 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Text Image Generation with Diffusion Models
Jun 19, 2023Current text recognition systems, including those for handwritten scripts and scene text, have relied heavily on image synthesis and augmentation, since it is difficult to realize real-world complexity and diversity through collecting and annotating enough real text images. In this paper, we explore the problem of text image generation, by taking advantage of the powerful abilities of Diffusion Models in generating photo-realistic and diverse image samples with given conditions, and propose a method called Conditional Text Image Generation with Diffusion Models (CTIG-DM for short). To conform to the characteristics of text images, we devise three conditions: image condition, text condition, and style condition, which can be used to control the attributes, contents, and styles of the samples in the image generation process. Specifically, four text image generation modes, namely: (1) synthesis mode, (2) augmentation mode, (3) recovery mode, and (4) imitation mode, can be derived by combining and configuring these three conditions. Extensive experiments on both handwritten and scene text demonstrate that the proposed CTIG-DM is able to produce image samples that simulate real-world complexity and diversity, and thus can boost the performance of existing text recognizers. Besides, CTIG-DM shows its appealing potential in domain adaptation and generating images containing Out-Of-Vocabulary (OOV) words.
Tag, Copy or Predict: A Unified Weakly-Supervised Learning Framework for Visual Information Extraction using Sequences
Jun 20, 2021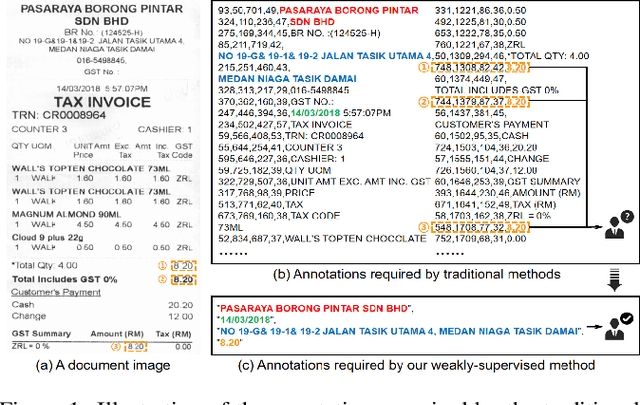
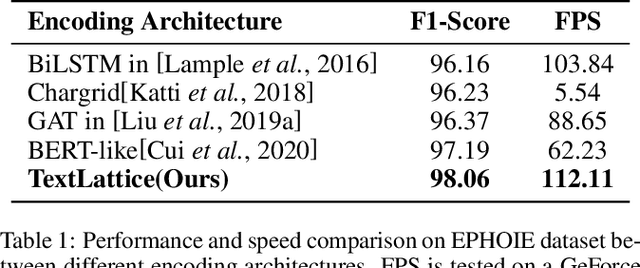
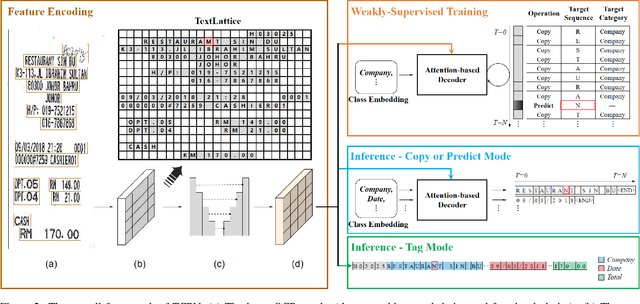

Visual information extraction (VIE) has attracted increasing attention in recent years. The existing methods usually first organized optical character recognition (OCR) results into plain texts and then utilized token-level entity annotations as supervision to train a sequence tagging model. However, it expends great annotation costs and may be exposed to label confusion, and the OCR errors will also significantly affect the final performance. In this paper, we propose a unified weakly-supervised learning framework called TCPN (Tag, Copy or Predict Network), which introduces 1) an efficient encoder to simultaneously model the semantic and layout information in 2D OCR results; 2) a weakly-supervised training strategy that utilizes only key information sequences as supervision; and 3) a flexible and switchable decoder which contains two inference modes: one (Copy or Predict Mode) is to output key information sequences of different categories by copying a token from the input or predicting one in each time step, and the other (Tag Mode) is to directly tag the input sequence in a single forward pass. Our method shows new state-of-the-art performance on several public benchmarks, which fully proves its effectiveness.
