 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProlonged Reasoning Is Not All You Need: Certainty-Based Adaptive Routing for Efficient LLM/MLLM Reasoning
May 21, 2025



Recent advancements in reasoning have significantly enhanced the capabilities of Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) across diverse tasks. However, excessive reliance on chain-of-thought (CoT) reasoning can impair model performance and brings unnecessarily lengthened outputs, reducing efficiency. Our work reveals that prolonged reasoning does not universally improve accuracy and even degrade performance on simpler tasks. To address this, we propose Certainty-based Adaptive Reasoning (CAR), a novel framework that dynamically switches between short answers and long-form reasoning based on the model perplexity. CAR first generates a short answer and evaluates its perplexity, triggering reasoning only when the model exhibits low confidence (i.e., high perplexity). Experiments across diverse multimodal VQA/KIE benchmarks and text reasoning datasets show that CAR outperforms both short-answer and long-form reasoning approaches, striking an optimal balance between accuracy and efficiency.
OCRBench v2: An Improved Benchmark for Evaluating Large Multimodal Models on Visual Text Localization and Reasoning
Dec 31, 2024



Scoring the Optical Character Recognition (OCR) capabilities of Large Multimodal Models (LMMs) has witnessed growing interest recently. Existing benchmarks have highlighted the impressive performance of LMMs in text recognition; however, their abilities on certain challenging tasks, such as text localization, handwritten content extraction, and logical reasoning, remain underexplored. To bridge this gap, we introduce OCRBench v2, a large-scale bilingual text-centric benchmark with currently the most comprehensive set of tasks (4x more tasks than the previous multi-scene benchmark OCRBench), the widest coverage of scenarios (31 diverse scenarios including street scene, receipt, formula, diagram, and so on), and thorough evaluation metrics, with a total of 10,000 human-verified question-answering pairs and a high proportion of difficult samples. After carefully benchmarking state-of-the-art LMMs on OCRBench v2, we find that 20 out of 22 LMMs score below 50 (100 in total) and suffer from five-type limitations, including less frequently encountered text recognition, fine-grained perception, layout perception, complex element parsing, and logical reasoning. The benchmark and evaluation scripts are available at https://github.com/Yuliang-liu/MultimodalOCR.
MCTBench: Multimodal Cognition towards Text-Rich Visual Scenes Benchmark
Oct 15, 2024The comprehension of text-rich visual scenes has become a focal point for evaluating Multi-modal Large Language Models (MLLMs) due to their widespread applications. Current benchmarks tailored to the scenario emphasize perceptual capabilities, while overlooking the assessment of cognitive abilities. To address this limitation, we introduce a Multimodal benchmark towards Text-rich visual scenes, to evaluate the Cognitive capabilities of MLLMs through visual reasoning and content-creation tasks (MCTBench). To mitigate potential evaluation bias from the varying distributions of datasets, MCTBench incorporates several perception tasks (e.g., scene text recognition) to ensure a consistent comparison of both the cognitive and perceptual capabilities of MLLMs. To improve the efficiency and fairness of content-creation evaluation, we conduct an automatic evaluation pipeline. Evaluations of various MLLMs on MCTBench reveal that, despite their impressive perceptual capabilities, their cognition abilities require enhancement. We hope MCTBench will offer the community an efficient resource to explore and enhance cognitive capabilities towards text-rich visual scenes.
ParGo: Bridging Vision-Language with Partial and Global Views
Aug 23, 2024This work presents ParGo, a novel Partial-Global projector designed to connect the vision and language modalities for Multimodal Large Language Models (MLLMs). Unlike previous works that rely on global attention-based projectors, our ParGo bridges the representation gap between the separately pre-trained vision encoders and the LLMs by integrating global and partial views, which alleviates the overemphasis on prominent regions. To facilitate the effective training of ParGo, we collect a large-scale detail-captioned image-text dataset named ParGoCap-1M-PT, consisting of 1 million images paired with high-quality captions. Extensive experiments on several MLLM benchmarks demonstrate the effectiveness of our ParGo, highlighting its superiority in aligning vision and language modalities. Compared to conventional Q-Former projector, our ParGo achieves an improvement of 259.96 in MME benchmark. Furthermore, our experiments reveal that ParGo significantly outperforms other projectors, particularly in tasks that emphasize detail perception ability.
