PA-induced nonlinear distortion can be mitigated through constraint-guided signal reconstruction. However, existing reconstruction methods apply these constraints only heuristically and statistically, limiting the achievable IBO reduction and PA efficiency improvement. This paper addresses this limitation by decomposing the nonlinear distortion into dominant and residual components, and accordingly develops a novel two-stage signal reconstruction algorithm consisting of coarse and fine reconstruction stages. The coarse reconstruction stage eliminates the dominant distortion by jointly exploiting the APTBM block structure and PA nonlinear characteristics. The fine reconstruction stage minimizes the residual distortion by formulating a nonconvex optimization problem that explicitly enforces the APTBM constraints. To handle this problem efficiently, a low-complexity iterative variable substitution method is introduced, which relaxes the problem into a sequence of trust-region subproblems, each solvable in closed form. The proposed algorithm is validated through comprehensive numerical simulations and testbed experiments. Results show that it achieves up to 4 dB IBO reduction in simulations and up to 2 dB IBO reduction in experiments while maintaining transmission performance, corresponding to PA efficiency improvements of 59.1\% and 33.9\%, respectively, over existing methods.
Kimi Linear: An Expressive, Efficient Attention Architecture
Oct 30, 2025We introduce Kimi Linear, a hybrid linear attention architecture that, for the first time, outperforms full attention under fair comparisons across various scenarios -- including short-context, long-context, and reinforcement learning (RL) scaling regimes. At its core lies Kimi Delta Attention (KDA), an expressive linear attention module that extends Gated DeltaNet with a finer-grained gating mechanism, enabling more effective use of limited finite-state RNN memory. Our bespoke chunkwise algorithm achieves high hardware efficiency through a specialized variant of the Diagonal-Plus-Low-Rank (DPLR) transition matrices, which substantially reduces computation compared to the general DPLR formulation while remaining more consistent with the classical delta rule. We pretrain a Kimi Linear model with 3B activated parameters and 48B total parameters, based on a layerwise hybrid of KDA and Multi-Head Latent Attention (MLA). Our experiments show that with an identical training recipe, Kimi Linear outperforms full MLA with a sizeable margin across all evaluated tasks, while reducing KV cache usage by up to 75% and achieving up to 6 times decoding throughput for a 1M context. These results demonstrate that Kimi Linear can be a drop-in replacement for full attention architectures with superior performance and efficiency, including tasks with longer input and output lengths. To support further research, we open-source the KDA kernel and vLLM implementations, and release the pre-trained and instruction-tuned model checkpoints.
LeanGeo: Formalizing Competitional Geometry problems in Lean
Aug 20, 2025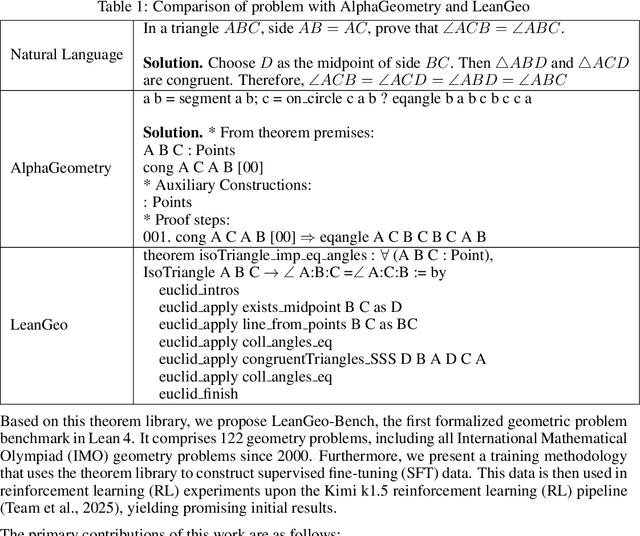