Implicit Feature Alignment: Learn to Convert Text Recognizer to Text Spotter
Jun 10, 2021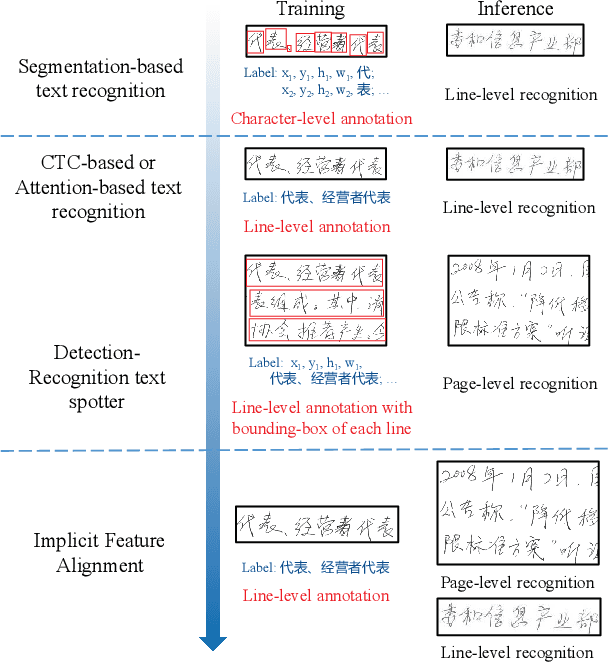
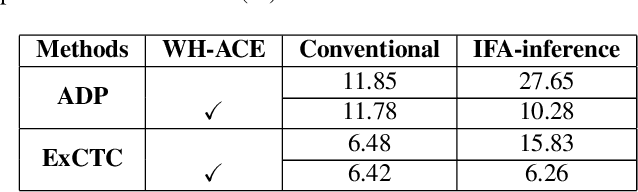
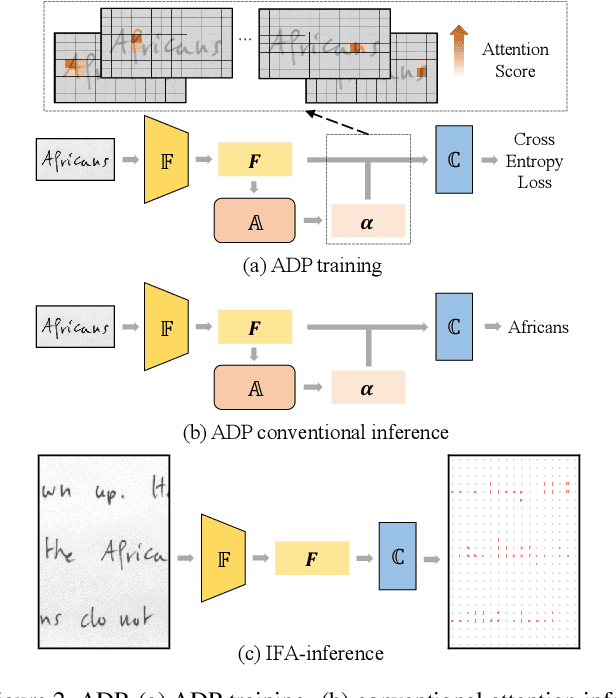
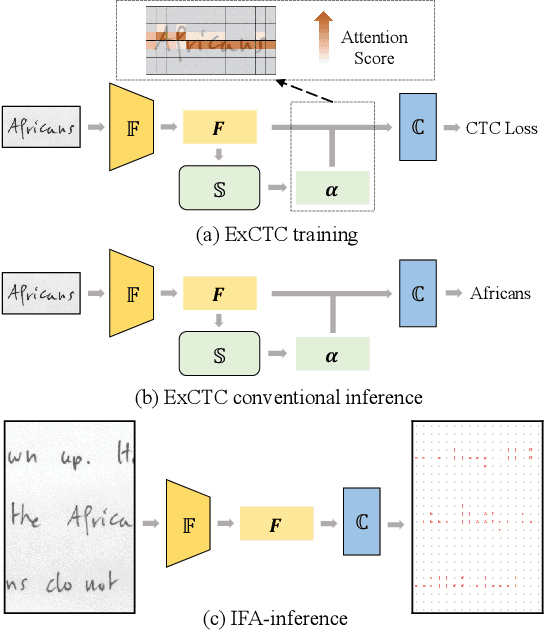
Text recognition is a popular research subject with many associated challenges. Despite the considerable progress made in recent years, the text recognition task itself is still constrained to solve the problem of reading cropped line text images and serves as a subtask of optical character recognition (OCR) systems. As a result, the final text recognition result is limited by the performance of the text detector. In this paper, we propose a simple, elegant and effective paradigm called Implicit Feature Alignment (IFA), which can be easily integrated into current text recognizers, resulting in a novel inference mechanism called IFAinference. This enables an ordinary text recognizer to process multi-line text such that text detection can be completely freed. Specifically, we integrate IFA into the two most prevailing text recognition streams (attention-based and CTC-based) and propose attention-guided dense prediction (ADP) and Extended CTC (ExCTC). Furthermore, the Wasserstein-based Hollow Aggregation Cross-Entropy (WH-ACE) is proposed to suppress negative predictions to assist in training ADP and ExCTC. We experimentally demonstrate that IFA achieves