 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstraint Matters: Multi-Modal Representation for Reducing Mixed-Integer Linear programming
Aug 26, 2025Model reduction, which aims to learn a simpler model of the original mixed integer linear programming (MILP), can solve large-scale MILP problems much faster. Most existing model reduction methods are based on variable reduction, which predicts a solution value for a subset of variables. From a dual perspective, constraint reduction that transforms a subset of inequality constraints into equalities can also reduce the complexity of MILP, but has been largely ignored. Therefore, this paper proposes a novel constraint-based model reduction approach for the MILP. Constraint-based MILP reduction has two challenges: 1) which inequality constraints are critical such that reducing them can accelerate MILP solving while preserving feasibility, and 2) how to predict these critical constraints efficiently. To identify critical constraints, we first label these tight-constraints at the optimal solution as potential critical constraints and design a heuristic rule to select a subset of critical tight-constraints. To learn the critical tight-constraints, we propose a multi-modal representation technique that leverages information from both instance-level and abstract-level MILP formulations. The experimental results show that, compared to the state-of-the-art methods, our method improves the quality of the solution by over 50\% and reduces the computation time by 17.47\%.
Activation-Guided Consensus Merging for Large Language Models
May 20, 2025Recent research has increasingly focused on reconciling the reasoning capabilities of System 2 with the efficiency of System 1. While existing training-based and prompt-based approaches face significant challenges in terms of efficiency and stability, model merging emerges as a promising strategy to integrate the diverse capabilities of different Large Language Models (LLMs) into a unified model. However, conventional model merging methods often assume uniform importance across layers, overlooking the functional heterogeneity inherent in neural components. To address this limitation, we propose \textbf{A}ctivation-Guided \textbf{C}onsensus \textbf{M}erging (\textbf{ACM}), a plug-and-play merging framework that determines layer-specific merging coefficients based on mutual information between activations of pre-trained and fine-tuned models. ACM effectively preserves task-specific capabilities without requiring gradient computations or additional training. Extensive experiments on Long-to-Short (L2S) and general merging tasks demonstrate that ACM consistently outperforms all baseline methods. For instance, in the case of Qwen-7B models, TIES-Merging equipped with ACM achieves a \textbf{55.3\%} reduction in response length while simultaneously improving reasoning accuracy by \textbf{1.3} points. We submit the code with the paper for reproducibility, and it will be publicly available.
Beyond Standard MoE: Mixture of Latent Experts for Resource-Efficient Language Models
Mar 29, 2025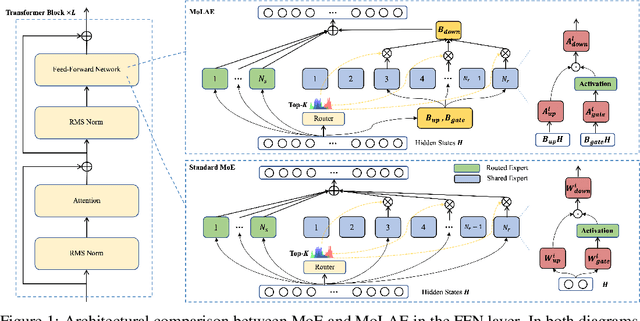


