 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAGE: Strategy-Adaptive Generation Engine for Query Rewriting
Jun 24, 2025Query rewriting is pivotal for enhancing dense retrieval, yet current methods demand large-scale supervised data or suffer from inefficient reinforcement learning (RL) exploration. In this work, we first establish that guiding Large Language Models (LLMs) with a concise set of expert-crafted strategies, such as semantic expansion and entity disambiguation, substantially improves retrieval effectiveness on challenging benchmarks, including HotpotQA, FEVER, NFCorpus, and SciFact. Building on this insight, we introduce the Strategy-Adaptive Generation Engine (SAGE), which operationalizes these strategies in an RL framework. SAGE introduces two novel reward shaping mechanisms-Strategic Credit Shaping (SCS) and Contrastive Reward Shaping (CRS)-to deliver more informative learning signals. This strategy-guided approach not only achieves new state-of-the-art NDCG@10 results, but also uncovers a compelling emergent behavior: the agent learns to select optimal strategies, reduces unnecessary exploration, and generates concise rewrites, lowering inference cost without sacrificing performance. Our findings demonstrate that strategy-guided RL, enhanced with nuanced reward shaping, offers a scalable, efficient, and more interpretable paradigm for developing the next generation of robust information retrieval systems.
Towards Hierarchical Multi-Step Reward Models for Enhanced Reasoning in Large Language Models
Mar 19, 2025
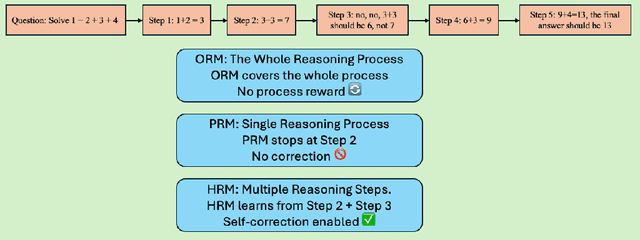
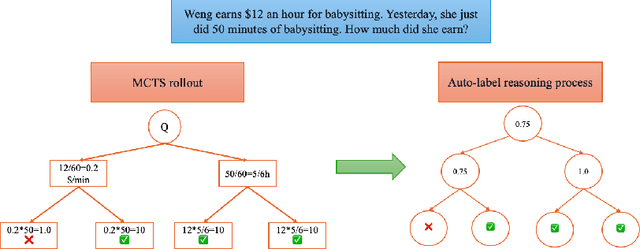

Recent studies show that Large Language Models (LLMs) achieve strong reasoning capabilities through supervised fine-tuning or reinforcement learning. However, a key approach, the Process Reward Model (PRM), suffers from reward hacking, making it unreliable in identifying the best intermediate steps. In this paper, we propose a novel reward model approach, Hierarchical Reward Model (HRM), which evaluates both individual and consecutive reasoning steps from fine-grained and coarse-grained level. HRM performs better in assessing reasoning coherence and self-reflection, particularly when the previous reasoning step is incorrect. Furthermore, to address the inefficiency of autonomous generating PRM training data via Monte Carlo Tree Search (MCTS), we introduce a lightweight and effective data augmentation strategy called Hierarchical Node Compression (HNC) based on node merging (combining two consecutive reasoning steps into one step) in the tree structure. This approach diversifies MCTS results for HRM with negligible computational overhead, enhancing label robustness by introducing noise. Empirical results on the PRM800K dataset demonstrate that HRM, in conjunction with HNC, achieves superior stability and reliability in evaluation compared to PRM. Furthermore, cross-domain evaluations on MATH500 and GSM8K confirm HRM's superior generalization and robustness across diverse reasoning tasks. The code for all experiments will be released at https: //github.com/tengwang0318/hierarchial_reward_model.
BPP-Search: Enhancing Tree of Thought Reasoning for Mathematical Modeling Problem Solving
Nov 26, 2024



LLMs exhibit advanced reasoning capabilities, offering the potential to transform natural language questions into mathematical models. However, existing open-source operations research datasets lack detailed annotations of the modeling process, such as variable definitions, focusing solely on objective values, which hinders reinforcement learning applications. To address this, we release the StructuredOR dataset, annotated with comprehensive labels that capture the complete mathematical modeling process. We further propose BPP-Search, a algorithm that integrates reinforcement learning into a tree-of-thought structure using Beam search, a Process reward model, and a pairwise Preference algorithm. This approach enables efficient exploration of tree structures, avoiding exhaustive search while improving accuracy. Extensive experiments on StructuredOR, NL4OPT, and MAMO-ComplexLP datasets show that BPP-Search significantly outperforms state-of-the-art methods, including Chain-of-Thought, Self-Consistency, and Tree-of-Thought. In tree-based reasoning, BPP-Search also surpasses Process Reward Model combined with Greedy or Beam Search, demonstrating superior accuracy and efficiency, and enabling faster retrieval of correct solutions.