 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-view Granular-ball Contrastive Clustering
Dec 19, 2024



Previous multi-view contrastive learning methods typically operate at two scales: instance-level and cluster-level. Instance-level approaches construct positive and negative pairs based on sample correspondences, aiming to bring positive pairs closer and push negative pairs further apart in the latent space. Cluster-level methods focus on calculating cluster assignments for samples under each view and maximize view consensus by reducing distribution discrepancies, e.g., minimizing KL divergence or maximizing mutual information. However, these two types of methods either introduce false negatives, leading to reduced model discriminability, or overlook local structures and cannot measure relationships between clusters across views explicitly. To this end, we propose a method named Multi-view Granular-ball Contrastive Clustering (MGBCC). MGBCC segments the sample set into coarse-grained granular balls, and establishes associations between intra-view and cross-view granular balls. These associations are reinforced in a shared latent space, thereby achieving multi-granularity contrastive learning. Granular balls lie between instances and clusters, naturally preserving the local topological structure of the sample set. We conduct extensive experiments to validate the effectiveness of the proposed method.
StrucTexTv3: An Efficient Vision-Language Model for Text-rich Image Perception, Comprehension, and Beyond
Jun 04, 2024



Text-rich images have significant and extensive value, deeply integrated into various aspects of human life. Notably, both visual cues and linguistic symbols in text-rich images play crucial roles in information transmission but are accompanied by diverse challenges. Therefore, the efficient and effective understanding of text-rich images is a crucial litmus test for the capability of Vision-Language Models. We have crafted an efficient vision-language model, StrucTexTv3, tailored to tackle various intelligent tasks for text-rich images. The significant design of StrucTexTv3 is presented in the following aspects: Firstly, we adopt a combination of an effective multi-scale reduced visual transformer and a multi-granularity token sampler (MG-Sampler) as a visual token generator, successfully solving the challenges of high-resolution input and complex representation learning for text-rich images. Secondly, we enhance the perception and comprehension abilities of StrucTexTv3 through instruction learning, seamlessly integrating various text-oriented tasks into a unified framework. Thirdly, we have curated a comprehensive collection of high-quality text-rich images, abbreviated as TIM-30M, encompassing diverse scenarios like incidental scenes, office documents, web pages, and screenshots, thereby improving the robustness of our model. Our method achieved SOTA results in text-rich image perception tasks, and significantly improved performance in comprehension tasks. Among multimodal models with LLM decoder of approximately 1.8B parameters, it stands out as a leader, which also makes the deployment of edge devices feasible. In summary, the StrucTexTv3 model, featuring efficient structural design, outstanding performance, and broad adaptability, offers robust support for diverse intelligent application tasks involving text-rich images, thus exhibiting immense potential for widespread application.
GridFormer: Towards Accurate Table Structure Recognition via Grid Prediction
Sep 26, 2023



All tables can be represented as grids. Based on this observation, we propose GridFormer, a novel approach for interpreting unconstrained table structures by predicting the vertex and edge of a grid. First, we propose a flexible table representation in the form of an MXN grid. In this representation, the vertexes and edges of the grid store the localization and adjacency information of the table. Then, we introduce a DETR-style table structure recognizer to efficiently predict this multi-objective information of the grid in a single shot. Specifically, given a set of learned row and column queries, the recognizer directly outputs the vertexes and edges information of the corresponding rows and columns. Extensive experiments on five challenging benchmarks which include wired, wireless, multi-merge-cell, oriented, and distorted tables demonstrate the competitive performance of our model over other methods.