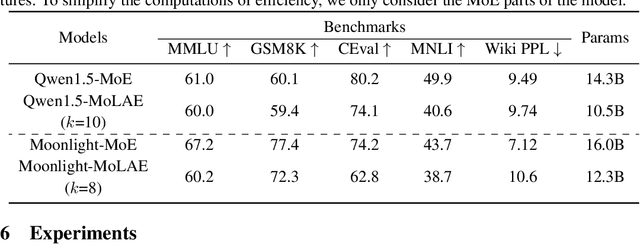
Mixture of Experts (MoE) has emerged as a pivotal architectural paradigm for efficient scaling of Large Language Models (LLMs), operating through selective activation of parameter subsets for each input token. Nevertheless, conventional MoE architectures encounter substantial challenges, including excessive memory utilization and communication overhead during training and inference, primarily attributable to the proliferation of expert modules. In this paper, we introduce Mixture of Latent Experts (MoLE), a novel parameterization methodology that facilitates the mapping of specific experts into a shared latent space. Specifically, all expert operations are systematically decomposed into two principal components: a shared projection into a lower-dimensional latent space, followed by expert-specific transformations with significantly reduced parametric complexity. This factorized approach substantially diminishes parameter count and computational requirements. Beyond the pretraining implementation of the MoLE architecture, we also establish a rigorous mathematical framework for transforming pre-trained MoE models into the MoLE architecture, characterizing the sufficient conditions for optimal factorization and developing a systematic two-phase algorithm for this conversion process. Our comprehensive theoretical analysis demonstrates that MoLE significantly enhances computational efficiency across multiple dimensions while preserving model representational capacity. Empirical evaluations corroborate our theoretical findings, confirming that MoLE achieves performance comparable to standard MoE implementations while substantially reducing resource requirements.
Unlocking Efficient Long-to-Short LLM Reasoning with Model Merging
Mar 26, 2025



The transition from System 1 to System 2 reasoning in large language models (LLMs) has marked significant advancements in handling complex tasks through deliberate, iterative thinking. However, this progress often comes at the cost of efficiency, as models tend to overthink, generating redundant reasoning steps without proportional improvements in output quality. Long-to-Short (L2S) reasoning has emerged as a promising solution to this challenge, aiming to balance reasoning depth with practical efficiency. While existing approaches, such as supervised fine-tuning (SFT), reinforcement learning (RL), and prompt engineering, have shown potential, they are either computationally expensive or unstable. Model merging, on the other hand, offers a cost-effective and robust alternative by integrating the quick-thinking capabilities of System 1 models with the methodical reasoning of System 2 models. In this work, we present a comprehensive empirical study on model merging for L2S reasoning, exploring diverse methodologies, including task-vector-based, SVD-based, and activation-informed merging. Our experiments reveal that model merging can reduce average response length by up to 55% while preserving or even improving baseline performance. We also identify a strong correlation between model scale and merging efficacy with extensive evaluations on 1.5B/7B/14B/32B models. Furthermore, we investigate the merged model's ability to self-critique and self-correct, as well as its adaptive response length based on task complexity. Our findings highlight model merging as a highly efficient and effective paradigm for L2S reasoning, offering a practical solution to the overthinking problem while maintaining the robustness of System 2 reasoning. This work can be found on Github https://github.com/hahahawu/Long-to-Short-via-Model-Merging.
ARS: Automatic Routing Solver with Large Language Models
Feb 21, 2025