state-of-the-art performance on end-to-end document recognition tasks while maintaining the fastest speed, and ADP and ExCTC complement each other on the perspective of different application scenarios. Code will be available at https://github.com/WangTianwei/Implicit-feature-alignment.
Text Recognition in the Wild: A Survey
May 07, 2020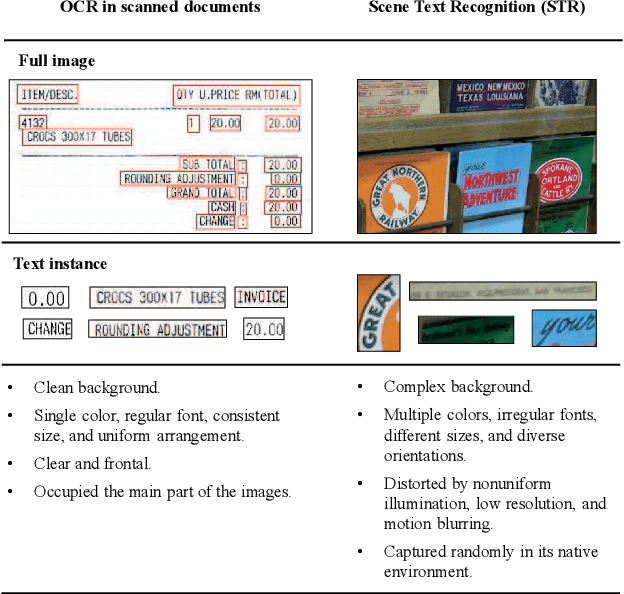
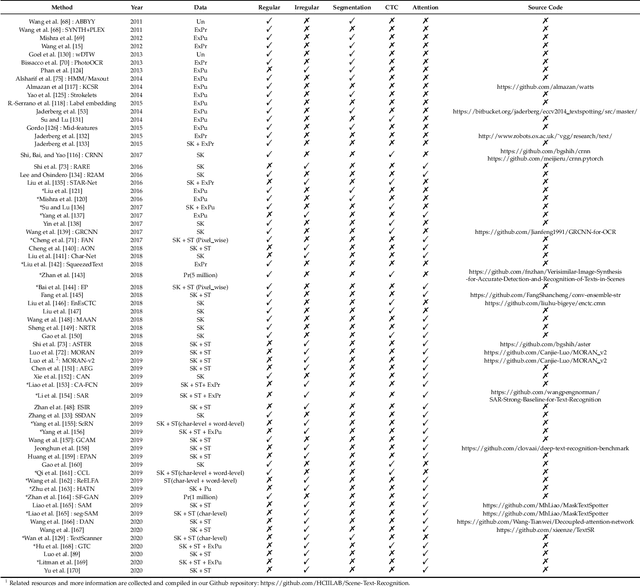

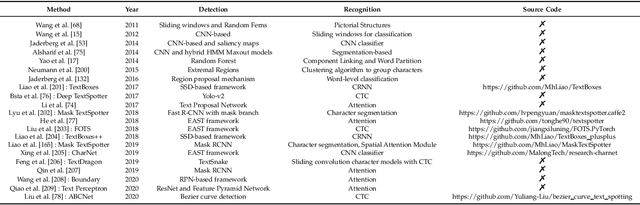
The history of text can be traced back over thousands of years. Rich and precise semantic information carried by text is important in a wide range of vision-based application scenarios. Therefore, text recognition in natural scenes has been an active research field in computer vision and pattern recognition. In recent years, with the rise and development of deep learning, numerous methods have shown promising in terms of innovation, practicality, and efficiency. This paper aims to (1) summarize the fundamental problems and the state-of-the-art associated with scene text recognition; (2) introduce new insights and ideas; (3) provide a comprehensive review of publicly available resources; (4) point out directions for future work. In summary, this literature review attempts to present the entire picture of the field of scene text recognition. It provides a comprehensive reference for people entering this field, and could be helpful to inspire future research. Related resources are available at our Github repository: https://github.com/HCIILAB/Scene-Text-Recognition.