Bi-VLDoc: Bidirectional Vision-Language Modeling for Visually-Rich Document Understanding
Jun 27, 2022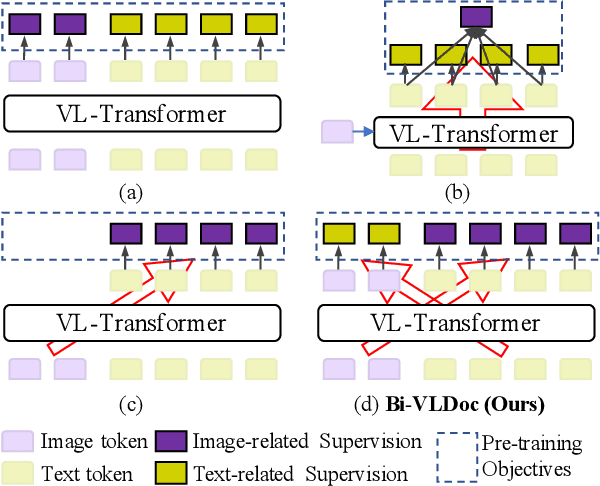
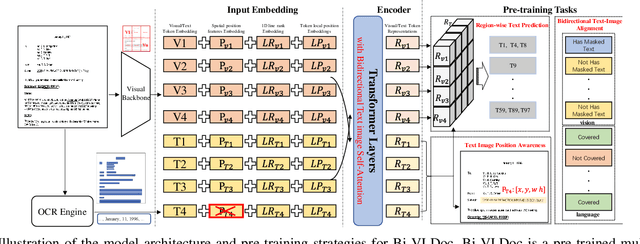
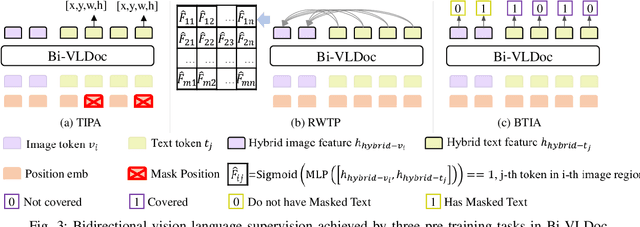
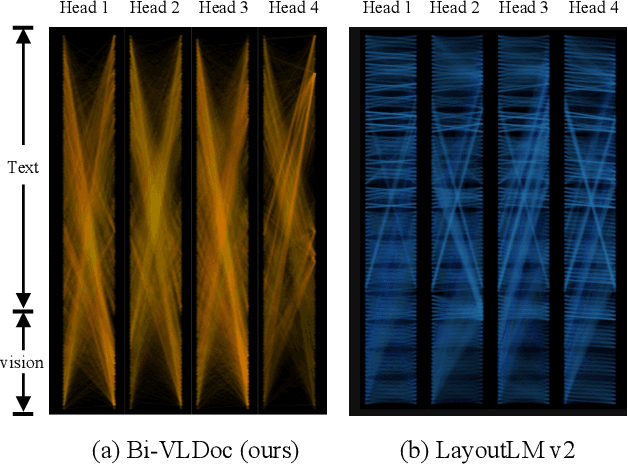
Multi-modal document pre-trained models have proven to be very effective in a variety of visually-rich document understanding (VrDU) tasks. Though existing document pre-trained models have achieved excellent performance on standard benchmarks for VrDU, the way they model and exploit the interactions between vision and language on documents has hindered them from better generalization ability and higher accuracy. In this work, we investigate the problem of vision-language joint representation learning for VrDU mainly from the perspective of supervisory signals. Specifically, a pre-training paradigm called Bi-VLDoc is proposed, in which a bidirectional vision-language supervision strategy and a vision-language hybrid-attention mechanism are devised to fully explore and utilize the interactions between these two modalities, to learn stronger cross-modal document representations with richer semantics. Benefiting from the learned informative cross-modal document representations, Bi-VLDoc significantly advances the state-of-the-art performance on three widely-used document understanding benchmarks, including Form Understanding (from 85.14% to 93.44%), Receipt Information Extraction (from 96.01% to 97.84%), and Document Classification (from 96.08% to 97.12%). On Document Visual QA, Bi-VLDoc achieves the state-of-the-art performance compared to previous single model methods.