Real-world Vehicle Routing Problems (VRPs) are characterized by a variety of practical constraints, making manual solver design both knowledge-intensive and time-consuming. Although there is increasing interest in automating the design of routing algorithms, existing research has explored only a limited array of VRP variants and fails to adequately address the complex and prevalent constraints encountered in real-world situations. To fill this gap, this paper introduces RoutBench, a benchmark of 1,000 VRP variants derived from 24 attributes, for evaluating the effectiveness of automatic routing solvers in addressing complex constraints. Along with RoutBench, we present the Automatic Routing Solver (ARS), which employs Large Language Model (LLM) agents to enhance a backbone algorithm framework by automatically generating constraint-aware heuristic code, based on problem descriptions and several representative constraints selected from a database. Our experiments show that ARS outperforms state-of-the-art LLM-based methods and commonly used solvers, automatically solving 91.67% of common VRPs and achieving at least a 30% improvement across all benchmarks.
Sens-Merging: Sensitivity-Guided Parameter Balancing for Merging Large Language Models
Feb 19, 2025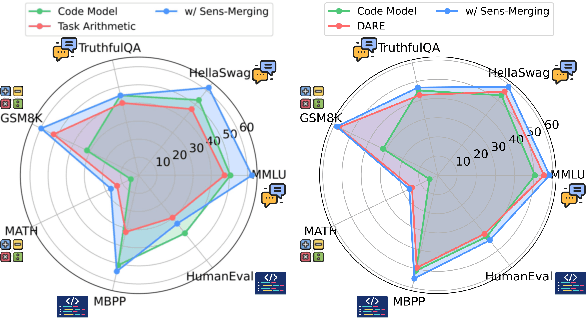
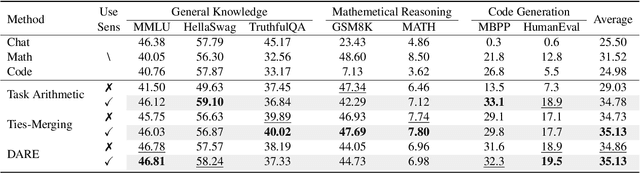
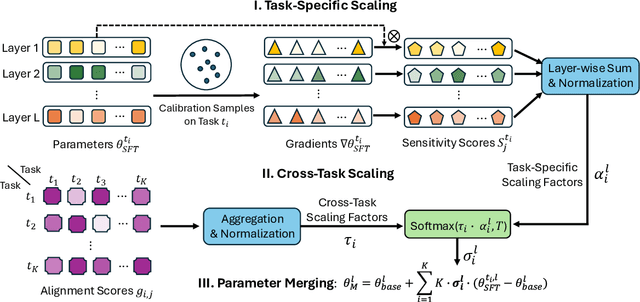
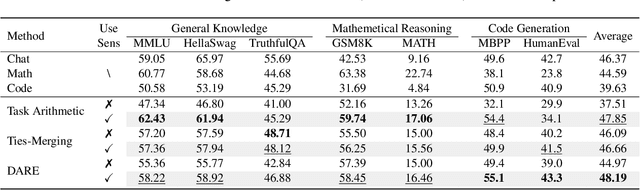
Recent advances in large language models have led to numerous task-specialized fine-tuned variants, creating a need for efficient model merging techniques that preserve specialized capabilities while avoiding costly retraining. While existing task vector-based merging methods show promise, they typically apply uniform coefficients across all parameters, overlooking varying parameter importance both within and across tasks. We present Sens-Merging, a sensitivity-guided coefficient adjustment method that enhances existing model merging techniques by operating at both task-specific and cross-task levels. Our method analyzes parameter sensitivity within individual tasks and evaluates cross-task transferability to determine optimal merging coefficients. Extensive experiments on Mistral 7B and LLaMA2-7B/13B models demonstrate that Sens-Merging significantly improves performance across general knowledge, mathematical reasoning, and code generation tasks. Notably, when combined with existing merging techniques, our method enables merged models to outperform specialized fine-tuned models, particularly in code generation tasks. Our findings reveal important trade-offs between task-specific and cross-task scalings, providing insights for future model merging strategies.
Fast and Interpretable Mixed-Integer Linear Program Solving by Learning Model Reduction
Dec 31, 2024



By exploiting the correlation between the structure and the solution of Mixed-Integer Linear Programming (MILP), Machine Learning (ML) has become a promising method for solving large-scale MILP problems. Existing ML-based MILP solvers mainly focus on end-to-end solution learning, which suffers from the scalability issue due to the high dimensionality of the solution space. Instead of directly learning the optimal solution, this paper aims to learn a reduced and equivalent model of the original MILP as an intermediate step. The reduced model often corresponds to interpretable operations and is much simpler, enabling us to solve large-scale MILP problems much faster than existing commercial solvers. However, current approaches rely only on the optimal reduced model, overlooking the significant preference information of all reduced models. To address this issue, this paper proposes a preference-based model reduction learning method, which considers the relative performance (i.e., objective cost and constraint feasibility) of all reduced models on each MILP instance as preferences. We also introduce an attention mechanism to capture and represent preference information, which helps improve the performance of model reduction learning tasks. Moreover, we propose a SetCover based pruning method to control the number of reduced models (i.e., labels), thereby simplifying the learning process. Evaluation on real-world MILP problems shows that 1) compared to the state-of-the-art model reduction ML methods, our method obtains nearly 20% improvement on solution accuracy, and 2) compared to the commercial solver Gurobi, two to four orders of magnitude speedups are achieved.
BPP-Search: Enhancing Tree of Thought Reasoning for Mathematical Modeling Problem Solving
Nov 26, 2024



