 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTag, Copy or Predict: A Unified Weakly-Supervised Learning Framework for Visual Information Extraction using Sequences
Jun 20, 2021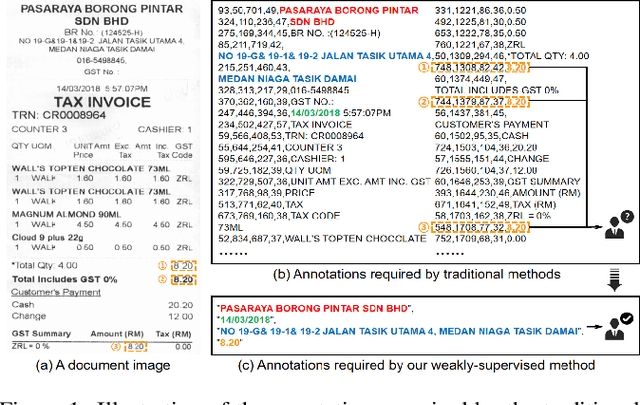
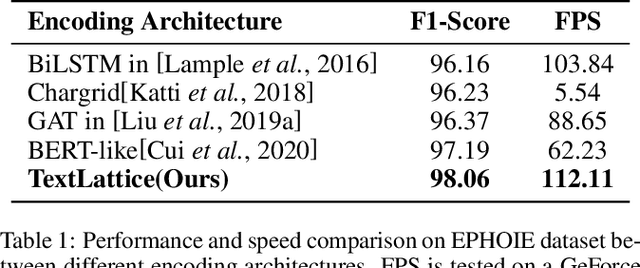
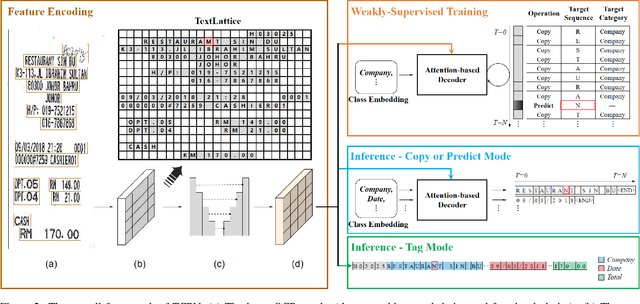

Visual information extraction (VIE) has attracted increasing attention in recent years. The existing methods usually first organized optical character recognition (OCR) results into plain texts and then utilized token-level entity annotations as supervision to train a sequence tagging model. However, it expends great annotation costs and may be exposed to label confusion, and the OCR errors will also significantly affect the final performance. In this paper, we propose a unified weakly-supervised learning framework called TCPN (Tag, Copy or Predict Network), which introduces 1) an efficient encoder to simultaneously model the semantic and layout information in 2D OCR results; 2) a weakly-supervised training strategy that utilizes only key information sequences as supervision; and 3) a flexible and switchable decoder which contains two inference modes: one (Copy or Predict Mode) is to output key information sequences of different categories by copying a token from the input or predicting one in each time step, and the other (Tag Mode) is to directly tag the input sequence in a single forward pass. Our method shows new state-of-the-art performance on several public benchmarks, which fully proves its effectiveness.
Towards an efficient framework for Data Extraction from Chart Images
May 05, 2021
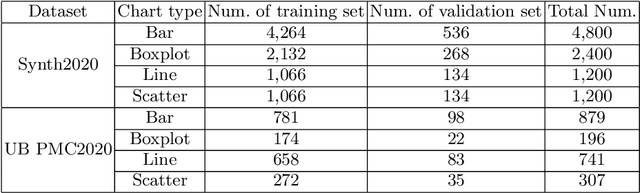
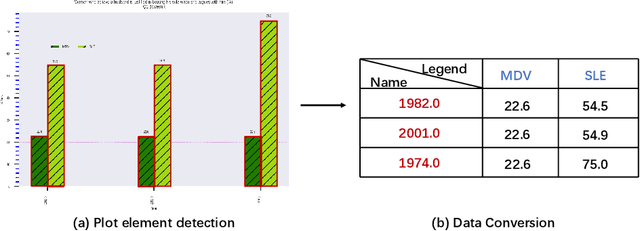
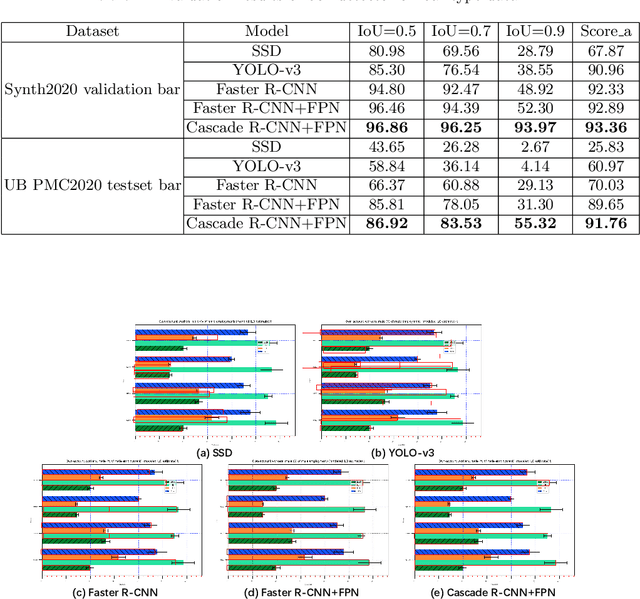