MatchVIE: Exploiting Match Relevancy between Entities for Visual Information Extraction
Jun 24, 2021


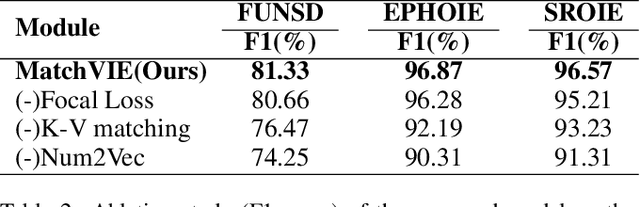
Visual Information Extraction (VIE) task aims to extract key information from multifarious document images (e.g., invoices and purchase receipts). Most previous methods treat the VIE task simply as a sequence labeling problem or classification problem, which requires models to carefully identify each kind of semantics by introducing multimodal features, such as font, color, layout. But simply introducing multimodal features couldn't work well when faced with numeric semantic categories or some ambiguous texts. To address this issue, in this paper we propose a novel key-value matching model based on a graph neural network for VIE (MatchVIE). Through key-value matching based on relevancy evaluation, the proposed MatchVIE can bypass the recognitions to various semantics, and simply focuses on the strong relevancy between entities. Besides, we introduce a simple but effective operation, Num2Vec, to tackle the instability of encoded values, which helps model converge more smoothly. Comprehensive experiments demonstrate that the proposed MatchVIE can significantly outperform previous methods. Notably, to the best of our knowledge, MatchVIE may be the first attempt to tackle the VIE task by modeling the relevancy between keys and values and it is a good complement to the existing methods.
Tag, Copy or Predict: A Unified Weakly-Supervised Learning Framework for Visual Information Extraction using Sequences
Jun 20, 2021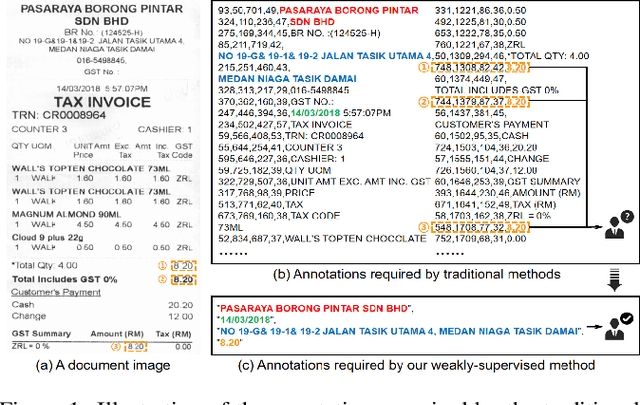
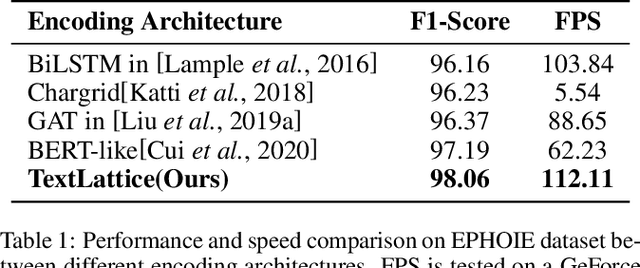
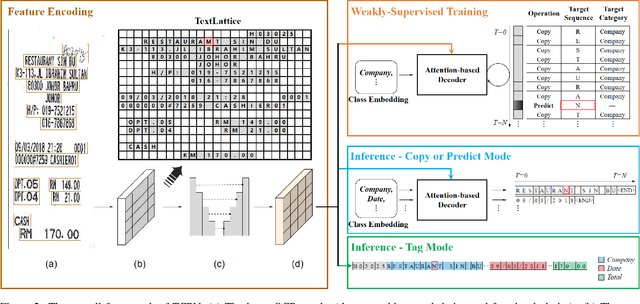

Visual information extraction (VIE) has attracted increasing attention in recent years. The existing methods usually first organized optical character recognition (OCR) results into plain texts and then utilized token-level entity annotations as supervision to train a sequence tagging model. However, it expends great annotation costs and may be exposed to label confusion, and the OCR errors will also significantly affect the final performance. In this paper, we propose a unified weakly-supervised learning framework called TCPN (Tag, Copy or Predict Network), which introduces 1) an efficient encoder to simultaneously model the semantic and layout information in 2D OCR results; 2) a weakly-supervised training strategy that utilizes only key information sequences as supervision; and 3) a flexible and switchable decoder which contains two inference modes: one (Copy or Predict Mode) is to output key information sequences of different categories by copying a token from the input or predicting one in each time step, and the other (Tag Mode) is to directly tag the input sequence in a single forward pass. Our method shows new state-of-the-art performance on several public benchmarks, which fully proves its effectiveness.
