 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecognition of Handwritten Chinese Text by Segmentation: A Segment-annotation-free Approach
Jul 29, 2022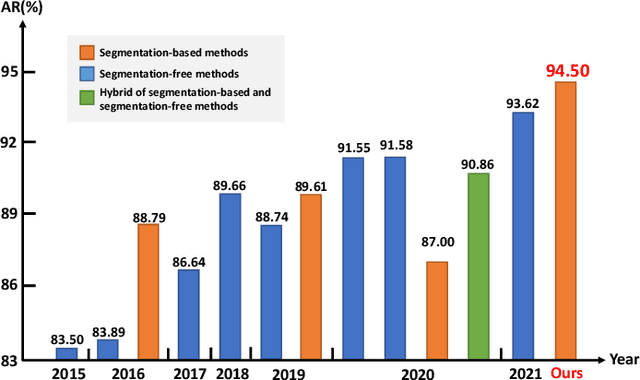
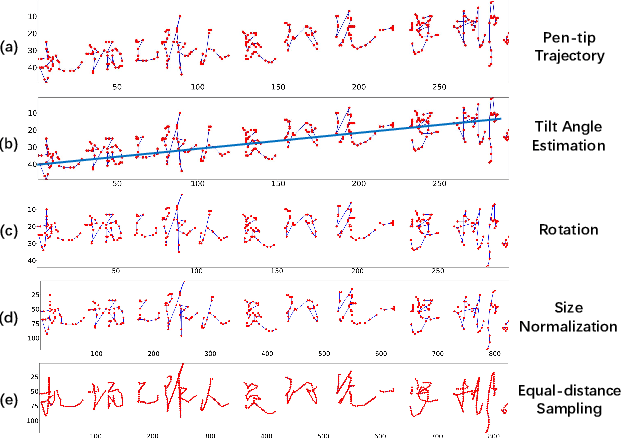


Online and offline handwritten Chinese text recognition (HTCR) has been studied for decades. Early methods adopted oversegmentation-based strategies but suffered from low speed, insufficient accuracy, and high cost of character segmentation annotations. Recently, segmentation-free methods based on connectionist temporal classification (CTC) and attention mechanism, have dominated the field of HCTR. However, people actually read text character by character, especially for ideograms such as Chinese. This raises the question: are segmentation-free strategies really the best solution to HCTR? To explore this issue, we propose a new segmentation-based method for recognizing handwritten Chinese text that is implemented using a simple yet efficient fully convolutional network. A novel weakly supervised learning method is proposed to enable the network to be trained using only transcript annotations; thus, the expensive character segmentation annotations required by previous segmentation-based methods can be avoided. Owing to the lack of context modeling in fully convolutional networks, we propose a contextual regularization method to integrate contextual information into the network during the training stage, which can further improve the recognition performance. Extensive experiments conducted on four widely used benchmarks, namely CASIA-HWDB, CASIA-OLHWDB, ICDAR2013, and SCUT-HCCDoc, show that our method significantly surpasses existing methods on both online and offline HCTR, and exhibits a considerably higher inference speed than CTC/attention-based approaches.
