 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDolphin-v2: Universal Document Parsing via Scalable Anchor Prompting
Feb 05, 2026Document parsing has garnered widespread attention as vision-language models (VLMs) advance OCR capabilities. However, the field remains fragmented across dozens of specialized models with varying strengths, forcing users to navigate complex model selection and limiting system scalability. Moreover, existing two-stage approaches depend on axis-aligned bounding boxes for layout detection, failing to handle distorted or photographed documents effectively. To this end, we present Dolphin-v2, a two-stage document image parsing model that substantially improves upon the original Dolphin. In the first stage, Dolphin-v2 jointly performs document type classification (digital-born versus photographed) alongside layout analysis. For digital-born documents, it conducts finer-grained element detection with reading order prediction. In the second stage, we employ a hybrid parsing strategy: photographed documents are parsed holistically as complete pages to handle geometric distortions, while digital-born documents undergo element-wise parallel parsing guided by the detected layout anchors, enabling efficient content extraction. Compared with the original Dolphin, Dolphin-v2 introduces several crucial enhancements: (1) robust parsing of photographed documents via holistic page-level understanding, (2) finer-grained element detection (21 categories) with semantic attribute extraction such as author information and document metadata, and (3) code block recognition with indentation preservation, which existing systems typically lack. Comprehensive evaluations are conducted on DocPTBench, OmniDocBench, and our self-constructed RealDoc-160 benchmark. The results demonstrate substantial improvements: +14.78 points overall on the challenging OmniDocBench and 91% error reduction on photographed documents, while maintaining efficient inference through parallel processing.
LongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
Flexible-Duplex Cell-Free Architecture for Secure Uplink Communications in Low-Altitude Wireless Networks
Jan 07, 2026Low-altitude wireless networks (LAWNs) are expected to play a central role in future 6G infrastructures, yet uplink transmissions of uncrewed aerial vehicles (UAVs) remain vulnerable to eavesdropping due to their limited transmit power, constrained antenna resources, and highly exposed air-ground propagation conditions. To address this fundamental bottleneck, we propose a flexible-duplex cell-free (CF) architecture in which each distributed access point (AP) can dynamically operate either as a receive AP for UAV uplink collection or as a transmit AP that generates cooperative artificial noise (AN) for secrecy enhancement. Such AP-level duplex flexibility introduces an additional spatial degree of freedom that enables distributed and adaptive protection against wiretapping in LAWNs. Building upon this architecture, we formulate a max-min secrecy-rate problem that jointly optimizes AP mode selection, receive combining, and AN covariance design. This tightly coupled and nonconvex optimization is tackled by first deriving the optimal receive combiners in closed form, followed by developing a penalty dual decomposition (PDD) algorithm with guaranteed convergence to a stationary solution. To further reduce computational burden, we propose a low-complexity sequential scheme that determines AP modes via a heuristic metric and then updates the AN covariance matrices through closed-form iterations embedded in the PDD framework. Simulation results show that the proposed flexible-duplex architecture yields substantial secrecy-rate gains over CF systems with fixed AP roles. The joint optimization method attains the highest secrecy performance, while the low-complexity approach achieves over 90% of the optimal performance with an order-of-magnitude lower computational complexity, offering a practical solution for secure uplink communications in LAWNs.
Digitalizing Over-the-Air Computation via The Novel Complement Coded Modulation
Dec 31, 2025To overcome inherent limitations of analog signals in over-the-air computation (AirComp), this letter proposes a two's complement-based coding scheme for the AirComp implementation with compatible digital modulations. Specifically, quantized discrete values are encoded into binary sequences using the two's complement and transmitted over multiple subcarriers. At the receiver, we design a decoder that constructs a functional mapping between the superimposed digital modulation signals and the target of computational results, theoretically ensuring asymptotic error free computation with the minimal codeword length. To further mitigate the adverse effects of channel fading, we adopt a truncated inversion strategy for pre-processing. Benefiting from the unified symbol distribution after the proposed encoding, we derive the optimal linear minimum mean squared error (LMMSE) detector in closed form and propose a low complexity algorithm seeking for the optimal truncation selection. Furthermore, the inherent importance differences among the coded outputs motivate an uneven power allocation strategy across subcarriers to improve computational accuracy. Numerical results validate the superiority of the proposed scheme over existing digital AirComp approaches, especially at low signal to-noise ratio (SNR) regimes.