Towards Robust Visual Information Extraction in Real World: New Dataset and Novel Solution
Jan 24, 2021

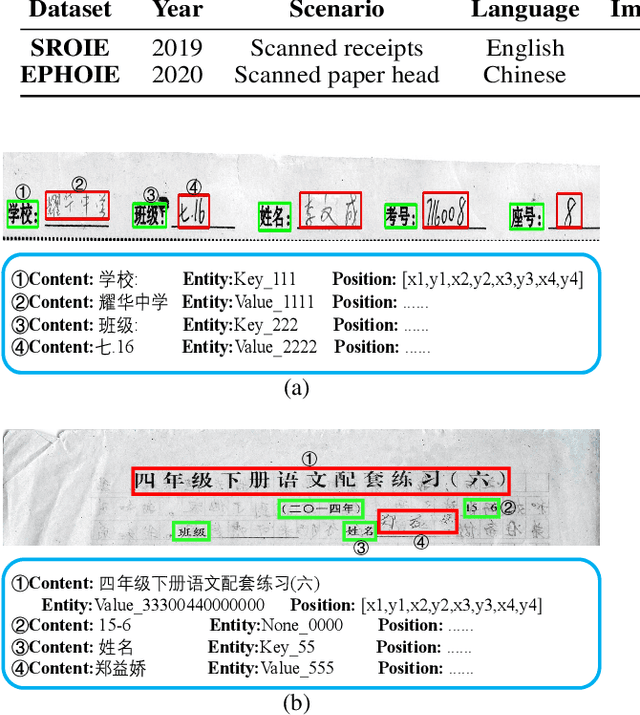
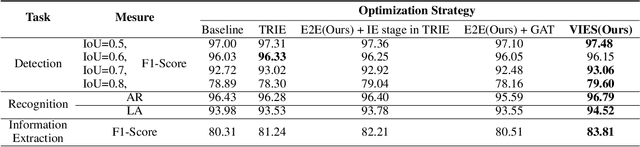
Visual information extraction (VIE) has attracted considerable attention recently owing to its various advanced applications such as document understanding, automatic marking and intelligent education. Most existing works decoupled this problem into several independent sub-tasks of text spotting (text detection and recognition) and information extraction, which completely ignored the high correlation among them during optimization. In this paper, we propose a robust visual information extraction system (VIES) towards real-world scenarios, which is a unified end-to-end trainable framework for simultaneous text detection, recognition and information extraction by taking a single document image as input and outputting the structured information. Specifically, the information extraction branch collects abundant visual and semantic representations from text spotting for multimodal feature fusion and conversely, provides higher-level semantic clues to contribute to the optimization of text spotting. Moreover, regarding the shortage of public benchmarks, we construct a fully-annotated dataset called EPHOIE (https://github.com/HCIILAB/EPHOIE), which is the first Chinese benchmark for both text spotting and visual information extraction. EPHOIE consists of 1,494 images of examination paper head with complex layouts and background, including a total of 15,771 Chinese handwritten or printed text instances. Compared with the state-of-the-art methods, our VIES shows significant superior performance on the EPHOIE dataset and achieves a 9.01% F-score gain on the widely used SROIE dataset under the end-to-end scenario.