Towards an efficient framework for Data Extraction from Chart Images
May 05, 2021
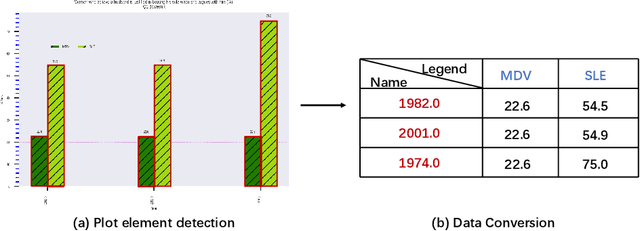
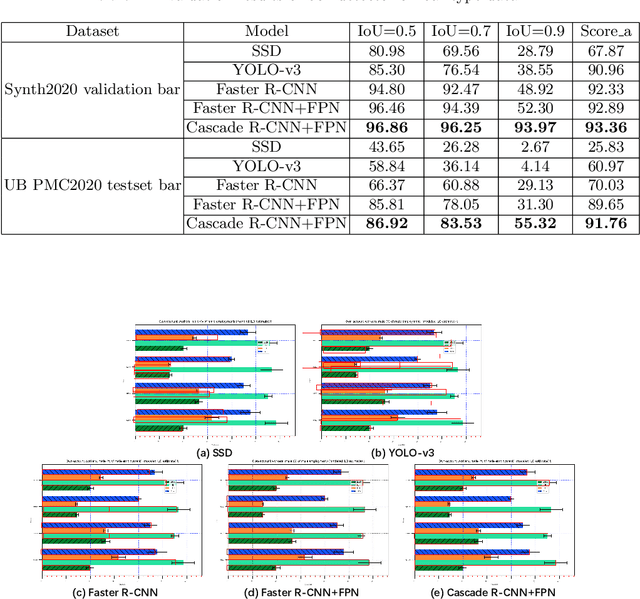
In this paper, we fill the research gap by adopting state-of-the-art computer vision techniques for the data extraction stage in a data mining system. As shown in Fig.1, this stage contains two subtasks, namely, plot element detection and data conversion. For building a robust box detector, we comprehensively compare different deep learning-based methods and find a suitable method to detect box with high precision. For building a robust point detector, a fully convolutional network with feature fusion module is adopted, which can distinguish close points compared to traditional methods. The proposed system can effectively handle various chart data without making heuristic assumptions. For data conversion, we translate the detected element into data with semantic value. A network is proposed to measure feature similarities between legends and detected elements in the legend matching phase. Furthermore, we provide a baseline on the competition of Harvesting raw tables from Infographics. Some key factors have been found to improve the performance of each stage. Experimental results demonstrate the effectiveness of the proposed system.
Joint Layout Analysis, Character Detection and Recognition for Historical Document Digitization
Jul 14, 2020
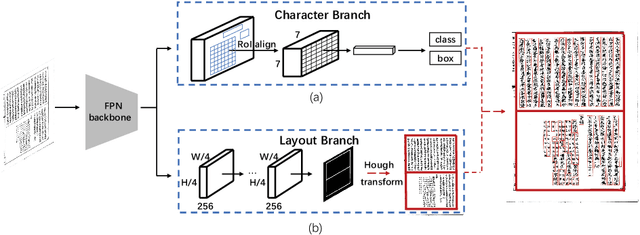
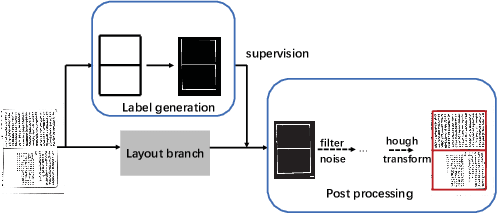
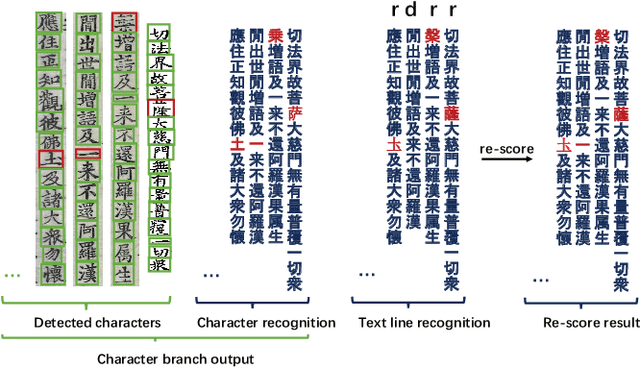
In this paper, we propose an end-to-end trainable framework for restoring historical documents content that follows the correct reading order. In this framework, two branches named character branch and layout branch are added behind the feature extraction network. The character branch localizes individual characters in a document image and recognizes them simultaneously. Then we adopt a post-processing method to group them into text lines. The layout branch based on fully convolutional network outputs a binary mask. We then use Hough transform for line detection on the binary mask and combine character results with the layout information to restore document content. These two branches can be trained in parallel and are easy to train. Furthermore, we propose a re-score mechanism to minimize recognition error. Experiment results on the extended Chinese historical document MTHv2 dataset demonstrate the effectiveness of the proposed framework.