In this paper, we fill the research gap by adopting state-of-the-art computer vision techniques for the data extraction stage in a data mining system. As shown in Fig.1, this stage contains two subtasks, namely, plot element detection and data conversion. For building a robust box detector, we comprehensively compare different deep learning-based methods and find a suitable method to detect box with high precision. For building a robust point detector, a fully convolutional network with feature fusion module is adopted, which can distinguish close points compared to traditional methods. The proposed system can effectively handle various chart data without making heuristic assumptions. For data conversion, we translate the detected element into data with semantic value. A network is proposed to measure feature similarities between legends and detected elements in the legend matching phase. Furthermore, we provide a baseline on the competition of Harvesting raw tables from Infographics. Some key factors have been found to improve the performance of each stage. Experimental results demonstrate the effectiveness of the proposed system.
Fingertip in the Eye: A cascaded CNN pipeline for the real-time fingertip detection in egocentric videos
Nov 07, 2015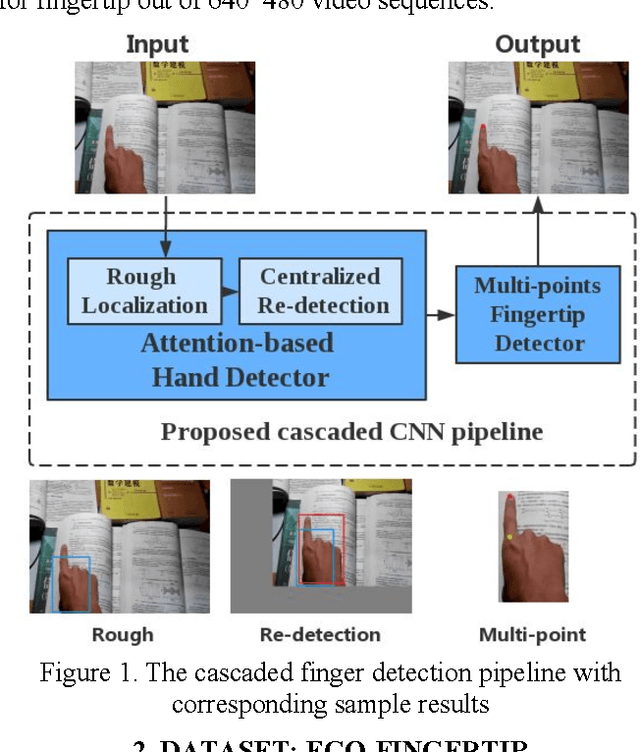

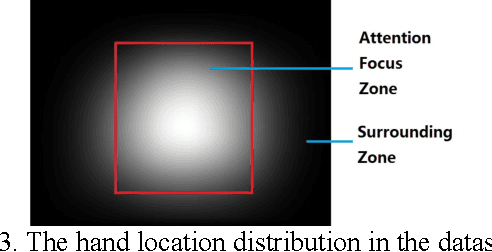
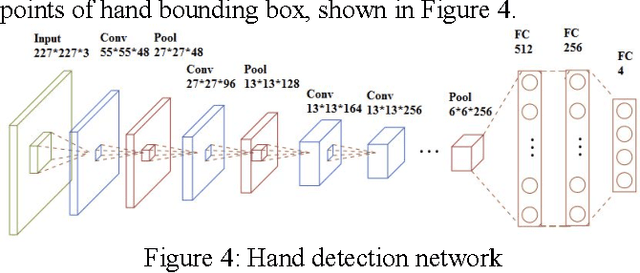
We introduce a new pipeline for hand localization and fingertip detection. For RGB images captured from an egocentric vision mobile camera, hand and fingertip detection remains a challenging problem due to factors like background complexity and hand shape variety. To address these issues accurately and robustly, we build a large scale dataset named Ego-Fingertip and propose a bi-level cascaded pipeline of convolutional neural networks, namely, Attention-based Hand Detector as well as Multi-point Fingertip Detector. The proposed method significantly tackles challenges and achieves satisfactorily accurate prediction and real-time performance compared to previous hand and fingertip detection methods.