Decoupled Attention Network for Text Recognition
Dec 21, 2019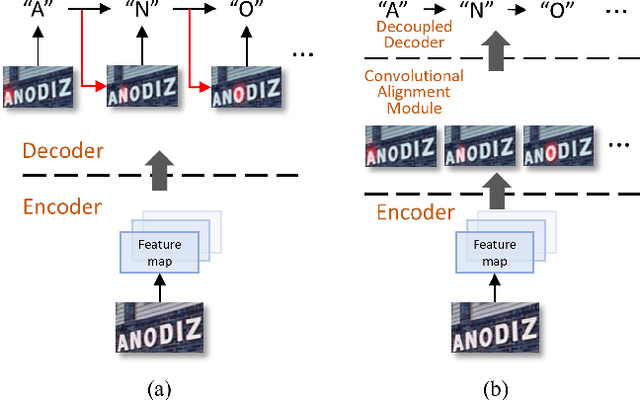
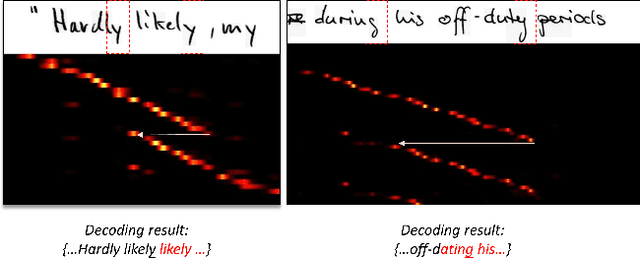
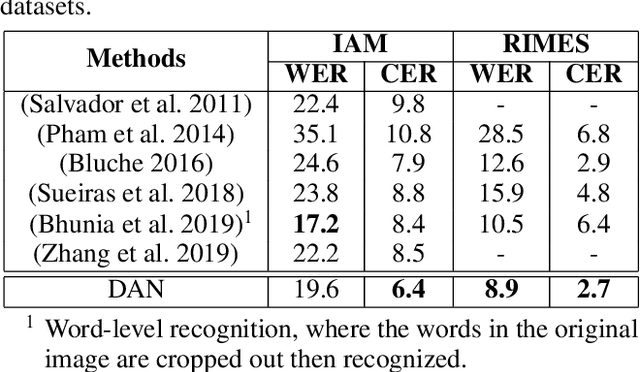
Text recognition has attracted considerable research interests because of its various applications. The cutting-edge text recognition methods are based on attention mechanisms. However, most of attention methods usually suffer from serious alignment problem due to its recurrency alignment operation, where the alignment relies on historical decoding results. To remedy this issue, we propose a decoupled attention network (DAN), which decouples the alignment operation from using historical decoding results. DAN is an effective, flexible and robust end-to-end text recognizer, which consists of three components: 1) a feature encoder that extracts visual features from the input image; 2) a convolutional alignment module that performs the alignment operation based on visual features from the encoder; and 3) a decoupled text decoder that makes final prediction by jointly using the feature map and attention maps. Experimental results show that DAN achieves state-of-the-art performance on multiple text recognition tasks, including offline handwritten text recognition and regular/irregular scene text recognition.