Recognition of Handwritten Chinese Text by Segmentation: A Segment-annotation-free Approach
Jul 29, 2022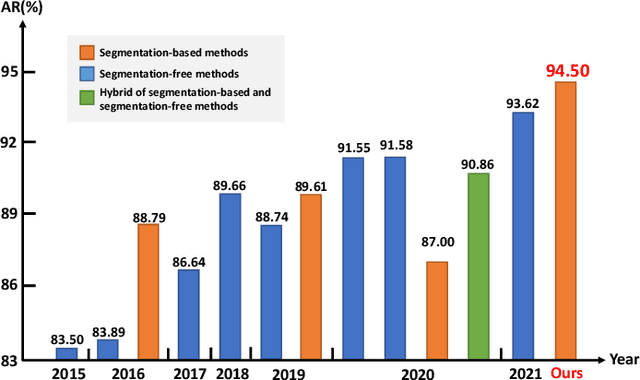
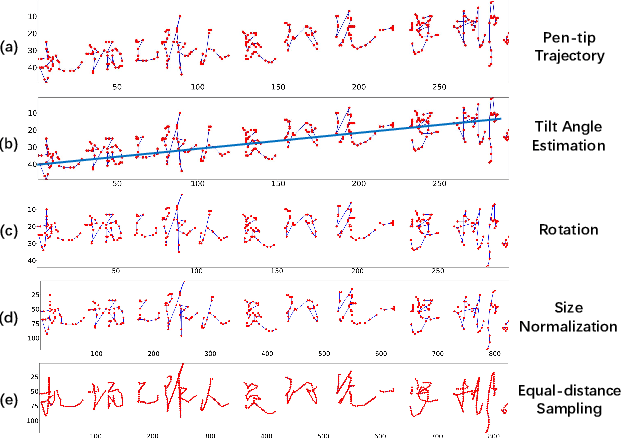


Online and offline handwritten Chinese text recognition (HTCR) has been studied for decades. Early methods adopted oversegmentation-based strategies but suffered from low speed, insufficient accuracy, and high cost of character segmentation annotations. Recently, segmentation-free methods based on connectionist temporal classification (CTC) and attention mechanism, have dominated the field of HCTR. However, people actually read text character by character, especially for ideograms such as Chinese. This raises the question: are segmentation-free strategies really the best solution to HCTR? To explore this issue, we propose a new segmentation-based method for recognizing handwritten Chinese text that is implemented using a simple yet efficient fully convolutional network. A novel weakly supervised learning method is proposed to enable the network to be trained using only transcript annotations; thus, the expensive character segmentation annotations required by previous segmentation-based methods can be avoided. Owing to the lack of context modeling in fully convolutional networks, we propose a contextual regularization method to integrate contextual information into the network during the training stage, which can further improve the recognition performance. Extensive experiments conducted on four widely used benchmarks, namely CASIA-HWDB, CASIA-OLHWDB, ICDAR2013, and SCUT-HCCDoc, show that our method significantly surpasses existing methods on both online and offline HCTR, and exhibits a considerably higher inference speed than CTC/attention-based approaches.
Look Closer to Supervise Better: One-Shot Font Generation via Component-Based Discriminator
Apr 30, 2022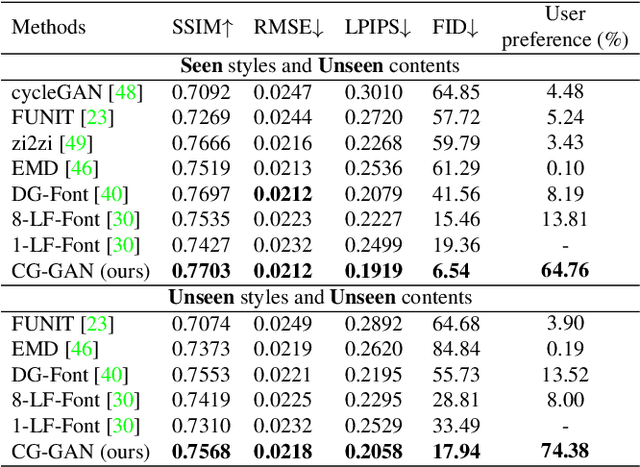
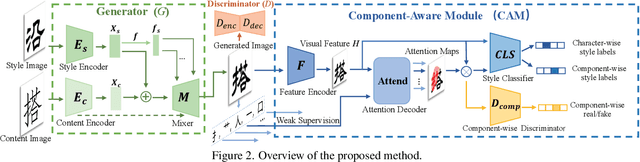


Automatic font generation remains a challenging research issue due to the large amounts of characters with complicated structures. Typically, only a few samples can serve as the style/content reference (termed few-shot learning), which further increases the difficulty to preserve local style patterns or detailed glyph structures. We investigate the drawbacks of previous studies and find that a coarse-grained discriminator is insufficient for supervising a font generator. To this end, we propose a novel Component-Aware Module (CAM), which supervises the generator to decouple content and style at a more fine-grained level, \textit{i.e.}, the component level. Different from previous studies struggling to increase the complexity of generators, we aim to perform more effective supervision for a relatively simple generator to achieve its full potential, which is a brand new perspective for font generation. The whole framework achieves remarkable results by coupling component-level supervision with adversarial learning, hence we call it Component-Guided GAN, shortly CG-GAN. Extensive experiments show that our approach outperforms state-of-the-art one-shot font generation methods. Furthermore, it can be applied to handwritten word synthesis and scene text image editing, suggesting the generalization of our approach.