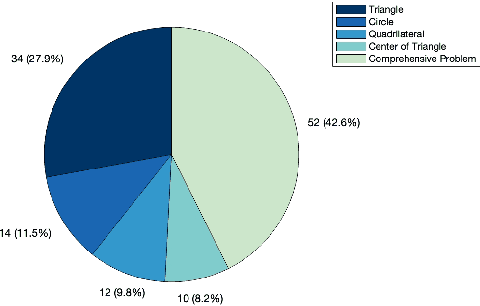
Geometry problems are a crucial testbed for AI reasoning capabilities. Most existing geometry solving systems cannot express problems within a unified framework, thus are difficult to integrate with other mathematical fields. Besides, since most geometric proofs rely on intuitive diagrams, verifying geometry problems is particularly challenging. To address these gaps, we introduce LeanGeo, a unified formal system for formalizing and solving competition-level geometry problems within the Lean 4 theorem prover. LeanGeo features a comprehensive library of high-level geometric theorems with Lean's foundational logic, enabling rigorous proof verification and seamless integration with Mathlib. We also present LeanGeo-Bench, a formal geometry benchmark in LeanGeo, comprising problems from the International Mathematical Olympiad (IMO) and other advanced sources. Our evaluation demonstrates the capabilities and limitations of state-of-the-art Large Language Models on this benchmark, highlighting the need for further advancements in automated geometric reasoning. We open source the theorem library and the benchmark of LeanGeo at https://github.com/project-numina/LeanGeo/tree/master.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
CombiBench: Benchmarking LLM Capability for Combinatorial Mathematics
May 06, 2025Neurosymbolic approaches integrating large language models with formal reasoning have recently achieved human-level performance on mathematics competition problems in algebra, geometry and number theory. In comparison, combinatorics remains a challenging domain, characterized by a lack of appropriate benchmarks and theorem libraries. To address this gap, we introduce CombiBench, a comprehensive benchmark comprising 100 combinatorial problems, each formalized in Lean~4 and paired with its corresponding informal statement. The problem set covers a wide spectrum of difficulty levels, ranging from middle school to IMO and university level, and span over ten combinatorial topics. CombiBench is suitable for testing IMO solving capabilities since it includes all IMO combinatorial problems since 2000 (except IMO 2004 P3 as its statement contain an images). Furthermore, we provide a comprehensive and standardized evaluation framework, dubbed Fine-Eval (for $\textbf{F}$ill-in-the-blank $\textbf{in}$ L$\textbf{e}$an Evaluation), for formal mathematics. It accommodates not only proof-based problems but also, for the first time, the evaluation of fill-in-the-blank questions. Using Fine-Eval as the evaluation method and Kimina Lean Server as the backend, we benchmark several LLMs on CombiBench and observe that their capabilities for formally solving combinatorial problems remain limited. Among all models tested (none of which has been trained for this particular task), Kimina-Prover attains the best results, solving 7 problems (out of 100) under both ``with solution'' and ``without solution'' scenarios. We open source the benchmark dataset alongside with the code of the proposed evaluation method at https://github.com/MoonshotAI/CombiBench/.
Kimina-Prover Preview: Towards Large Formal Reasoning Models with Reinforcement Learning
Apr 15, 2025We introduce Kimina-Prover Preview, a large language model that pioneers a novel reasoning-driven exploration paradigm for formal theorem proving, as showcased in this preview release. Trained with a large-scale reinforcement learning pipeline from Qwen2.5-72B, Kimina-Prover demonstrates strong performance in Lean 4 proof generation by employing a structured reasoning pattern we term \textit{formal reasoning pattern}. This approach allows the model to emulate human problem-solving strategies in Lean, iteratively generating and refining proof steps. Kimina-Prover sets a new state-of-the-art on the miniF2F benchmark, reaching 80.7% with pass@8192. Beyond improved benchmark performance, our work yields several key insights: (1) Kimina-Prover exhibits high sample efficiency, delivering strong results even with minimal sampling (pass@1) and scaling effectively with computational budget, stemming from its unique reasoning pattern and RL training; (2) we demonstrate clear performance scaling with model size, a trend previously unobserved for neural theorem provers in formal mathematics; (3) the learned reasoning style, distinct from traditional search algorithms, shows potential to bridge the gap between formal verification and informal mathematical intuition. We open source distilled versions with 1.5B and 7B parameters of Kimina-Prover
MLLM-FL: Multimodal Large Language Model Assisted Federated Learning on Heterogeneous and Long-tailed Data
Sep 09, 2024



Previous studies on federated learning (FL) often encounter performance degradation due to data heterogeneity among different clients. In light of the recent advances in multimodal large language models (MLLMs), such as GPT-4v and LLaVA, which demonstrate their exceptional proficiency in multimodal tasks, such as image captioning and multimodal question answering. We introduce a novel federated learning framework, named Multimodal Large Language Model Assisted Federated Learning (MLLM-FL), which which employs powerful MLLMs at the server end to address the heterogeneous and long-tailed challenges. Owing to the advanced cross-modality representation capabilities and the extensive open-vocabulary prior knowledge of MLLMs, our framework is adept at harnessing the extensive, yet previously underexploited, open-source data accessible from websites and powerful server-side computational resources. Hence, the MLLM-FL not only enhances the performance but also avoids increasing the risk of privacy leakage and the computational burden on local devices, distinguishing it from prior methodologies. Our framework has three key stages. Initially, prior to local training on local datasets of clients, we conduct global visual-text pretraining of the model. This pretraining is facilitated by utilizing the extensive open-source data available online, with the assistance of multimodal large language models. Subsequently, the pretrained model is distributed among various clients for local training. Finally, once the locally trained models are transmitted back to the server, a global alignment is carried out under the supervision of MLLMs to further enhance the performance. Experimental evaluations on established benchmarks, show that our framework delivers promising performance in the typical scenarios with data heterogeneity and long-tail distribution across different clients in FL.
FVEL: Interactive Formal Verification Environment with Large Language Models via Theorem Proving
Jun 20, 2024



Formal verification (FV) has witnessed growing significance with current emerging program synthesis by the evolving large language models (LLMs). However, current formal verification mainly resorts to symbolic verifiers or hand-craft rules, resulting in limitations for extensive and flexible verification. On the other hand, formal languages for automated theorem proving, such as Isabelle, as another line of rigorous verification, are maintained with comprehensive rules and theorems. In this paper, we propose FVEL, an interactive Formal Verification Environment with LLMs. Specifically, FVEL transforms a given code to be verified into Isabelle, and then conducts verification via neural automated theorem proving with an LLM. The joined paradigm leverages the rigorous yet abundant formulated and organized rules in Isabelle and is also convenient for introducing and adjusting cutting-edge LLMs. To achieve this goal, we extract a large-scale FVELER3. The FVELER dataset includes code dependencies and verification processes that are formulated in Isabelle, containing 758 theories, 29,125 lemmas, and 200,646 proof steps in total with in-depth dependencies. We benchmark FVELER in the FVEL environment by first fine-tuning LLMs with FVELER and then evaluating them on Code2Inv and SV-COMP. The results show that FVEL with FVELER fine-tuned Llama3- 8B solves 17.39% (69 -> 81) more problems, and Mistral-7B 12% (75 -> 84) more problems in SV-COMP. And the proportion of proof errors is reduced. Project page: https://fveler.github.io/.