UniRec-0.1B: Unified Text and Formula Recognition with 0.1B Parameters
Dec 24, 2025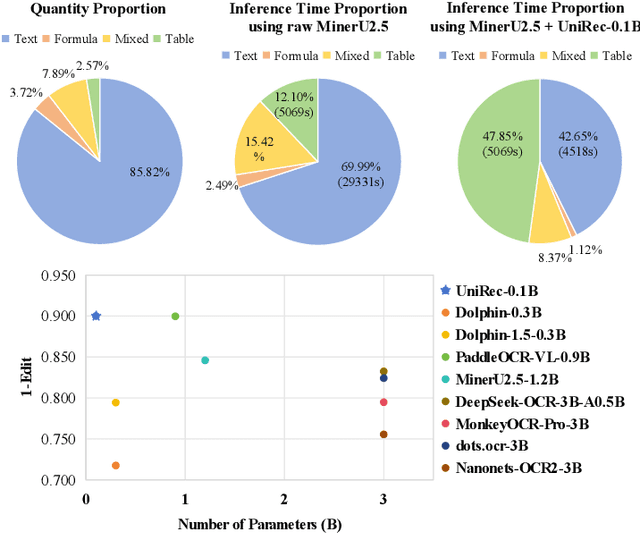

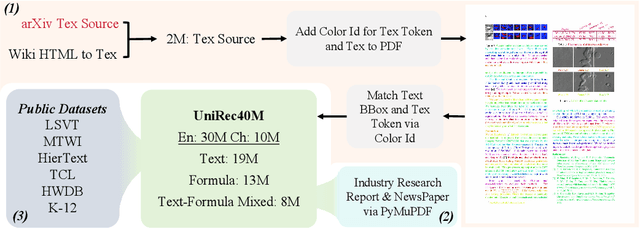
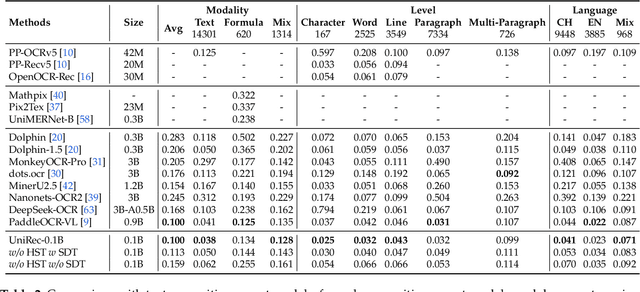
Text and formulas constitute the core informational components of many documents. Accurately and efficiently recognizing both is crucial for developing robust and generalizable document parsing systems. Recently, vision-language models (VLMs) have achieved impressive unified recognition of text and formulas. However, they are large-sized and computationally demanding, restricting their usage in many applications. In this paper, we propose UniRec-0.1B, a unified recognition model with only 0.1B parameters. It is capable of performing text and formula recognition at multiple levels, including characters, words, lines, paragraphs, and documents. To implement this task, we first establish UniRec40M, a large-scale dataset comprises 40 million text, formula and their mix samples, enabling the training of a powerful yet lightweight model. Secondly, we identify two challenges when building such a lightweight but unified expert model. They are: structural variability across hierarchies and semantic entanglement between textual and formulaic content. To tackle these, we introduce a hierarchical supervision training that explicitly guides structural comprehension, and a semantic-decoupled tokenizer that separates text and formula representations. Finally, we develop a comprehensive evaluation benchmark covering Chinese and English documents from multiple domains and with multiple levels. Experimental results on this and public benchmarks demonstrate that UniRec-0.1B outperforms both general-purpose VLMs and leading document parsing expert models, while achieving a 2-9$\times$ speedup, validating its effectiveness and efficiency. Codebase and Dataset: https://github.com/Topdu/OpenOCR.
Interpretable Reward Model via Sparse Autoencoder
Aug 12, 2025Large language models (LLMs) have been widely deployed across numerous fields. Reinforcement Learning from Human Feedback (RLHF) leverages reward models (RMs) as proxies for human preferences to align LLM behaviors with human values, making the accuracy, reliability, and interpretability of RMs critical for effective alignment. However, traditional RMs lack interpretability, offer limited insight into the reasoning behind reward assignments, and are inflexible toward user preference shifts. While recent multidimensional RMs aim for improved interpretability, they often fail to provide feature-level attribution and require costly annotations. To overcome these limitations, we introduce the Sparse Autoencoder-enhanced Reward Model (\textbf{SARM}), a novel architecture that integrates a pretrained Sparse Autoencoder (SAE) into a reward model. SARM maps the hidden activations of LLM-based RM into an interpretable, sparse, and monosemantic feature space, from which a scalar head aggregates feature activations to produce transparent and conceptually meaningful reward scores. Empirical evaluations demonstrate that SARM facilitates direct feature-level attribution of reward assignments, allows dynamic adjustment to preference shifts, and achieves superior alignment performance compared to conventional reward models. Our code is available at https://github.com/schrieffer-z/sarm.