Tag, Copy or Predict: A Unified Weakly-Supervised Learning Framework for Visual Information Extraction using Sequences
Jun 20, 2021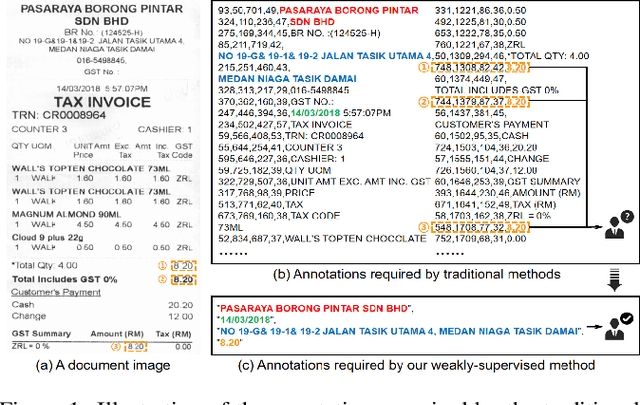
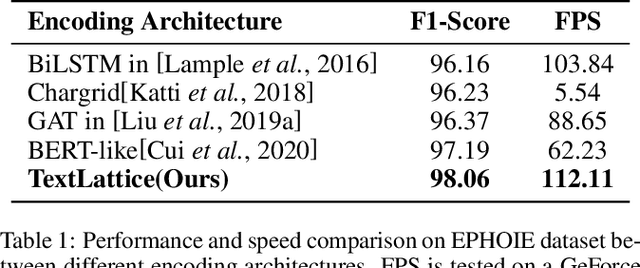
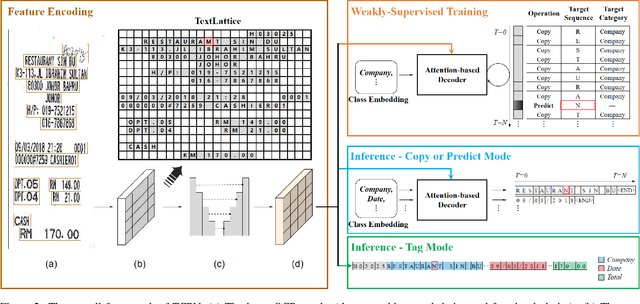

Visual information extraction (VIE) has attracted increasing attention in recent years. The existing methods usually first organized optical character recognition (OCR) results into plain texts and then utilized token-level entity annotations as supervision to train a sequence tagging model. However, it expends great annotation costs and may be exposed to label confusion, and the OCR errors will also significantly affect the final performance. In this paper, we propose a unified weakly-supervised learning framework called TCPN (Tag, Copy or Predict Network), which introduces 1) an efficient encoder to simultaneously model the semantic and layout information in 2D OCR results; 2) a weakly-supervised training strategy that utilizes only key information sequences as supervision; and 3) a flexible and switchable decoder which contains two inference modes: one (Copy or Predict Mode) is to output key information sequences of different categories by copying a token from the input or predicting one in each time step, and the other (Tag Mode) is to directly tag the input sequence in a single forward pass. Our method shows new state-of-the-art performance on several public benchmarks, which fully proves its effectiveness.