LLMs exhibit advanced reasoning capabilities, offering the potential to transform natural language questions into mathematical models. However, existing open-source operations research datasets lack detailed annotations of the modeling process, such as variable definitions, focusing solely on objective values, which hinders reinforcement learning applications. To address this, we release the StructuredOR dataset, annotated with comprehensive labels that capture the complete mathematical modeling process. We further propose BPP-Search, a algorithm that integrates reinforcement learning into a tree-of-thought structure using Beam search, a Process reward model, and a pairwise Preference algorithm. This approach enables efficient exploration of tree structures, avoiding exhaustive search while improving accuracy. Extensive experiments on StructuredOR, NL4OPT, and MAMO-ComplexLP datasets show that BPP-Search significantly outperforms state-of-the-art methods, including Chain-of-Thought, Self-Consistency, and Tree-of-Thought. In tree-based reasoning, BPP-Search also surpasses Process Reward Model combined with Greedy or Beam Search, demonstrating superior accuracy and efficiency, and enabling faster retrieval of correct solutions.
Determine-Then-Ensemble: Necessity of Top-k Union for Large Language Model Ensembling
Oct 03, 2024



Large language models (LLMs) exhibit varying strengths and weaknesses across different tasks, prompting recent studies to explore the benefits of ensembling models to leverage their complementary advantages. However, existing LLM ensembling methods often overlook model compatibility and struggle with inefficient alignment of probabilities across the entire vocabulary. In this study, we empirically investigate the factors influencing ensemble performance, identifying model performance, vocabulary size, and response style as key determinants, revealing that compatibility among models is essential for effective ensembling. This analysis leads to the development of a simple yet effective model selection strategy that identifies compatible models. Additionally, we introduce the \textsc{Uni}on \textsc{T}op-$k$ \textsc{E}nsembling (\textsc{UniTE}), a novel approach that efficiently combines models by focusing on the union of the top-k tokens from each model, thereby avoiding the need for full vocabulary alignment and reducing computational overhead. Extensive evaluations across multiple benchmarks demonstrate that \textsc{UniTE} significantly enhances performance compared to existing methods, offering a more efficient framework for LLM ensembling.
Large Language Models are Good Multi-lingual Learners : When LLMs Meet Cross-lingual Prompts
Sep 17, 2024



With the advent of Large Language Models (LLMs), generating rule-based data for real-world applications has become more accessible. Due to the inherent ambiguity of natural language and the complexity of rule sets, especially in long contexts, LLMs often struggle to follow all specified rules, frequently omitting at least one. To enhance the reasoning and understanding of LLMs on long and complex contexts, we propose a novel prompting strategy Multi-Lingual Prompt, namely MLPrompt, which automatically translates the error-prone rule that an LLM struggles to follow into another language, thus drawing greater attention to it. Experimental results on public datasets across various tasks have shown MLPrompt can outperform state-of-the-art prompting methods such as Chain of Thought, Tree of Thought, and Self-Consistency. Additionally, we introduce a framework integrating MLPrompt with an auto-checking mechanism for structured data generation, with a specific case study in text-to-MIP instances. Further, we extend the proposed framework for text-to-SQL to demonstrate its generation ability towards structured data synthesis.