Post-Completion Learning for Language Models
Jul 27, 2025Current language model training paradigms typically terminate learning upon reaching the end-of-sequence (<eos>}) token, overlooking the potential learning opportunities in the post-completion space. We propose Post-Completion Learning (PCL), a novel training framework that systematically utilizes the sequence space after model output completion, to enhance both the reasoning and self-evaluation abilities. PCL enables models to continue generating self-assessments and reward predictions during training, while maintaining efficient inference by stopping at the completion point. To fully utilize this post-completion space, we design a white-box reinforcement learning method: let the model evaluate the output content according to the reward rules, then calculate and align the score with the reward functions for supervision. We implement dual-track SFT to optimize both reasoning and evaluation capabilities, and mixed it with RL training to achieve multi-objective hybrid optimization. Experimental results on different datasets and models demonstrate consistent improvements over traditional SFT and RL methods. Our method provides a new technical path for language model training that enhances output quality while preserving deployment efficiency.
Dolphin: Document Image Parsing via Heterogeneous Anchor Prompting
May 20, 2025Document image parsing is challenging due to its complexly intertwined elements such as text paragraphs, figures, formulas, and tables. Current approaches either assemble specialized expert models or directly generate page-level content autoregressively, facing integration overhead, efficiency bottlenecks, and layout structure degradation despite their decent performance. To address these limitations, we present \textit{Dolphin} (\textit{\textbf{Do}cument Image \textbf{P}arsing via \textbf{H}eterogeneous Anchor Prompt\textbf{in}g}), a novel multimodal document image parsing model following an analyze-then-parse paradigm. In the first stage, Dolphin generates a sequence of layout elements in reading order. These heterogeneous elements, serving as anchors and coupled with task-specific prompts, are fed back to Dolphin for parallel content parsing in the second stage. To train Dolphin, we construct a large-scale dataset of over 30 million samples, covering multi-granularity parsing tasks. Through comprehensive evaluations on both prevalent benchmarks and self-constructed ones, Dolphin achieves state-of-the-art performance across diverse page-level and element-level settings, while ensuring superior efficiency through its lightweight architecture and parallel parsing mechanism. The code and pre-trained models are publicly available at https://github.com/ByteDance/Dolphin
Advancing Sequential Numerical Prediction in Autoregressive Models
May 19, 2025Autoregressive models have become the de facto choice for sequence generation tasks, but standard approaches treat digits as independent tokens and apply cross-entropy loss, overlooking the coherent structure of numerical sequences. This paper introduces Numerical Token Integrity Loss (NTIL) to address this gap. NTIL operates at two levels: (1) token-level, where it extends the Earth Mover's Distance (EMD) to preserve ordinal relationships between numerical values, and (2) sequence-level, where it penalizes the overall discrepancy between the predicted and actual sequences. This dual approach improves numerical prediction and integrates effectively with LLMs/MLLMs. Extensive experiments show significant performance improvements with NTIL.
InstructRAG: Leveraging Retrieval-Augmented Generation on Instruction Graphs for LLM-Based Task Planning
Apr 17, 2025Recent advancements in large language models (LLMs) have enabled their use as agents for planning complex tasks. Existing methods typically rely on a thought-action-observation (TAO) process to enhance LLM performance, but these approaches are often constrained by the LLMs' limited knowledge of complex tasks. Retrieval-augmented generation (RAG) offers new opportunities by leveraging external databases to ground generation in retrieved information. In this paper, we identify two key challenges (enlargability and transferability) in applying RAG to task planning. We propose InstructRAG, a novel solution within a multi-agent meta-reinforcement learning framework, to address these challenges. InstructRAG includes a graph to organize past instruction paths (sequences of correct actions), an RL-Agent with Reinforcement Learning to expand graph coverage for enlargability, and an ML-Agent with Meta-Learning to improve task generalization for transferability. The two agents are trained end-to-end to optimize overall planning performance. Our experiments on four widely used task planning datasets demonstrate that InstructRAG significantly enhances performance and adapts efficiently to new tasks, achieving up to a 19.2% improvement over the best existing approach.