Adaptive Embedding Gate for Attention-Based Scene Text Recognition
Aug 26, 2019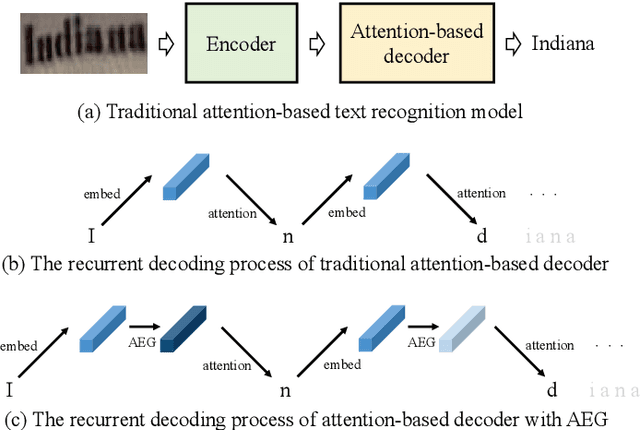
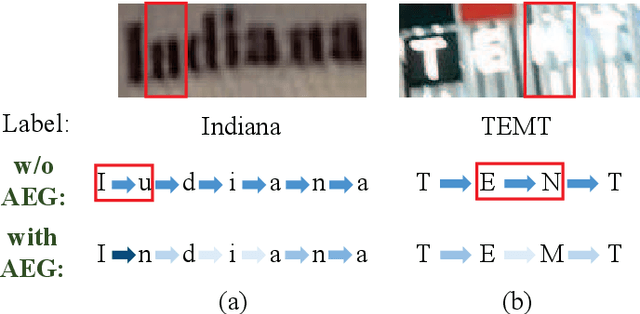
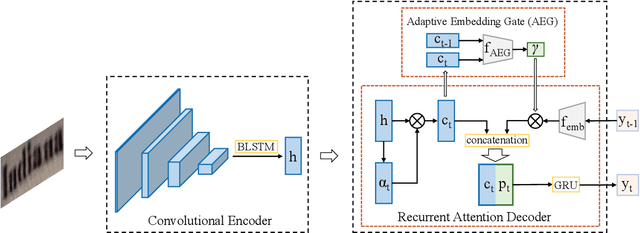

Scene text recognition has attracted particular research interest because it is a very challenging problem and has various applications. The most cutting-edge methods are attentional encoder-decoder frameworks that learn the alignment between the input image and output sequences. In particular, the decoder recurrently outputs predictions, using the prediction of the previous step as a guidance for every time step. In this study, we point out that the inappropriate use of previous predictions in existing attention mechanisms restricts the recognition performance and brings instability. To handle this problem, we propose a novel module, namely adaptive embedding gate(AEG). The proposed AEG focuses on introducing high-order character language models to attention mechanism by controlling the information transmission between adjacent characters. AEG is a flexible module and can be easily integrated into the state-of-the-art attentional methods. We evaluate its effectiveness as well as robustness on a number of standard benchmarks, including the IIIT$5$K, SVT, SVT-P, CUTE$80$, and ICDAR datasets. Experimental results demonstrate that AEG can significantly boost recognition performance and bring better robustness.