Towards an efficient framework for Data Extraction from Chart Images
May 05, 2021
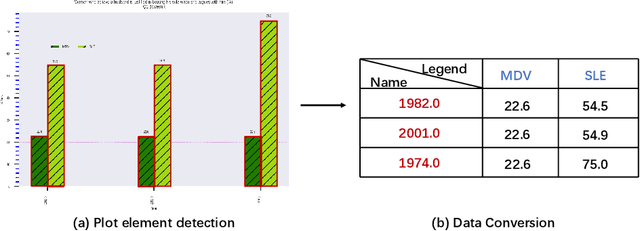
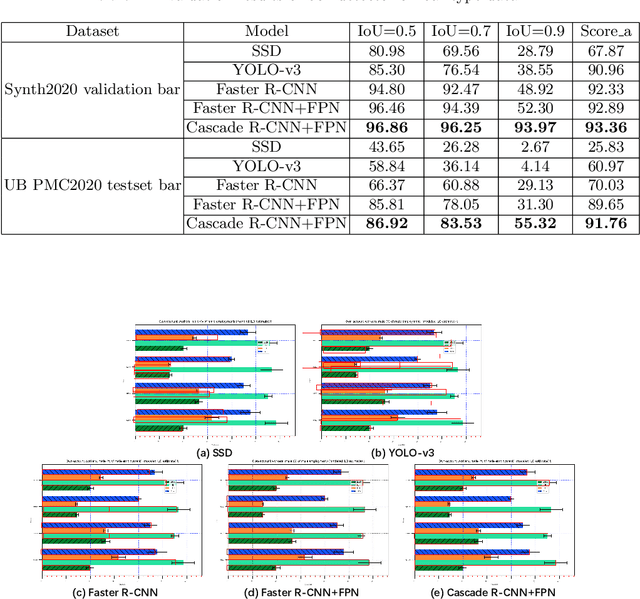
In this paper, we fill the research gap by adopting state-of-the-art computer vision techniques for the data extraction stage in a data mining system. As shown in Fig.1, this stage contains two subtasks, namely, plot element detection and data conversion. For building a robust box detector, we comprehensively compare different deep learning-based methods and find a suitable method to detect box with high precision. For building a robust point detector, a fully convolutional network with feature fusion module is adopted, which can distinguish close points compared to traditional methods. The proposed system can effectively handle various chart data without making heuristic assumptions. For data conversion, we translate the detected element into data with semantic value. A network is proposed to measure feature similarities between legends and detected elements in the legend matching phase. Furthermore, we provide a baseline on the competition of Harvesting raw tables from Infographics. Some key factors have been found to improve the performance of each stage. Experimental results demonstrate the effectiveness of the proposed system.
Joint Layout Analysis, Character Detection and Recognition for Historical Document Digitization
Jul 14, 2020
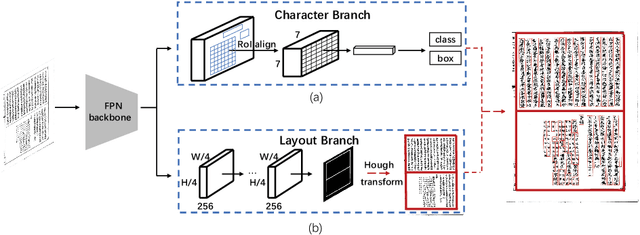
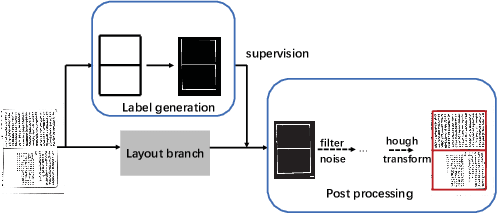
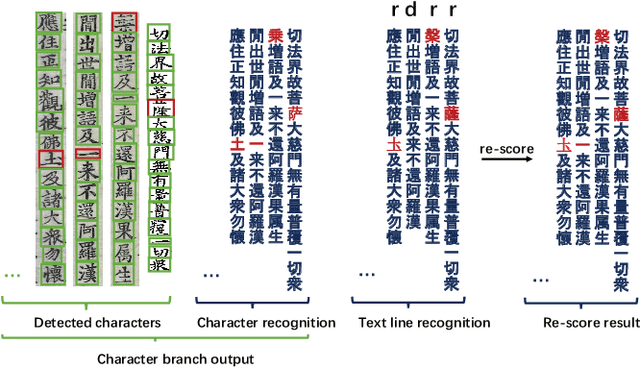
In this paper, we propose an end-to-end trainable framework for restoring historical documents content that follows the correct reading order. In this framework, two branches named character branch and layout branch are added behind the feature extraction network. The character branch localizes individual characters in a document image and recognizes them simultaneously. Then we adopt a post-processing method to group them into text lines. The layout branch based on fully convolutional network outputs a binary mask. We then use Hough transform for line detection on the binary mask and combine character results with the layout information to restore document content. These two branches can be trained in parallel and are easy to train. Furthermore, we propose a re-score mechanism to minimize recognition error. Experiment results on the extended Chinese historical document MTHv2 dataset demonstrate the effectiveness of the proposed framework.